


An intro would be also be kind of mainstream, but I'll still be...
Cutting to the chase
Rotations and balancing are kind of boring, but invariants are not. The nice thing about in looking for different solutions for the same problem is that you can find elegance in each of them. Maybe more importantly, it helps you develop backups when the first solution fails.
It is just the fact that sometimes to sell and start over is the right call. Of course, starting off with a small amount of one million dollars would do(couldn't help myself, people keep saying orange is the new black (now seriously: I say Donald, you say... Knuth) '
Binary search tree
The problems is to implement the basic operations of a (STL's)set:
- Insert
- Delete
- Search
- Lower bound
- Upper bound
And so on...
The obvious slow solution is as always a list. We will try to improve it and blah, blah, blah. This is not helpful at all.
The lower and upper bounds keeps our attention. For those to be executed we need an order. A hash or whatever structure that keeps things unsorted is really hard to manage around this operation. Is the structure was static, binary search would have done the job.
From this point, I see some approaches:
- leave gaps in a static structure
- work with chunks of data
- try to link data differently
- work around binary search and make a structure that does it dynamically(that goes to BST)
I will focus on the last one, but all of them lead to interesting stuff. You can try to look up skiplists, for example.
Now, how binary works is that it looks first at the middle and then at another middle and so on. What if our structure does the exact same thing? If you draw a decision tree for a binary search, the thing that happens is that you put the middle in the top, then the middle of the left interval in left, the middle of the right interval in right and so on.
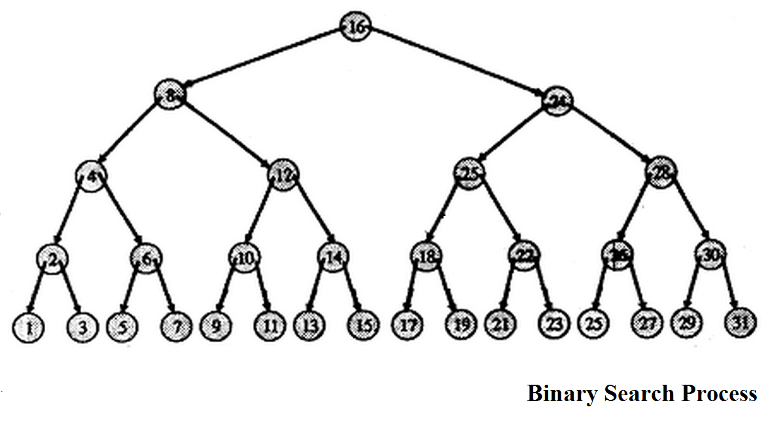
The cool things that we observe here are that:
- the tree is balanced
- all element in the left of a node are smaller that node and those in the right bigger
The BST is a binary tree that respects the second property.
Finding a structure that respects this property is not that hard(for example an ordered list works), but the thing that makes the decision tree above is the so called balance. Firstly, let's look why BST operations work good on average case and then try to add more invariants to make the structures good every time.
Searching
The search is straight forward. We look is the current node is what we are looking for, otherwise look in which part should we go. Here is some (stolen)code just to be clear:
function search(node, value) {
if (!node || node.value == value) {
return node;
} else {
if (node.value > value) {
return search(node.left, value);
} else {
return search(node.right, value);
}
}
}
Insert
Insertion goes just as the search. When we reach a null value, we insert a new node in the tree.
Node* insert(Node* node, int value) {
if (!node) {
return new Node(value);
} else if (key < node->value) {
node->left = insert(node->left, value);
} else
node->right = insert(node->right, value);
}
}
The reason we used a pointer for the node is that we want to actually modify the reference from the father of the new inserted leaf.
Delete
First search the tree to find the node that we have to delete. Now we have just to tackle the case when we have to delete the root. We need a node that we can put as a the new root. That is the biggest element from the left subtree. This is the rightmost element of the left subtree.
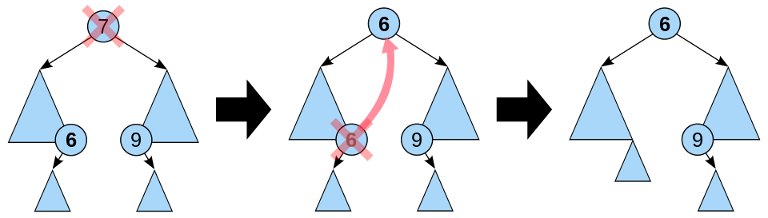
def binary_tree_delete(self, key):
if key < self.key:
self.left_child.binary_tree_delete(key)
elif key > self.key:
self.right_child.binary_tree_delete(key)
else: # delete the key here
if self.left_child and self.right_child:
successor = self.right_child.find_min()
self.key = successor.key
successor.binary_tree_delete(successor.key)
elif self.left_child:
self.replace_node_in_parent(self.left_child)
elif self.right_child:
self.replace_node_in_parent(self.right_child)
else: # this node has no children
self.replace_node_in_parent(None)
Treaps
Now, as I have mentioned, the BST is good on average. A (dirty) hack is just to try to somehow keep this randomness. If we change the order of the tasks we blow thing up. Instead we will add an additional value to each node(call it key) and some other invariant.
The treap is a BST and a heap. In order for us to go forward we have to define right and left rotations. Suppose I have the following tree with nodes P and Q and subtrees A, B and C. If B and C have depth S and A has depth S+1, then this operation will give decrease the depth of the whole tree. This operation and its reverse are called left and right rotations.
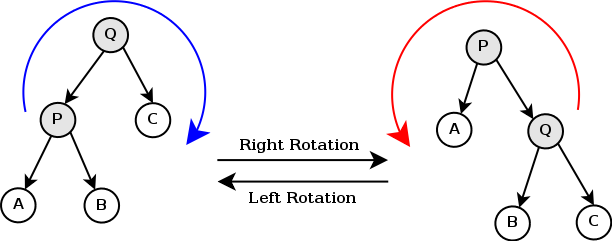
More formally, the treap has two invariants:
- All values in the left of a node are smaller the value of that node and those in the right are bigger.
- The keys of each node are bigger than the keys of the children.
Each time we insert a node, we will generate a random key and insert the node just as in the BST. While the node key is bigger then the one of the father, we keep rotating(left or right) to get the node up.
When we want to delete a node, we move it to the bottom of the tree by rotations and deleting a leaf is trivial. Also, note that during each step of any algorithm the only invariant that is broken(and tried to be fixed) is the heap one. The rotations preserve the order of the tree. This together with the depth reduction kind of tells us that this operation has the potential of keeping the tree balanced.
AVL trees
A random fact good to know is that just as you, average reader, the abbreviation is not special.(it is made out of the names of the guys who made the structure) Now, the left and right rotations can add or decrease the height of a tree if either of the lower subtrees has size bigger than the upper one. But if one is bigger you have to admit that some imbalance will still remain. Life is not perfect.
Fortunately, life is nice, so we can keep just a slight equilibrium. Let's denote the equilibrium factor as the difference of depth between the left and the right subtrees of a node. We want to keep the equilibrium factor between -1 and 1. Now, this will be broken if any node's equilibrium factor is -2 or 2. We always start with an equilibrated balance factor so we have to track only 4 cases. The following image shows gives quite an accurate description:
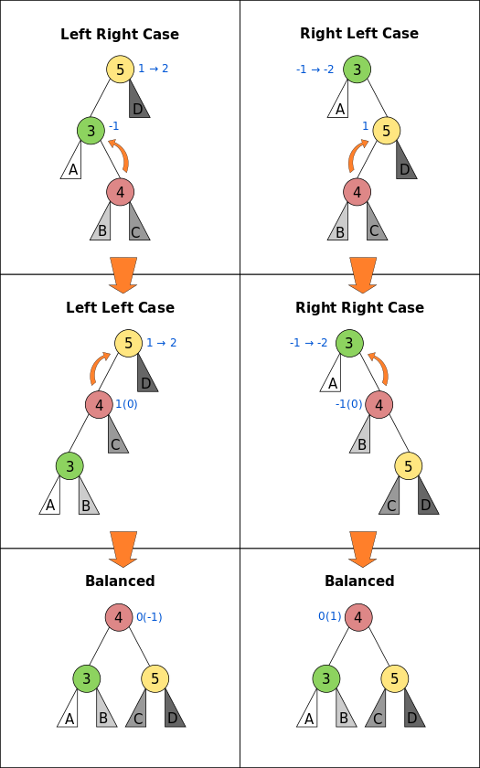
The equilibrium factor holds between -1 and 1 for each subtree A, B, C and D because it was held there before the current step. This procedure is called balancing and it will be called at each modification in the BST. This will yeld us a O(log N) complexity overall. In the case of the insertion, the first node the can be broken is the grandparent of the inserted node. But now we have to check for the grandparent's dad. Why? After the rotation the height of 3 or 5(last picture) node might have increased/decreased. Therefore the father of node 4 might find a factor increase/decrease of 1. The deletion will be treated in a similar manner.
Conclusion
I tried to put empathy on the different approaches to solve the same problem, not on the structures themselves. The first set of observations made in BST section can get us to other funny nice structures(skiplists for example). The balance can be achieved with different sets of invariants. A good example is the red-black tree.
PS
In fact I think the title was quite uninspired.
Thank you for reading and please state your opinion on my tutorial. (or, more specifically, on my writing style and how useful you find the material presented) Any suggestions for next tutorial are welcome.
You can find my previous article here.
Hope you enjoyed!






Nice, funny, gets the point across. Loving it! :D