


Hello everybody,
Today was the practice session of CEOI 2016 and the following interesting problem was given:
You're given N distinct integers. Print the maximum sum you can get by adding two of them that are coprime.
N is up to 100,000 and all the numbers are between 1 and 500,000. Time limit is 1 second, memory limit is 256MB.
Some solutions passed but most of them were using some odd tricks with unclear complexity. I was wondering if some neat solutions exist?






Hi! I am the setter of this problem. Yes, we actually have a clean solution!
Let's call the array V. First, sort the numbers in ascending order. Then, suppose you fix V[i] to be the greater element of the pair. It either has an optimal partner, V[j], which, because we've sorted the array, lies on its "left" (j <= i), or there is no coprime pair that has V[i] as its greater value.
Let's find this optimal partner for each element, or decide that it does not exist. Suppose we have a function countCoprimes(left, right) = how many k in [left, left + 1, ..right] exist such that V[k] and V[right] are coprime? We can then do a binary search for the greatest j <= i such that countCoprimes(j, i) == 1. V[j] will be the optimal partner for V[i].
To do this we need an efficient implementation of countCoprimes(left, right). The traditional approach is to use inclusion-exclusion, but to do this you need some divisor counts for all values in this subarray. So it seems hard to compute many such queries independently. However, it might be a good idea to evaluate many of them at once. Specifically, you should do the "partner" binary searches for all N values in parallel, not sequentially. With some adequate book-keeping, you can then solve all countCoprimes() calls in one iteration of the binary search for all N values in O(MAX_VALUE log MAX_VALUE), by doing a left-to-right sweep, keeping track of all divisor counts and doing inclusion-exclusion for each element and its associated query. The final complexity is O(MAX_VALUE log MAX_VALUE log N).
This is a high-level explanation, but you can probably figure out the details. If you have any questions, let me know! Anyway, we'll probably do another explanation on-site.
Can you explain the implementation of countCoprimes(left, right) in a little more detail? The traditional approach too, using inclusion-exclusion. Thanks!
I'm not 100% sure, please correct me if I'm wrong.
Suppose S is our candidate sum and M — number of ways to get it; M2 — number of ways to get it using elements divisible by 2, etc. If M > M2 + M3 + M5 - M2·3 + ... + M2·3·5 + ... then S is definitely a sum of coprime elements. We can calculate all the S's and M's using FFT. There are at most max(ai) / d elements for each divisor d, thus the final complexity is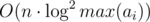
Hello! I am one of the members of the central committee at CEOI and I propose an alternative solution of complexity O(n + MAX_VALUE * sqrt(MAX_VALUE)):
Suppose we "break" the values into blocks of size O(sqrt(MAX_VALUE)) blocks. If you can preprocess the number of multiples of each factor for each "block", we conjecture that we can find whether two (different or equal) blocks contain any pair that is coprime in complexity O(sqrt(MAX_VALUE)) (try to come up with an algorithm -- the above post might help). Now, in order to solve this problem, you check every pair of buckets for the existence of a prime pair. Now, suppose we encounter a pair of coprimes between block x (holding values from x * b to (x + 1) * b - 1) and y (holding values from y * b to (y + 1) * b - 1). It immediately follows that there is at least one coprime pair which has the sum in the segment [(x + y) * b...(x + y + 2) * b - 2] (where b is the block size, namely sqrt(MAX_VALUE). So we can now examine the pair of blocks that give the largest "bound" and check (with a "brute force" approach) all the values that have the corresponding sum (which are, obviously, O(MAX_VALUE * sqrt(MAX_VALUE)) of them. Remember that, for this to work, we also need to apply the procedure described above for every pair of blocks (they are O(MAX_VALUE)), so the final complexity of the algorithm will be O(MAX_VALUE * sqrt(MAX_VALUE)).