


Thanks drazil to translate the Chinese editorial to English.
Two of the problems in this week are created by modifying input constraints of recent Atcoder problems. The other three are a series of problems. Thus, in this editorial we won't follow the order of the problems but begin with the problems which are modified from Atcoder problems and put the series problems to the last.
Problem B — Write a Special Judge!
This problem is modified from AGC007 — Shik and Stone, which is originally created by Dreamoon as well. The difference in the Atcoder version is that the input must be a valid path (starting at the top left corner and ending at the bottom right corner). In fact, this modified version is the very first version proposed. But the contest organizers at Atcoder think this (modified) version is not easy enough resulting the constraint to the input. With the constraint we only need to verify whether the number of '#'s is n + m - 1 or not (you can justify why this solution will fail in the modified version).
Although we cannot count the number of '#'s directly in the modified version, this problem still has many ways to solve. Here we demonstrate a straightforward and easy to code one: Travel all cells in the order of left to right, top to bottom. Each time when we meet a '#', check if it is to the right or bottom of the last met '#'. Also don't forget to make sure the first and the last '#' are located at the top left and the bottom right cell respectively.
PS. Tester got accepted two times using incorrect code. Thanks him for making the test cases strong enough!
Here is the judge's code:
#include<cstdio>
int main(){
int n,m;
scanf("%d%d",&n,&m);
char s[12];
int x=0,y=1;
for(int i=1;i<=n;i++){
scanf("%s",s+1);
for(int j=1;j<=m;j++){
if(s[j]=='#'){
if((i==x&&j==y+1)||(i==x+1&&j==y)){
x=i;y=j;
}
else return 0*puts("Wrong Answer");
}
}
}
if(x!=n||y!=m)puts("Wrong Answer");
else puts("Accepted");
return 0;
}
Problem D — Edit Sequence
This problem is modified from ARC063 — An Invisible Hand. The difference is that the input numbers in the modified version are not unique (and also we simply the statement a lot). To be honest I didn't realized that the numbers are unique while participating in ARC063 (so I was shocking that many of the contestants got accepted so fast ... and I find out I ignored that condition after the contest when I look at the solutions of other contestants).
Let f(a) = h. Intuitively, we may list all numbers that contributes to f(a) = h first, then modify some of them to make f(a) smaller. For example, when a = [3, 5, 3, 3, 5, 2, 3, 4, 3, 3, 2, 4, 1, 2, 3]. Now we have h = 2 and the contributing numbers are [3, 5, 3, 3, 5, 2, , 4, , , 2, 4, 1, , 3].
It's not hard to find out that we can split those contributing numbers into non-overlapping segments (such as [3, 5, 3, 3, 5], [2, 4, 2, 4], [1, 3] in the above example) so that in each segment there are only two values and the lower values in each segment are decreasing (from left to right).
After splitting, we now need to further split each segment into two halves (with possibly an empty half). For each segment, if we modify all values in the left half to the larger values of the two and all values in the right half to the smaller value of the two, then the segment becomes valid. Again in the above example, [5, 5, 3, 3, 3][4, 4, 2, 2], [3, 3] is one of the valid example. After all those modifications, f(a) becomes smaller!
So the answer to the problem can be obtained by finding the smallest numbers of values need to be modified in each segment among all possible splits. A DP approach along with some simple counting can be utilized to get the answer in O(N), details are in the code.
At Codeforces, a contestant proposes exploiting the relation between matching and maximum flow to greedily compute the sub-answer for each segmentation. His code is HERE.
Here is the judge's code:
#include <bits/stdc++.h>
using namespace std;
const int INF = 1023456789;
const int SIZE = 200002;
int A[SIZE],left_mi[SIZE],right_ma[SIZE];
int solve(vector<int>& seq){
int now=0,ret;
for(int i=0;i<seq.size();i++){
if(seq[i]!=seq[0])now++;
}
ret=now;
for(int i=0;i<seq.size();i++){
if(seq[i]==seq[0])now++;
else now--;
ret=min(ret,now);
}
return ret;
}
int main(){
int N,h=0;
scanf("%d",&N);
for(int i=1;i<=N;i++)scanf("%d",&A[i]);
left_mi[0]=INF;
for(int i=1;i<=N;i++){
left_mi[i]=min(left_mi[i-1],A[i]);
}
right_ma[N+1]=-INF;
for(int i=N;i>0;i--){
right_ma[i]=max(right_ma[i+1],A[i]);
h=max(h,right_ma[i]-left_mi[i-1]);
}
int low=INF,an=0;
vector<int>seq;
for(int i=1;i<=N;i++){
if(A[i]<low){
an+=solve(seq);
seq.clear();
low=A[i];
}
if(A[i]==low+h)seq.push_back(A[i]);
else if(A[i]==low&&right_ma[i+1]==low+h)seq.push_back(A[i]);
}
an+=solve(seq);
printf("%d\n",an);
return 0;
}
Problem A — Score Distribution 1
This is the first problem of the series. Let's assume p1 ≤ p2 ≤ ... ≤ pN since the order of scores doesn't matter. The minimum possible total score of x problems is 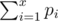 , while the maximum possible total score of x problems is
, while the maximum possible total score of x problems is 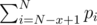 . So the problem asks us to make sure the minimum score of i + 1 problems is always strictly greater than the maximum score of i problems for all i from 1 to N - 1.
. So the problem asks us to make sure the minimum score of i + 1 problems is always strictly greater than the maximum score of i problems for all i from 1 to N - 1.
Of course, we cannot calculate the summation in O(N) for each i separately. We must use a more efficient algorithm.
Here is the judge's code:
#include<bits/stdc++.h>
using namespace std;
const int SIZE = 200001;
int p[SIZE];
int main(){
int N;
scanf("%d",&N);
for(int i=1;i<=N;i++)scanf("%d",&p[i]);
sort(p+1,p+N+1);
long long left_part=p[1],right_part=0;
for(int i=2;i<=N;i++){
left_part+=p[i];
right_part+=p[N+2-i];
if(left_part<=right_part)
return 0*printf("bad\n%d\n",i-1);
}
return 0*puts("good");
}
Problem C — Score Distribution 2
This is the second problem of the series, from now on we assume p1 ≤ p2 ≤ ... ≤ pN.
If you're guessing purely by looking at sample test cases, you may think that the answer is using binary search to find the smallest N consecutive numbers that satisfy the constraints. But sorry, I'm not a kind problem setter >_<. If you use this kind of methods, you may end up with values greater than 109. There are some other ways to get answers in the allowed range!
Here are some notations we will use later:
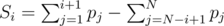 , which is the sum of the smallest i + 1 problems minus the sum of the i largest problem.
, which is the sum of the smallest i + 1 problems minus the sum of the i largest problem.- i is bad if and only if Si ≤ 0, in this case the condition is violated.
- All division from now on is integer division.
Before solving this problem. Let's prove an important property of this series: If i is bad, then for all i ≤ j ≤ (N - 1) / 2, j is bad.
Prove: We can observed that Si first decreases then increases (actually non-increases and non-decreases). The minimum value in Si will occur at S(N - 1) / 2. i is bad means Si ≤ 0, which indicates that all j between i and (N - 1) / 2 is bad since in that range Sj is decreasing (actually non-increasing).
Note that from now on we define S(N - 1) / 2 as the discriminant of the related sequence p, denoted as Δ(p).
From the property above, we know that if y > (N - 1) / 2 the answer must be Impossible, and we also know that in all other cases Sy ≤ 0 and Sy−1 > 0.
Now we consider a special sequence p only consists of two values: the first (N + 1) / 2 numbers are v1 and the last N / 2 numbers are v2. Under this assumption we must satisfy v1 × y > v2 × (y - 1) and v1 × (y + 1) ≤ v2 × y to comply with the condition. With some intuition we can see v1 = y, v2 = y + 1 perfectly fits the requirements!
Here is the judge's code:
#include<bits/stdc++.h>
int N,p[200001];
int main(){
int x,y;
scanf("%d%d",&x,&y);
N=x;
if(y*2+1>N)puts("Impossible");
else{
printf("%d\n",N);
for(int i=1;i<=(N+1)/2;i++)printf("%d ",y);
for(int i=(N+1)/2+1;i<=N;i++)printf("%d%c",y+1," \n"[i==N]);
}
return 0;
}
Problem E — Score Distribution 3
This is the third problem in the series, as usual we assume p1 ≤ p2 ≤ ... ≤ pN and integer division.
First we define a subsequence q = q1 = pk1, q2 = pk2, ..., qm = pkm of p (k1 < k2... < km) is good if and only if q satisfy the conditions (i.e. Δ(q) > 0).
A key observation is that is that for a p and a related good subsequence q, if we keep all values in q not changed and modify all other numbers in p to the value of pk(m + 2) / 2, then the modified p' will become good because Δ(p') = Δ(q).
Secondly, we can see that if there exists some good q of length m, then there exists some good "continuous" subsequence q' of length m which is also good. One way of constructing such q' is to take consecutive m values in p where the (m + 1) / 2-th number in q' is the (m + 1) / 2-th number in q (because Δ(q') ≤ Δ(q)).
Last key observation: if a continuous subsequence q is good, then any continuous subsequence of q is also good.
Prove: Assume q is of length m. We construct q' by removing the rightmost value in q. If m is even, Δ(q) - qm / 2 + 1 + qm = Δ(q'). If m is odd, Δ(q) - q(m + 1) / 2 + qm = Δ(q'). So we have Δ(q′) ≥ Δ(q), that means a good subsequence is still good if the rightmost value is removed. A similar prove can show that this conclusion holds for removing the leftmost value. In addition, any continuous subsequence of q can be obtained by removing values from left or right in q, q.e.d.
At this point, the problem is identical to find the longest continuous good subsequence. We can iterate all right boundaries and binary search for the left boundary to find the longest good continuous subsequence. Note that to check a continuous subsequence q is good or not only required O(1) time after O(N) preprocessing since we only need to know Δ(q). Also note that if the input is sorted there exists an O(N) solution.
Here is the judge's code:
#include <bits/stdc++.h>
#define SZ(X) ((int)(X).size())
#define MP make_pair
#define PB push_back
#define PII pair<int,int>
#define VPII vector<pair<int,int> >
#define F first
#define S second
typedef long long LL;
using namespace std;
const int SIZE = 200*1000+1;
VPII pp;
long long sum[SIZE];
int an[SIZE];
int main(){
int N;
scanf("%d",&N);
pp.PB(MP(0,0));
for(int i=1;i<=N;i++){
int x;
scanf("%d",&x);
pp.PB(MP(x,i));
}
sort(pp.begin(),pp.end());
for(int i=1;i<=N;i++){
sum[i]=sum[i-1]+pp[i].F;
}
int ma=1,anL=1,anR=2;
for(int i=N;i>ma;i--){
int ll=1,rr=i-1;
while(ll<rr){
int mm=(ll+rr)/2;
if(sum[(mm+i)/2]-sum[mm-1]>sum[i]-sum[(mm+i+1)/2])rr=mm;
else ll=mm+1;
}
if(ma<i-ll+1){
ma=i-ll+1;
anL=ll;
anR=i+1;
}
}
int v=pp[(anL+anR)/2].first;
for(int i=1;i<anL;i++)an[pp[i].second]=v;
for(int i=anL;i<anR;i++)an[pp[i].second]=pp[i].first;
for(int i=anR;i<=N;i++)an[pp[i].second]=v;
for(int i=1;i<=N;i++)printf("%d%c",an[i]," \n"[i==N]);
return 0;
}






