


608A - Saitama Destroys Hotel
Author: ed1d1a8d
Code: https://ideone.com/HiZd9g
The minimum amount of time required is the maximum value of ti + fi and s, where t_i and f_i are the time and the floor of the passenger respectively.
The initial observation that should be made for this problem is that only the latest passenger on each floor matters. So, we can ignore all passengers that aren't the latest passenger on each floor.
Now, assume there is only a passenger on floor s. Call this passenger a. The time taken for this passenger is clearly ta + fa (the time taken to wait for the passenger summed to the time taken for the elevator to reach the bottom).
Now, add in one passenger on a floor lower than s. Call this new passenger b. There are 2 possibilities for this passenger. Either the elevator reaches the passenger's floor after the passenger's time of arrival or the elevator reaches the passenger's floor before the passenger's time of arrival. For the first case, no time is added to the solution, and the solution remains ta + fa. For the second case, the passenger on floor s doesn't matter, and the time taken is tb + fb for the new passenger.
The only thing left is to determine whether the elevator reaches the new passenger before ti of the new passenger. It does so if ta + (fa - fb) > tb. Clearly this is equivalent to whether ta + fa > tb + fb. Thus, the solution is max of max(ta + fa, tb + fb).
A similar line of reasoning can be applied to the rest of the passengers. Thus, the solution is the maximum value of ti + fi and s.
608B - Hamming Distance Sum
Author: ed1d1a8d
Code: https://ideone.com/nmGbRe
We are trying to find 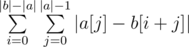 . Swapping the sums, we see that this is equivalent to
. Swapping the sums, we see that this is equivalent to 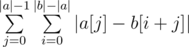 .
.
Summing up the answer in the naive fashion will give an O(n2) solution. However, notice that we can actually find 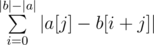 without going through each individual character. Rather, all we need is a frequency count of different characters. To obtain this frequency count, we can simply build prefix count arrays of all characters on b. Let's call this prefix count array F, where F[x][c] gives the number of occurrences of the character c in the prefix [0, x) of b. We can then write . as
without going through each individual character. Rather, all we need is a frequency count of different characters. To obtain this frequency count, we can simply build prefix count arrays of all characters on b. Let's call this prefix count array F, where F[x][c] gives the number of occurrences of the character c in the prefix [0, x) of b. We can then write . as 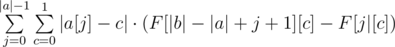 . This gives us a linear solution.
. This gives us a linear solution.
Time Complexity — O(|a| + |b|), Memory Complexity — O(|b|)
607A - Chain Reaction
Author: Chilli
Code: https://ideone.com/xOrFhv
It turns out that it is actually easier to compute the complement of the problem — the maximum number of objects not destroyed. We can subtract this from the total number of objects to obtain our final answer.
We can solve this problem using dynamic programming. Let dp[x] be the maximum number of objects not destroyed in the range [0, x] given that position x is unaffected by an explosion. We can compute dp[x] using the following recurrence:

Now, if we can place an object to the right of all objects with any power level, we can destroy some suffix of the (sorted list of) objects. The answer is thus the maximum number of destroyed objects objects given that we destroy some suffix of the objects first. This can be easily evaluated as
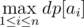
Since this is the complement of our answer, our final answer is actually
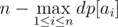
Time Complexity — O(max(ai)), Memory Complexity — O(max(ai))
607B - Zuma
Author: Amor727
Code: https://ideone.com/Aw1bSs
We use dp on contiguous ranges to calculate the answer. Let D[i][j] denote the number of seconds it takes to collapse some range [i, j]. Let us work out a transition for this definition. Consider the left-most gemstone. This gemstone will either be destroyed individually or as part of a non-singular range. In the first case, we destroy the left-most gemstone and reduce to the subproblem [i + 1, j]. In the second case, notice that the left-most gemstone will match up with some gemstone to its right. We can iterate through every gemstone with the same color as the left-most (let k be the index of this matching gemstone) and reduce to two subproblems [i + 1, k - 1] and [k + 1, j]. We can reduce to the subproblem [i + 1, k - 1] because we can just remove gemstones i and k with the last removal of [i + 1, k - 1]. We must also make a special case for when the first two elements in a range are equal and consider the subproblem [i + 2, j].
Here is a formalization of the dp:
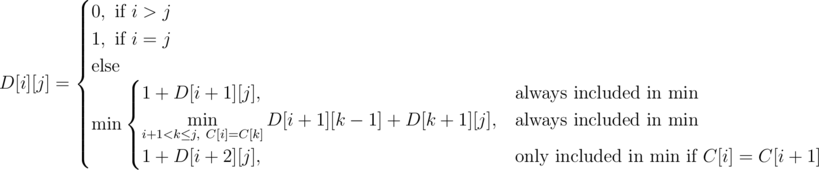
http://codeforces.com/blog/entry/22256?#comment-268876Why is this dp correct? Notice that the recursive version of our dp will come across the optimal solution in its search. Moreover, every path in the recursive search tree corresponds to some valid sequence of deletions. Since our dp only searches across valid deletions and will at some point come across the optimal sequence of deletions, the answer it produces will be optimal.
Time Complexity — O(n3), Space Complexity — O(n2)
607C - Marbles
Author: ed1d1a8d
Code: https://ideone.com/giyUNE
Define the reverse of a sequence as the sequence of moves needed to negate the movement. For example, EEE and WWW are reverses, and WWSSSEE and WWNNNEE are reverses. I claim is impossible to get both balls to the end if and only if some suffix of the first sequence is the reverse of a suffix of the second sequence.
Let us prove the forward case first, that if two suffixes are reverses, then it is impossible to get both balls to the end. Consider a sequence and its reverse, and note that they share the same geometric structure, except that the direction of travel is opposite. Now imagine laying the two grid paths over each other so that their reverse suffixes are laying on top of each other. It becomes apparent that in order to move both balls to their ends, they must cross over at some point within the confines of the suffix. However, this is impossible under the movement rules, as in order for this to happen, the two balls need to move in different directions at a single point in time, which is not allowed.
Now let us prove the backwards case: that if no suffixes are reverses, then it is possible for both balls to reach the end. There is a simple algorithm that achieves this goal, which is to move the first ball to its end, then move the second ball to its end, then move the first ball to its end, and so on. Let's denote each of these "move the x ball to its end" one step in the algorithm. After every step, the combined distance of both balls from the start is strictly increasing. Without loss of generality, consider a step where you move the first ball to the end, this increases the distance of the first ball by some value k. However, the second ball can move back at most k - 1 steps (only its a reverse sequence can move back k steps), so the minimum change in distance is + 1. Hence, at some point the combined distance will increase to 2(n - 1) and both balls will be at the end.
In order to check if suffixes are reverses of each other, we can take reverse the first sequence, and see if one of its prefixes matches a suffix of the second sequence. This can be done using string hashing or KMP in linear time.
Time Complexity — O(n), Memory Complexity — O(n)
607D - Power Tree
Author: ed1d1a8d
Code: https://ideone.com/pObeIV
Let's solve a restricted version of the problem where all queries are about the root. First however, let us define some notation. In this editorial, we will use d(x) to denote the number of children of vertex x. If there is an update involved, d(x) refers to the value prior to the update.
To deal these queries, notice that each vertex within the tree has some contribution ci to the root power. This contribution is an integer multiple mi of each vertex's value vi, such that ci = mi·vi If we sum the contributions of every vertex, we get the power of the root.
To deal with updates, notice that adding a vertex u to a leaf p scales the multiplier of every vertex in p's subtree by a factor of 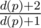 . As for the contribution of u, notice that mu = mp.
. As for the contribution of u, notice that mu = mp.
Now, in order to handle both queries and updates efficiently, we need a fast way to sum all contributions, a way to scale contributions in a subtree, and a way to add new vertices. This sounds like a job for ... a segment tree!
We all know segment trees hate insertions, so instead of inserting new vertices, we pre-build the tree with initial values 0, updating values instead of inserting new vertices. In order to efficiently support subtree modification, we construct a segment tree on the preorder walk of the tree, so that every subtree corresponds to a contiguous segment within the segment tree. This segment tree will store the contributions of each vertex and needs to support range-sum-query, range-multiply-update, and point-update (updating a single element). The details of implementing such a segment tree and are left as an exercise to the reader.
Armed with this segment tree, queries become a single range-sum. Scaling the contribution in a subtree becomes a range-multiply (we don't need to worry about multiplying un-added vertices because they are set to 0). And adding a new vertex becomes a range-sum-query to retrieve the contribution of the parent, and then a point-set to set the contribution of the added vertex.
Finally, to solve the full version of the problem, notice that the power of a non-root vertex w is a scaled down range sum in the segment tree. The value of the scale is 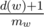 , the proof of which is left as an exercise to the reader.
, the proof of which is left as an exercise to the reader.
Time Complexity — 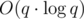 , Space Complexity — O(q)
, Space Complexity — O(q)
607E - Cross Sum
Author: GlebsHP
Code: https://ideone.com/Di8gnU
The problem boils down to summing the k closest intersections to a given query point.
We binary search on the distance d of kth farthest point. For a given distance d, the number of points within distance d of our query point is equivalent to the number of pairwise intersections that lie within a circle of radius d centered at our query point. To count the number of intersections, we can find the intersection points of the lines on the circle and sort them. Two lines which intersect will have overlapping intersection points on the circle (i.e. of the form ABAB where As and Bs are the intersection points of two lines). Counting the number of intersections can be done by DP.
Once we have d, we once again draw a circle of size d but this time we loop through all points in O(k) instead of counting the number of points.
It may happen that there are I < k intersections inside the circle of radius d but also I' > k inside a circle of radius d + ε. In this case, we should calculate the answer for d and add d(k - I).
Time Complexity — 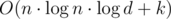 , Space Complexity — O(n)
, Space Complexity — O(n)







Who else think div 2 c was lot easier than div2 b?
Exactly.
I think i misunderstood the problem div2 c. Can anyone explain why the answer for this test case is 4 rather than 2 :
7
1 1
2 1
3 1
4 1
5 1
6 6
7 7
Maybe I am late but... A possible solution would be set a beacon at position 8 with power 2, thus the activation order will be like this, activate beacon at position 8 destroy beacons at position 7 and 6, activate beacon at position 5 destroy beacon at position 4, activate beacon at position 3 destroy beacon at position 2, activate beacon at position 1, done 4 beacons were destroyed.
Thanks for the clarification, its strange that for so many hours i was misunderstanding the problem, as a bomb at x position and radius r can only destroy a bomb at position x-r.
How come brute-force solutions like the one mentioned in this comment pass system test in problem D?
It looks to me such things happen when:
@writers: there's no harm in adding more solutions to polygon. Actually, it's the other way around: there should be at least one brute-force solution in polygon for problems where a slow but obvious solution exist. I'm pretty sure such solution was implemented by writers at least to check correctness of the intended solution.
Well, I hope this contest won't be unrated because of it. Actually, new sys-tests can be added and all solutions can be re-judged.
I don't remember any cases when contests were unrated because of weak tests :) I'm just wondering how this could happen and how to prevent it in future.
Yes this was very bad on our part. We had a brute force solution https://ideone.com/8tvGco but it wasn't good enough. I handled the test data for this problem and made the mistake of randomly generating queries, when I should have limited them to upper nodes in the tree. Sorry for the mistake, I'll be more diligent in the future.
What are you going to do now?
I hope you are not going to make it unrated (please do not) :)
I've added some stronger tests and rejudged the problemset submissions.
The contest is not rejudged.
I think tonynater meant the submissions made after the end of the contest, in the problemset.
Then that does not solve the problem.
Yes, sorry. We messed up on generating the test cases for this problem. We assumed that randomly generating queries would be good enough, but as it turns out it isn't. We'll be more cognizant of this in future contests.
Hahaha, it's funny that in the explanation of the Div1B/Div2D — Zuma you are talking about marbles, then I saw the name of the next problem and I realized why xD [Now it's not funny anymore, but you can find what I'm talking about in the history of changes].
I liked the problems, and also the editorial has nice explanations, so congratulations!
I am getting WA for DIV2 B . Please help. Stuck for long. Link to solution
Thanks in advance.
Div2B can be solved without prefix arrays, by simply maintaining a count of the ones, and adding 1 and removing one every time we shift the window. This takes O(1) space. AC code here: http://codeforces.com/contest/608/submission/14948271
How did you come up with the solution?
I've already asked that question in the main thread, but nobody answered. Hope, you'll reveal your thought process :)
Solution
I have tried my best to explain it. The main thing to observe is that hamming distance will be 1 for two pairs only i.e. ( 0 , 1 ) and ( 1 , 0 ). Now all we have to do is to count number of ones[] and zeros in array in b[] and find hamming distance accordingly.
PS — I know i am bad at teaching.
PS — I know i am bad at teaching.The more you practice, the better you become :)
Thanks a lot bro. At last i understand it. Very very thank you bro.
s1d_3 solution is more elegant. He has calculated number of ones for length l2 -l1 + 1 then traversed through whole array b simultaneously calculating the sum which will take O(1) space.
The contest is prepared by cyan and 2 purples, they said. The contest is going to be a tough one, they never said. :)
It seems that "relatively" low rated users tend to set tougher problems.
Sorry :( Hoped you still liked the problems!
Cheers, I appreciate your effort. Thank you :)
What is the range of the inner sum? Do you mean it is from
0to1(not fromatoz)?Yes you are absolutely right. Originally the problem was with strings with letters from a to z, which is why that's there. I forgot to update for the new version of the problem.
Is there any solution for div2 A without simulation of process ?
Simpler solution of div2 D
This works because a naiver O(N4) solution will be
But it can be easily reduced to O(N3) as mentioned above.
In div2 D, when the color at ith position is equal to the color at kth position, shouldn't the equation be D[i,j] = D[i+1,k-1] + D[k+1, j] + 1 instead of D[i,j] = D[i+1,k-1] + D[k+1, j] ? This is because, we need to add 1 step for removing the numbers at ith and kth position.
Form Editorial: " we can just remove gemstones i and k with the last removal of [i + 1, k - 1]. "
Suppose , dp[i+1][k-1] = 3 (means we need 3 steps to vanish this portion) ; among these steps the last(third) step is interesting. Because we can remove i and k in THIS (third) step . We do not need to perform an extra step. (hence , no adding of 1) Therefore dp[i][j] = dp[i+1][k-1] + dp[k+1][j] ;
For problem A, this was my solution and it worked absolutely fine on pc, yet it reported a compilation error on CF.
http://hastebin.com/owaguxahed.cpp
I checked it with an online ide, and it says bad::alloc or something. Where am I going wrong? I am using GNU C++ 5.1.0
I'm not sure why you have a compilation error. It seems to compile fine on CF for me. If you are checking it with an online IDE, are you sure have input? You're calling f[0] in the last line, which would explain your error.
However, your code does have other errors. Consider the case where you only have one passenger. Your code would print out that passenger's time and the maximum floor.
For ex: 1 1000 1 1
You would print 1001, when the current answer is 1000.
Thanks Chilli. I just figured out a blank code got submitted instead, and hence the compilation error, still don't know how it got repeatedly submitted like that. Frustrating...thanks again!
Please somebody help me. Division 2 Problem B. Here is my solution My solution. By the logic of this solution should work. But it gives an error at the 25 test.:(
Well it seems a little hard to understand your solution . BTW, you can refer to my solution which uses the same idea in the editorial and is a little neat Your text to link here...
Thank you wineColoredDays for the answer. You have a good solution, I'm understand your solution. It's a pity that I don't understand how can I fix my solution. It would be interesting:(. Good luck.
div2 E 607C — Marbles I can't understand the prove
Let us prove the forward case first, that if two suffixes are reverses, then it is impossible to get both balls to the end. Consider a sequence and its reverse, and note that they share the same geometric structure, except that the direction of travel is opposite. Now imagine laying the two grid paths over each other so that their reverse suffixes are laying on top of each other. It becomes apparent that in order to move both balls to their ends, they must cross over at some point within the confines of the suffix. However, this is impossible under the movement rules, as in order for this to happen, the two balls need to move in different directions at a single point in time, which is not allowed.
Consider the grid sequences determined by the two suffixes. Let's call them g0 → g1 → ... → gs and h0 → h1 → ... → hs. We don't care where these grid paths are located the plane — we only care about their shapes. This means we can translate the paths anywhere we want. Let's translate the paths so that g0 = hs. Since the sequences are reverses of each other, we have g1 = hs - 1, g2 = hs - 2 and in general gk = hs - k. So in summary, we can let g0 → ... → gs = hs → ... → h0.
Hence, moving a marble along g0 → ... → gs is the same as moving a marble along hs → ... → h0. So we have two marbles, one which must go along hs → ... → h0 and the other along h0 → ... → hs. In other words, we have two marbles moving along the same grid path in opposite directions. In order for the marbles to get to their respective ends however, they must at some point in time meet each other (i.e. be present on the same square). However, once they meet, they can never be separated. Since the destinations are different (path is at least length 2) and the marbles can't be separated, the marbles cannot reach their destinations.
I used rabin-karp algorithm approach for solving Div 2B. But I am unable to get AC. Can someone help me here? http://codeforces.com/contest/608/submission/14989553
Look at the input size for test case 9 and ask yourself IF the following part of your code is computationally feasible:
The value is to large to be stored. It overflows.
So is there any changes I could make so that my solution get accepted?
Sorry for being harsh,but there are lots of chances of improvement in your solution: ~~~~~
1 . Don't declare an array of size 2e5 inside main(), instead declare it globally.
2 . Why write such a complicated and probably wrong algorithm for a problem which can be much more easily solved.
3 . Let me explain the algo in editorial for you :
Let B = 1 0 0 1 0 1 1 A = 1 0 1 {this is the first alignment}
B = 1 0 0 1 0 1 1 A = 1 0 1 {this is the last alignment}We will have 3 more alignments starting at indices 2,3,4 (1-based). Note the alignment of two different characters like (0,1) and (1,0) gives 1, rest gives 0.
If you try to understand the problem, it is asking us to find the score for each character in A with each character it will align with in B. We then have to add the total score for each character in A, and that will be our answer.
Consider A[2] , it will align with B[2...6] and will have a total score of 2 . But, doing it in a naive way will give TLE. How to make it fast : We store the prefix-sum , which will give us the total number of 1's or 0's in some interval. Suppose, some A[i] aligns with B[l...r] . Now , the score for A[i] will be the total number of opposite characters in B[l...r], which we can get easily from our prefix-sums. See my code below : ~~~~~ `#include <bits/stdc++.h> using namespace std;
char a[200005]; char b[200005];
int one[200005]; int zero[200005];
int l1, l2; long long ans;
int main() { scanf("%s",a+1); scanf("%s",b+1);
l1 = strlen(a+1); l2 = strlen(b+1); for(int i = 1; i <= l2; ++i) { one[i] = (one[i-1] + (b[i] == '1')); zero[i] = (zero[i-1] + (b[i] == '0')); } for(int i = 1; i <= l1; ++i){ int r = l1 - i; if(a[i] == '0') ans += (one[l2 - r] - one[i-1]); if(a[i] == '1') ans += (zero[l2 - r] - zero[i-1]); } cout << ans << '\n'; return 0;}`
Can someone explain to me the recurrence relation of 607A — Chain Reaction? If a beacon is not affected by any explosion it should destroy the beacons within its range. So, how could the minimum destroyed beacon in that case is dp[x — b — 1] instead of dp[x — b — 1] + (no. of beacons it destroys).
Yes that is correct, I'll fix it in the tutorial.
Cool!
I actually didn't end up making your change. I instead changed the editorial to match the sample code. The current version is easier to implement.
Notice that the recursive version of our dp will come across the optimal solution in its search
This statement is true for any recursive DP. Does anyone have a more detailed explanation of why it is true in this specific case?
Notice that the recursive version of our dp will come across the optimal solution in its search
Ok, this was kind of a dumb explanation. The proof that the dp is correct is in state transition itself. It's kind of like induction (I've heard the comparison that dp is applied induction) — if the base case is correct and the inductive step (transition) is correct, then the result holds for all values.
As always, some editorials are not so friendly to newbies like me. I'll try to explain Div2B in a more intuitive and less mathematical/elegant way.
The naive algorithm takes string A and compare to all contiguous B's substrings with the same length as A's length.
Let A[i] be the i'th caracter of A. What are all characters in B that A[i] will be compared to? All characters in the range [i, size(B) — size(A) + i]. Ask in the comments if you have trouble with these limits.
Note that for each character comparision to calculate the Hamming Distance, the result is either 1 or 0.
If A[i] == 0: The comparision result will be 1 if and only if we're comparing A[i] to 1.
If A[i] == 1: The oposite.
Essentially, the question is: how many ones(or zeros) in the range [i, size(B) — size(A) + i]? is A[i] been compared to?
Let ones(a, b) and zeros(a, b) be the number of ones and zeros in the range [a, b]. Each A[i] will contribute to the final answer in the following way:
If A[i] == 0: ones(i, size(B) — size(A) + i)
If A[i] == 1: zeros(i, size(B) — size(A) + i)
The naive algorithm is naive because it answers each of theses queries in O(n). But you can answer those in O(1) after O(n) pre-calculation.
C++ code here
Thanks for the more detailed explanation. I was more focused on providing a concise (formally correct) solution in the editorial, so I might have skipped over some motivation. I think your explanation is a lot more approachable.
Thanks for a much more simple editorial marlonbymendes
You're welcome!
Could anyone please explain me how to calculate number of intersection points of given lines in the area of a circle of radius r in question cross sum? I am not able to figure out the purpose of fen array on https://ideone.com/Di8gnU.
Fen array refers to fenwick tree (AKA binary indexed tree). It allows you to do point updates and range sums in O(logn) time.
In our problem, we take an ordered list (by angle) of all intersection points on the circle, and assign them a label based on which line they belong to. A sample list might look like: ABCBAC (where difference characters represent different lines). In this list, we want to count the number of pairs of lines of the form XYXY (every pair like this will produce an intersection). In our case, there exist two pairs: ACAC and BCBC.
To count the number of such pairs, we do a line sweep, and keep track of "active" lines, which are lines which we have only seen a single endpoint for. We store these endpoints in a Fenwick tree based on their position in the list. Every time we remove a line from our active set, we query the Fenwick tree to see how many active points exist within the bounds of the line. Doing this for all lines will count the number of such pairs XYXY.
case 2:
7
1 1
2 1
3 1
4 1
5 1
6 1
7 1
output:
3
Explanation: For the second sample case, the minimum number of beacons destroyed is 3. One way to achieve this is to place a beacon at position 1337 with power level 42.
---Can anyone please help me out how this placing will give the above result?
We must place new beacon in such place, where it wont hurt any others. No matter: 1337 and 42 or 123456789 and 1234567. After this new beacon will be activated beacon with coordinate 7 and it will destroy 6. Then, will be activated 5 and destroyed 4. After that 3 and 2, and when we will activate 1 it wont destroy anything. In total, three beacons will be destroyed, and this is minimum as you can see. Firstly I have the same question as yours)
For problem D (Zuma) what if first three elements are equal?
This shouldn't matter. Try rereading the problem and sample cases carefully.
I think the solution to the Div1.B Zuma is incorrect. if a[i]==a[j] and a[i+1.....j-1] is not a palindrome but is composed of smaller palindromes then the solution code and the algorithm produces one less than the actual answer. I ran the following example: 8 1 5 3 5 4 3 4 1 Output: 2 Answer: 3
You can remove 5 3 5 in the first turn and all that remain (1 4 3 4 1) in the second turn.
Thanks
For problem Div2 C , if we are having a beacon at position x , then I was doing
dp[x]=max(dp[x-1],dp[x-b[x]-1]+1)but I was taking WA on testcase 11 here https://codeforces.com/contest/608/submission/57791208 . But when I saw editorial I found out that it should be dp[x]=dp[x-b[x]-1]+1 only. I am unable to understand it. As doing dp[x]=dp[x-b[x]-1]+1 is the case when beacon at position x is activated but what if the beacon at position x is not activated due to destruction so why not dp[x]=max(dp[x-1],dp[x-b[x]-1]+1) .For 607B, the editorial isn't really clear, so here is my approach.
My main idea behind the solution is if $$$arr[i] == arr[j]$$$ for any $$$1 <= i < j <= n$$$, we can combine these two elements with any palindromic contiguous subsequence in the range $$$[i + 1, j - 1]$$$, so we can just recur for this range.
And for every contagious subarray $$$[i, j]$$$, irrespective of whether or not $$$arr[i] = arr[j]$$$, we can just partition it into 2 subarrays $$$[i, k]$$$ and $$$[k + 1, j]$$$ for every $$$i <= k < j$$$ and solve for these two partitions separately.
Base cases are simply $$$return$$$ $$$1$$$ if $$$i == j$$$ (odd length case) and $$$j == i + 1$$$ $$$and$$$ $$$arr[i] == arr[j]$$$ (even length case) and $$$return$$$ $$$0$$$ for $$$i > j$$$.
My AC code
Hope this helps.
Thanks, very clean code.
For Div1 A, my approach is to use Dp to find minimum number of objects not destroyed. dp[i]= minimum number of objects not destroyed if I have only i elements.
- Let inc is the answer when ith object is destroyed by some element present in the right side.Therefore inc = 1 + dp[i-1]
- Let exc is the answer when ith object is not destroyed by some element present in the right side. Since ith element is not destroyed, when we will detonate it, it will destroy all elements within its left limit (a[i]-b[i]). Let's say it can destroy lbd number of elements on left side. Therefore exc = lbd + dp[i-lbd].
Now dp[i] = min{ inc , exc }. Finally return dp[n].
But my code is giving wrong answer in test case 11. Can anyone help me if there is something wrong in my logic or code?
Here is my code 64793135
Same here
Same with me. Don't know how to get past it.