

In this post you will find the authors' solutions for the problems and subproblems featured in the competition, as well as some bonus questions related to these tasks.
391A - Genetic Engineering
Note that we can consider each maximal sequence of identical characters independently, since there is no way to insert a character and affect more than one such sequence. Also, note that there are multiple ways to correct a single maximal sequence by inserting one character into it: we can either insert a different character somewhere in this sequence and divide it into two sequences of odd length (this is always possible for a sequence of even length), or even just add the same character in any point of this sequence, thus increasing its length by 1 and changing its parity.
Therefore, the answer to the problem is the number of maximal sequences of even length. One can find all such sequences in linear time. A pseudocode of the solution follows:
i = 1
ans = 0
while i <= length(s) do
end = length(s) + 1 // we will use this value if current sequence is the last in this string
for j = i + 1 .. length(s)
if s[j] <> s[i] then
end = j
break
// at this point, we have the next maximal sequence of identical characters between i and j-1, inclusive
if (j - i) mod 2 = 0 then
ans = ans + 1
i = j
Bonus: Alex decided to submit an almost one-line solution for this problem, which reminded me of shortest code competitions. I thought you might be interested in something similar, so here is Alex's solution to kick off (111 non-space chars):
#include<stdio.h>
main(){int x=-1,y=1,c,d=0;for(;10!=(c=getchar());d=c,y^=1)if(c-d)x+=y,y=1;printf("%d\n",x+y);}
391B - Word Folding
Let us describe the crucial observation necessary to solve this problem. Suppose that you have a character at some position i in the string and you want to fold the string in such a way that another character at position j > i is placed directly above the i-th character in the resulting structure. This is only possible if there is an even number of characters between i and j, and this is always possible in such case. In order to put the j-th character upon the i-th character, you would need to perform the fold exactly after position (i + j + 1) / 2. Thus, what the problem really asks for is "What is the longest sequence of indices you can choose such that they all contain the same letter and there is an even number of characters between each pair of consecutive indices in the sequence?". Note that "even number of characters between each consecutive pair" means that each index has different parity from the one before it.
Armed with the observation above, we can devise a simple greedy algorithm. First, let us choose the letter which the highest pile will consist of. That is, let's iterate from 'A' to 'Z'. For a fixed letter, there are two possibly optimal choices: either we begin with the leftmost even index which contains the corresponding letter, or we begin with the leftmost odd such index. Once we make this choice, the maximum sequence of indices becomes fixed; the next index in the optimal sequence is always the leftmost index to the right of the current one that contains the same letter and has different parity. Thus, there are at most 26 * 2 cases to consider and the answer for each case can be found in O(n) time. If the alphabet size A was an input parameter, the total algorithm complexity would be O(A * n).
Bonus: The initial version of the problem was slightly different, though we have abandoned it due to complicated problem statement. In that version, a pile could contain gaps or begin above the first level. Can you see why the solution to this problem is exactly the same?
391C3 - The Tournament
Since it was a question of multiple clarification requests, I will explain the third example here. The input is as follows:
5 2
2 10
2 10
1 1
3 1
3 1
The common misconception was that winning against three last opponents is sufficient to get in top 2. Note that winning only against the last three implies that Manao lost against the first two, so they'll have as many points as Manao and rank better than him. The optimal strategy is to win against one of the first two fighters, and win another two matches against fighters costing 1 unit of effort.
Subproblem C1.
As the constraints suggest, the intended solution here is brute force. Note that there are only 2n different possible scenarios, depending on which fight Manao wins and which he loses. Thus, we can generate all of these scenarios, compute the score that Manao will obtain as a result of it and what will the other contestants' new scores be, and determine what is the minimum total effort Manao needs for a scenario which gets him in top k.
How can we generate all scenarios? A natural way to do this is recursion: for each fight, we choose the outcome (win or loss) and recurse one level deeper, stopping when all match outcomes have been chosen and performing the evaluation. However, there is another way which is usually less time-consuming: bitmasks. If you are not familiar with using bitmasks, I recommend reading the old-but-never-outdated tutorial by bmerry and dimkadimon's Topcoder Cookbook recipe on iterating over subsets. This is a pseudocode showing how short a bitmask solution for this problem is:
ans = INFINITY
for(bitmask = 0; bitmask < 2**n; bitmask++)
int score = 0;
int effort = 0;
for(i = 0; i < n; i++)
if (bitTurnedOnIn(mask, i))
score = score + 1;
effort = effort + fighter[i].effort;
rank = n + 1;
for(int i = 0; i < n; i++)
if (fighter[i].score < score - 1 || fighter[i].score <= score && (bitTurnedOnIn(mask, i))
rank = rank - 1
if (rank <= k)
ans = min(ans, effort);
Subproblem C2.
This subtask could be solved with any reasonable polynomial algorithm. My solution was the following: iterate over the number of points P that Manao will have in the end. For each P, let us check whether it is possible to finish in top k having P points and what is the minimum effort required. This can be computed using dynamic programming: let F(i, j, k) be the minimum effort required to win k of the fights against the first i fighters and be ranked worse than j of them. I will not go into details of this solution, since there are many alternatives, and it is suboptimal anyway.
Subproblem C3.
Let us look deeper into what amount of points Manao might have if he finishes in top k. Since finishing in top k is the same as ranking better than at least n - k + 1 opponent, I will just assume from now on that he has to beat Q = n - k + 1 opponents. Let S(i) be the number of fighters that have i points before Manao joins the tournament. Then, if S(0) + S(1) + … + S(P) is less than Q, there is no way Manao can possibly rank better than Q opponents if he has score P in the end. So we have a lower bound on the score Manao will have in the end. On the other hand, note that if S(0) + S(1) + … + S(P - 2) is more than or equal to Q, then after scoring P points Manao will surely rank better than at least Q rivals. Thus, if P' is the minimum amount of points such that S(0) + S(1) + … + S(P' - 2) > = Q, there is no need to go for more points. Manao can just win the P' matches which require the least amount of effort from him. These observations leave us with only two interesting values of P — the first value when S(0) + S(1) + … + S(P) > = Q and that value plus 1.
What makes these cases more complicated is the fact that now it matters which matches does Manao win or lose. Suppose Manao wants to score P points. Let S' = S(0) + S(1) + … + S(P - 2). This is the count of opponents that are definitely ranked lower than Manao if he gets P points. Each of the fighters that has P - 1 or P points will rank better than Manao if Manao loses the corresponding fight and worse otherwise. Thus, Manao needs to win at least Q - S' of the fights against those opponents. Let's collect the efforts required to beat each of the opponents with score P - 1 or P into a list and collect the efforts required to beat each of the other opponents in another list. After we sort both lists, all we need to do is find the minimum sum of Q numbers such that at least Q - S' of them are from the first list and the rest are from the second.
The complexity of this algorithm is O(NlogN).
Bonus: Can you solve the problem in linear time?
391D2 - Supercollider
The goal in this problem was to find a pair of horizontal and vertical segments that forms the largest plus shape, truncating the ends of the segments so the plus is completely symmetric. A naive brute force O(n2) algorithm that simply tries all such pairs, computes the size of the plus for that pair, and prints the maximum is sufficient to solve the first subtask. For the second subtask, a faster algorithm is required. As with many problems related to computational geometry it is usually easiest to think of a sweepline algorithm to process a linear number of events, with each event requiring at most logarithmic time to process.
It turns out that one key insight suffices to pave the way for a relatively simple approach. If you transform the problem from a maximization problem “what is the largest plus?” into the decision problem “does there exist a plus of size k?” then your task is somewhat simplified at the cost of a O(lgW) factor to perform binary search to find the maximum valid k, where W is the bound on the coordinate values.
To answer the decision problem there is another trick that helps simplify your task. If you are interested in determining whether there exists a plus of size k, it suffices to simply truncate each segment by k on each end point and check whether any pair of segments intersects -- there is no need to check how long the arms of the plus are. For example, for each horizontal segment from (x, y) to (x + l, y), then you create a new segment from (x + k, y) to (x + l - k, y) if the segment still has non-negative length, and make a similar transformation for vertical segments. After transforming the segments, you can use a sweepline algorithm that keeps track of all vertical segments that intersect with a horizontal sweepline and use a binary indexed tree or binary search tree to determine whether the end points of each horizontal line the sweepline encounters straddles an active vertical line. Either of these data structures will suffice to clear the test cases for the second subproblem. Note that the full running time for this algorithm is 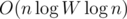 where n is the number of segments and W is the size of the largest segment.
where n is the number of segments and W is the size of the largest segment.
For the interested algorithms enthusiast, there exists a trickier algorithm that runs in  time and does not require binary searching for the largest plus size, though unfortunately it is difficult to distinguish this algorithm from the above one with the input constraints of a contest due to a higher constant factor overhead for this approach. The idea may be difficult to understand if you are not familiar with sweepline algorithms and augmented binary search trees, but I will sketch it here.
time and does not require binary searching for the largest plus size, though unfortunately it is difficult to distinguish this algorithm from the above one with the input constraints of a contest due to a higher constant factor overhead for this approach. The idea may be difficult to understand if you are not familiar with sweepline algorithms and augmented binary search trees, but I will sketch it here.
The idea is to make four separate sweepline passes over the input, with each pass looking for plusses in which the shortest arm of the plus is in a different direction, north, south, east, or west. For example, if we assume that the shortest arm of the plus is pointing north, we can use a diagonal sweepline that starts in the northwest corner and sweeps in the southeast direction (note that the line itself is drawn from the southwest to the northeast, but moves from the northwest to the southeast).
Each time this sweepline encounters the westmost endpoint of a horizontal line, it adds the segment into a binary search tree that is ordered from north to south. Each node in the search tree is further annotated with the sum of the x and y coordinates of the eastmost end point of the horizontal segment (i.e., if the eastmost point has coordinates (x, y), we store x + y) and stores the minimum such value in the subtree rooted at that node.
Now, when the northmost endpoint of a vertical segment is encountered by the sweepline, we search for the southmost horizontal segment whose y value is north of the midpoint of the vertical segment and whose (x + y)-coordinate sum is greater than the (x + y)-coordinate sum of the northmost point of the vertical segment.
Note that when the sweepline hits the northmost point of a vertical segment, it will only have added horizontal segments whose “west arm” is longer than the “north arm” and the condition on the (x + y)-coordinate of the eastmost endpoint of the horizontal line ensures that the “east arm” is longer than the north arm. The additional constraint that the searched y value in the tree is north of the midpoint adds the final constraint that the north arm is shorter than the south arm. Finding the southmost horizontal segment that satisfies these constraints is equivalent to finding the largest plus that uses this vertical segment and has the north arm as the shortest of the four arms. There are still some details to work out to get the binary search to operate correctly in O(lgn) time, but we leave these as an exercise.
391E2 - Three Trees
Subproblem 1.
Let us start with choosing a tree that will be the "middle tree", i.e., have connections to two other trees. Let n2 be the number of vertices in this tree and yi be its i-th vertex. Let n1 be the number of vertices and xi be the vertices of one of the other trees, and n2 be the number of vertices and zi be the vertices of another tree. Let d(i, j) be the distance between nodes i and j of the same some tree. Suppose we insert the edges (X, Y1) and (Z, Y2), where 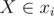 ,
, 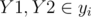 ,
, 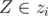 . The sum of distances between all pairs of points in the united tree can be divided into four components:
. The sum of distances between all pairs of points in the united tree can be divided into four components:
- Distances between {xi} and {yi}
- Distances between {yi} and {zi}
- Distances between pairs of vertices that were connected before we inserted the additional edges
- Distances between {xi} and {zi}
The first component is equal to sum(d(X, xi) + d(Y1, yi) + 1, xi = 1..n1, yi = 1..n2). Note that the summands are independent, so it can be broken into sum(d(X, xi), xi = 1..n1) * n2 + sum(d(Y1, yi), yi = 1..n2) * n1 + n1 * n2.
Similarly, the second component is equal to sum(d(Z, zi), zi = 1..n3) * n2 + sum(d(Y2, yi), yi = 1..n2) * n3 + n2 * n2.
The third component is simply a sum of pairwise distances in each of the trees and is a constant.
The fourth component is equal to sum(d(X, xi) + d(Y1, Y2) + d(Z, zi) + 2, xi = 1..n1, zi = 1..n3) = sum(d(X, xi), xi = 1..n1) * n3 + sum(d(Z, zi), zi = 1..n3) + d(Y1, Y2) * n1 * n3 + 2 * n1 * n3.
Let us compute the pairwise distances within each tree. This can be done with straightforward DFS/BFS and thus takes O(n12 + n22 + n32) time. Also, let's put D(v) = sum(d(v, i)) over all i from v's tree.
If we write together all the sums mentioned above, we will see that is always optimal to choose X such that it has the maximum D(X) over all vertices in its tree. The same argument holds for Z. Y1 and Y2 are both a part of two sums, so they cannot be chosen independently. Thus, let's iterate over all possible values of Y1 and Y2 and choose the pair that maximizes sum(d(Y2, yi), yi = 1..n2) * n3 + sum(d(Y1, yi), yi = 1..n2) * n1 + d(Y1, Y2) * n1 * n3 = D(Y2) * n3 + D(Y1) * n1 + d(Y1, Y2) * n1 * n3.
Since precalculation of distances takes square time, and choosing the optimal pair of (Y1, Y2) also takes square time, the resulting algorithm complexity is square.
Subproblem 2.
Please read the explanation for the previous problem if you have not done so yet.
I will assume that the reader is familiar with some tricks on trees, because it does not seem plausible to explain every step of the algorithm.
The core idea of the problem is the same as for the previous subproblem: we are maximizing a sum composed of several components, the only "hard" part of which is D(Y2) * n3 + D(Y1) * n1 + d(Y1, Y2) * n1 * n3. As we already know, the rest can be computed independently, which involves finding the sum of distances over all nodes in a tree and finding a node with maximum possible sum of distances to all other nodes, all in linear time.
To maximize D(Y2) * n3 + D(Y1) * n1 + d(Y1, Y2) * n1 * n3, let's perform some additional precalculation first. Let us root the middle tree (doesn't matter at which node). For each of the vertices, we need to assume that it is Y1 and find the two best candidates of being a Y2 from its subtree. This is easy if we know the Y2-candidates for each of the current vertex's children.
Having precalculated the Y2-candidates for each subtree, let us perform another traversal of the tree. This time, we will assume for each vertex that it is Y1, but will compute the optimal Y2 along the whole tree, not just current vertex's subtree. Obviously, for the root of the tree the optimal Y2 is the best Y2-candidate in the subtree of the root. When we start moving into the depth of the tree, we need to remember the current best Y2-candidate which is "left behind", i.e., is not within the subtree we just entered. This way, we will choose between the Y2-candidate left behind and the Y2-candidate within the current subtree and pick the best. Note that when we pass from a vertex P to a vertex V, the Y2-candidate left behind can only change to some vertex which is within P's subtree. We need to be careful and check that the Y2-candidate within P's subtree was not actually in V's subtree also, in which case the second-best Y2-candidate of P's subtree should be used for comparison against the one left behind.
391F3 - Stock Trading
This problem is a generalization of a common interview problem: given a time series of prices, find the single trade that results in the maximum gain. The best solution, in O(n) time, is an example of a very simple DP that simply scans the prices, keeps track of both the minimum price seen so far and the best gain so far, and computes the best gain achievable by selling on the current day by subtracting the running minimum from the current price. In this contest’s problem, the task is generalized to handling the case of k trades. Perhaps surprisingly, the optimal running time is still O(n) even when k is allowed to be chosen arbitrarily. To get to this optimal solution, let’s consider a series of increasingly fast algorithms for solving the problem.
Subproblem 1.
First, there is a very straightforward O(n2k) time DP solution in which, for each i and j we compute OPT(i, j), the optimal gain achievable by making j trades, with the sell order of the j-th trade occurring on day i or earlier. A natural recurrence relation is OPT(i, j) = max(OPT(i - 1, j), OPT(i’, j - 1) + p[i] - p[i’]foralli’ < i). Here, we are computing O(nk) optimal values, and each requires O(n) work to scan over all previous days to find the best solution for which the j-th trade ends exactly on day i. This solution is not fast enough to clear any of the three subproblems for this contest.
With a bit more work, we can speed up the O(n2k) DP to run in O(nk) time, which suffices to clear the first subproblem. It is important to realize that we do not need to consider all previous days when computing OPT(i, j) so that we can compute each such value in constant time. One way to achieve this is to create a slightly different optimization problem OPT2(i, j) that represents the maximum gain achievable with j trades during the first i - 1 days, minus the minimum price seen since the sell order for the j-th trade in OPT2(i, j). We also define MIN(i, j) to be the minimum price seen after the date of the last trade made in the solution for OPT2(i, j). With these definitions, we have the following recurrence: OPT2(i, j) = max(OPT2(i - 1, j), OPT2(i - 1, j) - p[i] + MIN(i - 1, j), OPT2(i - 1, j - 1) + p[i - 1] - p[i]). Case 1 represents using the same trades and minimum as OPT2(i - 1, j); case 2 represents using the same trades as OPT2(i - 1, j) but using p[i] as the new minimum; and case 3 represents using the optimal solution from OPT2(i - 1, j - 1) and selling for the j-th trade on day i - 1 for a gain of p[i - 1] with the new min of p[i] subtracted from the objective value. To compute MIN(i, j), we simply consider which case we fell into and set MIN(i, j) accordingly. In case 1, we set MIN(i, j) to MIN(i - 1, j); in case 2 we set MIN(i, j) = p[i]; and in case 3, we set MIN(i, j) = p[i]. The final solution, ignoring boundary cases, for OPT(n, k) is the max over all i of OPT2(i, k) + MIN(i, k).
Subproblem 2.
To clear the second subtask, we need additional insight about the problem so that we can achieve a sub-quadratic solution. The most important insight is that there is a way of solving this problem using a greedy algorithm if we make a transformation to the original problem. We begin by identifying the optimal solution that uses an unlimited number of trades. This produces a series of gains g1, …, gt where t is the number of trades in the optimal solution with an unbounded number of trades (this solution is easily found by identifying all possible shortest trades that produce a gain in linear time).
We interleave with these gains a series of “phantom-losses” l1, ..., lt - 1. The loss li represents the absolute value of the price difference between the price on the “sell day” for gi and the “buy day” for gi + 1. We let zt represent the value of the optimal solution for t trades (i.e., sum(gi) initially). Now, we look at the sequence St = s1, ..., s2t - 1 = g1, l1, g2, l2, ..., lt - 1, gt. We can compute zt - 1 from zt by finding the lowest value in St and eliminating this gain or loss by merging it with its neighbors (to handle s1 and s2t - 1, we can pad the ends with large values s0 and s2t so we can merge all candidates with two neighbors).
This leads naturally to a greedy algorithm in which we continually merge the lowest si (found using either a heap or a BST in  time for each iteration) with its neighbors until t = k. This merge consists of combining si - 1, si, andsi + 1 into one new value in the sequence that has value si - 1 - si + s{i + 1}, and zt - 1 = zt - si. Eliminating an si corresponding to a gain means skipping the trade and merging the neighboring losses into a new “phantom loss”. Eliminating an si corresponding to a loss means skipping a loss to merge two gains together into one trade of longer duration.
time for each iteration) with its neighbors until t = k. This merge consists of combining si - 1, si, andsi + 1 into one new value in the sequence that has value si - 1 - si + s{i + 1}, and zt - 1 = zt - si. Eliminating an si corresponding to a gain means skipping the trade and merging the neighboring losses into a new “phantom loss”. Eliminating an si corresponding to a loss means skipping a loss to merge two gains together into one trade of longer duration.
For example, if the sequence of stock prices is 4, 2, 3, 5, 4, 3, 7, 2, 6, 5, the optimal strategy with unlimited trades the following gains: 2 - > 5, 3 - > 7, 2 - > 6, so that g1 = 3, g2 = 4, and g3 = 4. We also have phantom losses of l1 = 2, l2 = 5. Thus, S3 = 3, 2, 4, 5, 4 and z3 = 11 is the profit from the optimal unlimited strategy. If k = 2, we need to execute one step in the greedy algorithm, and this corresponds to removing l1, which has value 2. This removal corresponds to lengthening the duration of the first trade to include the entire time interval from when the price first reaches 2 to when the price reaches 7. The resulting sequence S2 has the intervals 5, 5, 4, representing a gain, a phantom loss, and another gain. Thus, z2 = 9 is the optimal profit achievable with two trades. If we were to greedily iterate once more to find the optimal solution with k = 1, we would delete the last gain of 4, merging it with the preceding phantom loss of 5 and the following dummy phantom loss at the end of S_2 (i.e., S2t as described above). Merging such a gain with two phantom loss neighbors represents simply skipping a trade of low profit. From this, we see that that optimum profit from one trade is 5.
In the heat of a competition with open testing such as this one, one might simply guess that this works and hope that the tests pass, risking penalty time if the submission fails, but it turns out that this solution is indeed correct (proof TBD).
Subproblem 3.
An algorithm suffices to clear the second subproblem, and an extremely fast implementation may pass the tests for the third subproblem (for example, tourist had the only successful submission during the contest for F3 and used an algorithm that squeaked by the tests for F3, avoiding a timeout by 52 milliseconds -- many others timed out with solutions). However, to pass the tests by a more comfortable margin, one can implement an O(n) time algorithm.
The idea is as follows. Rather than greedily performing one merge in each iteration, we can perform many merges during each iteration. Note that whenever we perform a merge of 3 intervals into one, the resulting interval has a larger value than the central si interval that was targeted for removal if we take care only to merge local minima. Thus, suppose we need to perform m merges. We can find the m-th smallest value si * among the segments using linear time select, and then eliminate all segments whose value is less than si * . This can be accomplished by a linear scan across the segments, though we must be careful only to merge local minima so as to guarantee the same final result as using the greedy algorithm. This constraint of only removing local minima still allows us to remove all segments less than si * if we are careful with how we perform our scan. The result of such a scan is that the number of merges we need to perform falls by at least one third, from m to 2m / 3 (note that after m / 3 merges have been performed, it is possible that no segments remain whose value is less than si * ). Because the number of remaining merges falls by a constant factor in each iteration, we have only iterations to reach our target value.
Unfortunately, each pass requires O(n) time so this is still an algorithm. However, we can remedy this by deleting some trades that have large gains (or deleting some large phantom losses). Note that if there are two consecutive segments that have very large values, we will never perform a merge with one of the two of them as a central segment, so we can eliminate any streak of consecutive large segments and replace them with a single segment. How large is large enough that we can forget about the segments? We know that if we have m merges left to perform, we will never perform a merge on a segment whose value is greater than the 3m-th smallest segment. Further, when m is small relative to the remaining number of segments, we know that a constant fraction of segments will be involved in a streak of large values, so we can remove a constant fraction of the total number of segments from consideration. Thus, the total work required for each scan is geometrically decreasing so the total running time is O(n)!
After the contest, it has been brought to our attention that this problem has been studied academically. Here is the paper describing a linear-time algorithm.






