


Hello!
Recently I learned about FFT algorithm, and I was confused because of it's precision errors.
Suppose that I want to multiply two polynomials A(x) and B(x) modulo 10^9 + 7. (max degree <= 10^6) Then I have two options :
use NTT with modulo 119 * 2^23 + 1. With these I don't have to worry about precision errors, but I have to split the coefficients in something like (c0 + c1 * 32 + c2 * 32^2 + c3 * 32^3 .... c5 * 32^5). This is the best we can use, since if we use something over 32, (33-1) * (33-1) * 1000000 > modulo. So I have to split it into at least 6 pieces, which is horrible..
use FFT with complex numbers : Well... we don't have modulos, so I have to guess here. I've experimented with 10^6-digit long integers with all digits in 9. (basically I calculated (10 ** 1000000 — 1) ** 2) In first try, I grouped two digits together (coeff < 100), and it worked fine. In second try, I grouped three digits together(coeff < 1000) , which had precision errors. So I can guess that it will be okay to split under 100. Now 5 pieces. Which is... eh, improvement, but still horrible.
Regarding problem F in here or this (spoiler alert), It's clear that there is a demand for big modulos. However, grouping into something like 30 or 100 is not only dumb, but very slow and constant-heavy, and it should be avoided.
I concluded that NTT won't help me in this problem, and arrived in following questions :
- How can we estimate the precision error of FFT? (or, is there some kind of rule of thumb in here?)
- What is the common way to avoid this situation? Isn't there any other way than grouping with number lesser than sqrt(mod), or karatsuba?
FYI, this is the code used in my experiment : https://gist.github.com/koosaga/ca557138cabe9923bdaacfacd9810cb1







How about NTT modulo 3 different primes ≈ 109, of valid form and then chinese remainder theorem?
You may need integers > 264 in the CRT part, but that part would have only O(n) calculations.
CRT doesn't need bigints if the mod is small enough (just do all calculations in modulo).
Let c be some coefficient in the product. Let the 3 primes be p1, p2, p3, and NTT's modulo them give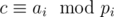
Let P = p1p2p3,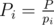 ,
, 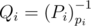 .
.
Then, we have to compute:
Here P > 264. How do you find this without using bigint ?
Garner Algorithm
How about this. You group log(sqrt(MOD)) digits together to form only 2 groups and use long double. I haven't yet encountered any precision problem using this method. Also there is karatsuba which can be used to solve both of the problems you mentioned within the time limit.
I am sorry, but I fail to understand this workaround.
Please explain a bit more.
I don't mind the downvotes but do explain the reason.
https://cp-algorithms.com/algebra/fft.html#toc-tgt-7
Ahh! Thanks for replying. It does make perfect sense now, if I understood the paragraph in the right way.
Right. It can be anything but the probability for precision error is the least when it is set to sqrt(M).
How about using NTT with a really large modulo (around 2^100) and use logarithmic multiplication with the Fourier transforms? (that would be a greater pain when
__int128is not supported).Karatsuba?
I know how to deal with it when you like complex numbers. Precision errors in FFT happen because you write it in a wrong way. The problem is when you're counting pw -- you count x^k like that: x^(k-1) * x. If you use cos and sin every time than it will be a slow solution but working fine. The right way to do it is to count x^k like that: x^(2^k_0)*x^(2^(k_i))*... where each of x^(2^k) you precalculate before just by calling cos and sin. When you want to count A * B % mod, you just to say that A_i = (a1_i + a2_i * BASE), and make 4 FFT (I guess you can decrease this number). As far as I know everything fitting in long long doesn't give you a precision error.
Thanks for your reply! However, I can't understand your workarounds :/ As I understand, we need O(lgN) time for calculating sin(x), which will be slower than default function.
He wanted to point out that using k multiplications to compute xk would add up rounding errors k times, but using repeated squaring would use only O(log k) multiplications and, thus, the rounding error would be orders of magnitude smaller. To suppress the extra log k time complexity factor I propose using memoization or computing the array p[i] = xi by means of dynamic programming (making sure to use the repeated squaring recurrence).
Now, my question for -XraY- goes as follows — did you do some testing regarding these precision issues?
Well, I don't really understand why your current score is -10 but you seem to be right. The easiest way is just change the line "pw *= ang;". You need to precalculate pw = {cos(..), sin(..)} and there would not be any precision troubles. To do that you can notice that pw is always a power of some primitive root. But using cos and sin and looking into array every time is a slow solution. So here comes a cool hack from Enot: you can put all your pws into one array and count them using only log(n) calls of cos and sin, so that there would not be any cache problem. Here is my code (Enot's looks similar): http://pastebin.com/iEXmyHvs
P.s. Yes, we tested our solutions. I don't know any solution faster or more precise. The best test is just multiplying big array of 10^k on itself. I get some troubles with this solution only when long long could not contain the result. Random array works much better.)
That makes things clear :D Thanks for your reply!
I've tested my code by multiplying two different polynomials. It worked when the result is under 10^14, but it didn't worked in 10^15. I changed double to long double, but still the change was insignificant. This sounds enough, since that accuracy is sufficient to solve above two problems I mentioned :D
pw is always a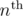 root of unity. So, you just have to precompute n roots of unity using n calls to cos and sin. So, the precomputation requires O(n*log(n)) time, which should work fine.
root of unity. So, you just have to precompute n roots of unity using n calls to cos and sin. So, the precomputation requires O(n*log(n)) time, which should work fine.
Well written FFT has an error that depends mainly on the magnitude of numbers in the answer, so it works if the resulting polynomial doesn't have numbers bigger than $$$10^{15}$$$ for doubles and $$$10^{18}$$$ for long doubles. You can measure the error by finding max of $$$abs(x - llround(x))$$$ over all $$$x$$$ in the answer. If it's smaller than $$$0.2$$$, you're good and rounding will be fine.