


You are given an array of size N.
Update operation : < X, Y, L, R > : Add value Y to every X th element in [ L , R ].
Query operation : < X > : Return the value at position X .
Sample: Given array [1, 2, 3, 4, 5, 6]
1. update 2 1 2 5
The array will be transormed to [1, 2, (3 + 1), 4, (5 + 1), 6]
Any thoughts on the best time complexity we can achieve for the operations (online)?







How about this-> we divide value x in update operation in 2 categories..those which are greater than sqrt(n) and those smaller than sqrt(n)..now if value of x is greater than sqrt(n) we just apply loop and update the values and this loop would run for <=sqrt(n) time as jump length ie x is >sqrt(n)...now if x is less than sqrt(n) we store for this value of x the corresponding y..now when query comes contribution of heavy updates have already been added..we just loop through values from 1 to sqrt(n) and see if there was a update for this value and if there was does it affect the current index..so both operations can be done in approx sqrt(n) time... Note: Approach might be completely wrong. Could you please give the problem link...
I have seen the same problem somewhere and I wrote that solution in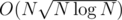 with a Fenwick tree for the light part which was good enough but I cannot remember from where it was.
with a Fenwick tree for the light part which was good enough but I cannot remember from where it was.
How about this?
Thanks for that reference!
Is the solution you say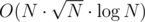 or is it
or is it 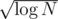 ? If it's the second case, can you please describe it?
? If it's the second case, can you please describe it?
It is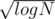 because it is needed to minimize
because it is needed to minimize 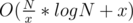 , thus optimal x is
, thus optimal x is 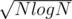 . Of course, in practice, you may find that other constants work better.
. Of course, in practice, you may find that other constants work better.
It's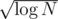 . The idea is similar to the one I described here. Lets B be a constant which we will choose for clarifying if current update is heavy or light. The main thing is that if we use
. The idea is similar to the one I described here. Lets B be a constant which we will choose for clarifying if current update is heavy or light. The main thing is that if we use 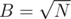 the heavy queries will be in complexity
the heavy queries will be in complexity 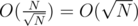 while the light one will be in complexity
while the light one will be in complexity 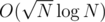 . This leads us to the idea to reduce B to make both complexities equal. Then
. This leads us to the idea to reduce B to make both complexities equal. Then 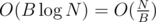 should hold. From where we conclude that
should hold. From where we conclude that 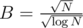 . And so complexities become:
. And so complexities become:
Have a look at this. Interesting idea — do get back here if it works fine. Apparently the discussion says we can solve it even lesser if we use a segment tree.
It does work, here is my accepted solution. Time complexity is around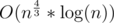 .
.
How do we check if it affects the current index? There might be more than 1 update for a particular i from 1 to sqrt(n). If we loop through all previous updates, it might be O(N). Did you mean something else?