


Разбор задач будет пополняться :)
Разбор задачи <<Развивающая игра>>
Это была самая простая задача из сложного набора. Для начала заметим, что можно решать данную задачу для каждого элемента ai отдельно. То есть, если мы фиксируем некоторое k, то вклад каждого ai в ответ можно считать отдельно.
Итак, фиксируем некоторое ai. Найдем максимально возможное j такое, что i + 2j ≤ n. Несложно видеть, что для всех k < i + 2j вклад ai в ответ будет равен ai. То есть нужно будет сделать ai ходов с переходом в ai + 2j. Далее найдем такое максимальное u, что 2j + 2u ≤ n. Заметим, что u < j. Также заметим, что для всех k таких, что i + 2j ≤ k < i + 2j + 2u вклад ai в ответ будет равен 2·ai. Далее найдем такое q, что i + 2j + 2u + 2q ≤ n.
Итак, для каждого элемента ai мы должны найти соответствующую последовательность степеней двойки. Очевидно, что общая сложность этого процесса 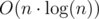 .
.
Теперь нам нужно считать ответ. Можно это делать, например, так: будем хранить массив bi. bi — это изменение ответа при переходе от i к i + 1. Этот массив строится тривиальным образом во время построения последовательностей степеней двоек. И потом по нему также нетрудно получить ответ. Итого, сложность решения составляет .
Разбор задачи “Жадные торговцы”
Для начала заметим, что торговцы будут платить только за те ребра, которые являются мостами (мостами называются рёбра неориентированного графа, при удалении которых количество компонент связности в графе увеличивается). Все другие ребра не подходят, так как при их удалении граф останется связным и путь между никакими двумя вершинами не исчезнет. Итак, первым этапом в решении является поиск мостов. Воспользуемся для этого известным алгоритмом, который работает за время O(n + m).
Далее заметим, что при удалении всех мостов граф разбивается на несколько компонент связности (возможно, одну). Построим новый граф, в котором полученные компоненты будут вершинами, а мосты исходного графа -- ребрами. Заметим, что этот граф является деревом. Его связность следует из того, что исходный граф связный, а отсутствие циклов в нём из того, что ребра в нём соответствуют мостам в исходном графе.
Заметим также, что число динариев, которое заплатит каждый из торговцев — это расстояние между некоторыми двумя вершинами в новом графе. Но так как этот граф является деревом, эти расстояния можно искать быстро, используя алгоритмы поиска LCA (наименьшего общего предка) для двух вершин. В данной задаче можно использовать один из самых простых алгоритмов поиска LCA, который осуществляет препроцессинг за время 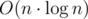 и обрабатывает один запрос за
и обрабатывает один запрос за  . Сложность такого решения составляет
. Сложность такого решения составляет 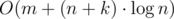 .
.
Отметим также, что решение можно несколько упростить. Построим дерево рекурсивного обхода исходного графа и назначим веса его ребрам. Вес, равный 1, будут иметь мосты, а все остальные ребра будут иметь вес, равный 0. Тогда после этих преобразований для нахождения ответа для одного торговца достаточно посчитать расстояние между двумя вершинами в построенном дереве рекурсивного обхода.
Разбор задачи <<Бобер и разрешение коллизий>>
Заметим, что при обходе ячеек с шагом m по модулю h множество ячеек хеш-таблицы разбивается на некоторое количество циклов, в каждом из которых одинаковое число элементов. При этом число циклов равно НОД(h, m), а число элементов в каждом из циклов -- h / НОД(h, m). Смысл циклов в том, что если объект имеет изначальное значение хэш-функции внутри одного цикла, то он будет добавлен в качестве элемента этого же цикла.
Теперь можно работать с каждым циклом отдельно. Нам необходимо эффективно добавлять/удалять элементы и при этом считать число коллизий. Для этого проще всего использовать для каждого цикла дерево отрезков или комбинацию из бинарного поиска и дерева Фенвика.
Cложность такого решения составляет 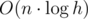 для дерева отрезков или
для дерева отрезков или 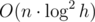 для бинарного поиска и дерева Фенвика. Заметим, что большой разницы в скорости работы этих решений нет за счет скрытых констант при подсчете сложности.
для бинарного поиска и дерева Фенвика. Заметим, что большой разницы в скорости работы этих решений нет за счет скрытых констант при подсчете сложности.
Разбор задачи <<Магические квадраты>>
Рассмотрим два подхода к решению данной задачи. Заметим, что для начала мы по исходным данным определяем значение s как сумму всех чисел, делённую на n. Далее будем пользоваться этим значением при решении.
Первый подход – переборный. Он основан на двух идеях:
- Можно в процессе перебора однозначно определять числа в некоторых квадратах. Например, если мы выбрали значения трех элементов главной диагонали, то выбор четвертого однозначен. Таким образом, мы сокращаем число вариантов в переборе.
- При поворотах и отражениях магический квадрат остается магическим квадратом. Если реализовать эти идеи аккуратно, то можно было решить данную задачу.
Второй подход основан на дискретной оптимизации. Рассмотрим следующий функционал качества: Q = |sum1 - s| + ... + |sumt - s|, где |x| — абсолютная величина x, t = 2 * n + 2, sum1, .., sumn — суммы в строках квадрата, sumn + 1, sum2n — суммы в столбцах, sumt - 1 — сумма элементов на главной диагонали, sumt - 1 — сумма элементов на побочной диагонали. Итак, мы должны найти такую перестановку, которая минимизирует данный функционал. Можно это делать так: выберем случайную перестановку. Будем пытаться делать в ней инверсии, которые улучшают исходный функционал качества, 1000 раз. Если в итоге Q = 0 — мы нашли ответ, если Q > 0 -- возьмём другую перестановку и начнём сначала. Даже такой тривиальный алгоритм оптимизации в данной задаче работает хорошо и проходит все тесты с большим запасом по времени.
Разбор задачи <<Задача от бобра — 2>>
Решение данной задачи можно разделить на две части:
- Удаление шума на изображении;
- Классификация фигур.
Для удаления шума можно было воспользоваться следующими методами:
a. Делаем следующие операции: сканируем изображение и по нему строим новое. Если некоторый черный пиксель имеет белых соседей, то мы его делаем белым. За несколько таких проходов мы избавляемся от почти всего шума на фоне. Потом делаем обратную операцию по замене былых пикселей на черные. Таким образом мы избавляется от шума внутри фигур.
Заметим, что после всех таких операций может остаться шум (в виде маленьких компонент черного цвета) и некоторые фигуры могут утратить связность. Обе эти проблемы решаются несложно: удаляем маленькие компоненты черного цвета и потом объединяем близкие компоненты черного цвета.
b. Можно было поступить проще. Выделяем компоненты черного цвета и отбрасываем те, которые имеют малый размер. Если внимательно посмотреть на тесты, то в реальности при равномерном распределении шума не возникает больших шумовых компонент черного и не теряется связность фигур. Однако предыдущий подход является существенно более надежным.
Самый простой способ для классификации фигур — это сравнение распределений расстояний от всех пикселей фигуры до центра каждой из фигур. Центр можно вычислить как среднее арифметическое координат всех точек фигуры. Сравнивать у распределений можно выборочные мат. ожидания и дисперсии.
Задача <<Репрезентативная выборка>>
Сразу приступим к полному решению задачи. Давайте отсортируем строки лексикографически и посчитаем lcp[i] -- длину наибольшего общего префикса строк i и i + 1. Несложно доказать, что наибольший общий префикс любых двух строк i и j теперь равен min (lcp[i], lcp[i + 1], ..., lcp[j - 1]) (подобное утверждение используется при использовании суффиксного массива). Это полезно.
Теперь применим метод динамического программирования. Сделаем такое ДП: F(i, j, k) — максимальный возможный ответ на задачу, если из строк с номерами i... j нужно выбрать ровно k строк. Переход следующий: найдём позицию p на отрезке i... j - 1 с минимальным lcp[p], тогда F(i, j, k) = maxq = 0... k(F(i, p, q) + F(p + 1, j, k - q) + q·(k - q)·lcp[p]), то есть предполагаем, что выбрано q из строк из i... p, k - q строк из p + 1... j, и для всех пар этих строк длина наибольшего общего префикса равна lcp[p] (это следует из утверждения в первом абзаце).
Такое решение достаточно для получения 50 баллов. Пока что кажется, что сложность этого решения порядка O(N4). Осталось показать, что на самом деле можно реализовать это решение так, чтобы его сложность оказалась равна O(N2).
Для начала заметим, что различных отрезков i... j, на которых нас интересуют значения функции F, на самом деле ровно 2N - 1, а не O(N2). Почему это так, можно понять из переходов нашего ДП. Отрезок 1... N разбивается на два отрезка 1... p и p + 1... N, каждый из этих отрезков разбивается ещё на два отрезка, и так далее; видим, что между позициями i и i + 1 для любого i ровно один раз за весь подсчёт ДП произойдёт <<разрез>>, и этот разрез породит два новых отрезка, на которых нас интересуют значения ДП. Отсюда и получаем оценку в 2N - 1 нужных отрезков, следовательно, наше решение уже имеет сложность не более O(N3).
Последнее и самое сложное — догадаться, что решение выше может иметь сложность O(N2). Например, реализовать его можно так. Давайте заведём рекурсивную функцию F(i, j), возвращающую массив длины j - i + 2 — собственно значения ДП F(i, j, k) (понятно, что нас интересуют только значения k из отрезка от 0 до j - i + 1). Внутри этой функции делаем следующее: найдём p, вызовем F(i, p) и F(p + 1, j), теперь переберём x от 0 до p - i + 1, переберём y от 0 до j - p и обновим значение F(i, j, x + y), если оно улучшилось (подробнее можно увидеть в авторском решении, там всё довольно прозрачно). Максимальное время работы функции F, вызванной на отрезке i... j длины j - i + 1 = N, можно записать как T(N) = maxX = 1..N - 1(T(X) + T(N - X) + (X + 1)·(N - X + 1)). Осталось понять, что T(N) = O(N2). Это можно сделать, например, написав простое ДП для подсчёта T. Если подумать, то можно понять это так: когда мы в цикле перебираем x = 0... p - i + 1 и y = 0... j - p, давайте будем представлять, что мы перебираем как будто пару строк: x = i... p и y = p + 1... j (тут перебор по x и y проходит на одну итерацию меньше, но это не принципиально); тогда каждая пара строк за весь подсчёт ДП окажется перебрана ровно один раз, что и даёт нам итоговую сложность O(N2).
Вот здесь можно ознакомиться с авторским решением.
Многие участники сдавали решения, использующее бор. Такие решения также могут иметь сложность O(N2), однако работают дольше и используют намного больше памяти. Тем не менее, ограничения по времени и по памяти были достаточно лояльны к разным решениям :)







В задаче от бобра очень легко писались простые частичные решения.
Будем обходить таблицу сверху вниз, слева направо.
При нахождении не отмеченного черного пикселя — пускать из него DFS по черным клеткам.
Тогда для решения на 20 достаточно заметить, что эта область — квадрат, если DFS не зайдет ни в одну клетку, которая левее стартовой.
Для решения на 50 достаточно посчитать расстояние между стартовым пикселем и самым правым из самых нижних пикселей. Предположим, что это диагональ квадрата. Дальше достаточно сравнить число закрашенных этим DFS пикселей с тем, которое соответствует квадрату с такой диагональю. Если значительно больше — значит, круг. Иначе — квадрат.
В задаче про квадрат можно было еще написать Meet-in-the-Middle. Для этого сгенерим в начале все неупорядоченные четверки чисел, у которых сумма равна той что нам надо. Теперь, переберем все пары таких четверок, у которых нет общих элементов и попробуем поставить эти 2 четверки в первые 2 строки. Затем переберем порядок элементов в каждой из четверок. Теперь осталось все захешировать и запихнуть в map (я для надежности использовал unordered_map). Каждый раз будем вычислять прямой хеш, а также хеш пары четверок, которая с ней может стоять в паре (обратный хеш). Если в какой-то момент обнаружится, что в map'е у нас уже лежит обратный хеш — просто выводим ответ. Без никаких оптимизаций с симметриями и без ручного хешмапа работает 0.39. Есть, конечно, решения и побыстрее, но если это пооптимизировать, то, думаю, будет около 0.1.
Не совсем понятно как найти для заданной пары четверок другую такую пару, с которой у нее нету общих элементов.
Ну как, у нас есть битовая маска 8 чисел, которые мы уже поставили. Значит нам нужно чтобы у оставшихся 8 элементов была противоположная маска. Просто в хеш помимо сумм запихнем еще и маску.
Если честно, вообще не понял юмора — чем всем это решение не нравится, за что минусы?
А разбор задач 1го раунда уже опубликовали?
http://codeforces.com/blog/entry/4387
Aaah, the local optimization of the functional trick in D — just like a boss! Magic squares — magic solution!
Расскажите, пожалуйста, решение с бором на F2 (50 баллов).
Я пробовал написать что-то вроде динамики по бору: для каждой вершины в боре храним наилучший ответ, взяв k ее потомков. Не разобрался в переходе.
Какие идеи надо было использовать?
Я писал динамику на сжатом боре. Для начала сжатый бор представляем в виде "левый сын-правый сосед". Тогда обозначим f(v, k) — максимальное значение репрезентативности, которое можно получить из поддеревьев вершины v, её правого соседа, правого соседа её правого соседа итп, используя k подстрок из этого поддерева.
В таком случае переход достаточно тривиален — перебираем i = 0... k, считаем, что i подстрок мы берем из поддерева вершины v, а k - i берём из остальных поддеревьев. Короче в итоге получается что-то вроде: f(v, k) = min(f(first[v], i) + f(next[v], k - i) + len[v] * (i * (i - 1) / 2) — здесь first[v] — левый сын, next[v] — правый сосед.
Вообще, насколько я знаю, это более-менее стандартная идея для динамик на дереве подобного рода (когда один из параметров — количество чего-то, чего нужно вытащить из поддерева).
Что такое представление бора в виде “левый сын-правый сосед”?
http://en.wikipedia.org/wiki/Binary_tree#Encoding_general_trees_as_binary_trees
Стандартная методика представления произвольных деревьев в виде бинарных.
Мне одному кажется, что авторское решение задачи F есть просто нетривиальная переформулировка динамики на сжатом боре?
Насколько я понимаю: авторское F(i,j,k) === G(v,k) для бора. Причём вершина сжатого бора v в почти соответствует набору строк [i..j] из оригинальной динамики. А разрез диапазона (i,j) числом p с минимальным lcp[p] соответствует разбиению множества сыновей вершины v в боре на две части. Интересующих нас отрезков 2N-1, и вершин сжатого бора столько же. А рекурсивная функция, описанная в конце решения, есть в точности обход в глубину бинарного дерева "левый сын-правый сосед" для сжатого бора.
Всё-таки в терминах бора придумать решение проще.
UPD: Извиняюсь, пост ниже с аналиогичным рассуждением не заметил...
У меня в точности такая же динамика, как в разборе, но на боре. Вместо i и j у меня вершина бора (нетрудно заметить, что деление отрезка на подотрезки между минимумами это и есть переход в детей вершины бора). Для вершины возвращаем вектор из cnt+1 элементов, где cnt — количество слов, заканчивающихся в поддереве. Переход такой. Обрабатывая вершину, будем делать динамику [сколько детей прошел][сколько слов взял]. Переход [k][n] -> [k+1][n+i] веса i*(i+1)/2+[i-й элемент динамики от ребенка]. При реализации удобно не хранить первое измерение, а просто, рассматривая очередного ребенка, обновлять ответы, проходя с конца (как в задаче о рюкзаке).
Реализация совсем простая (интересна только функция doit).
How to solve problem B2 Military Trainings?