


Hi everyone,
Today we are going to show few demos of Sequence to Sequence models for code completion.
But before diving into details, we, as usual, want to ask you to participate in collecting data for the future models in our labeling platform here:
There are real money rewards associated with all the tasks in the platform.
The Demo
In the first demo we trained a seq2seq model, more on which below, on all the Accepted java solutions on CodeForces. The goal of the model is to predict the next token based on all the tokens seen so far. We then plug the output of the model into a code editor (the arena on the video is an unfinished project I will write about separately) to see how it behaves when one actually solves a competitive programming problem. Here we are solving problem A from Codeforces Round 407:
Notice how early on the model nearly perfectly predicts all the tokens, which is not surprising, since most of the Java solutions begin with rather standard imports, and the solution class definition. Later it perfectly predicts the entire line that reads n, but doesn’t do that well predicting reading k, which is not surprising, since it is a rather rare name for the second variable to be read.
There are several interesting moments in the video. First, note how after int n = it predicts sc, understanding that n will probably be read from the scanner (and while not shown in the video, if the scanner name was in, the model would have properly predicted in after int n =), however when the line starts with int ans =, it then properly predicts 0, since ans is rarely read from the input.
The second interesting moment is what happens when we are printing the answer. At first when the line contains System.out.println(ans it predicts a semicolon (mistakenly) and the closing parenthesis as possible next tokens, but not - 1, however when we introduce the second parenthesis System.out.println((ans, it then properly predicts -1, closing parenthesis, and the division by two.
You can also notice a noticeable pause before the for loop is written. This is due to the fact that using such artificial intelligence suggestions completely turns off the natural intelligence the operator of the machine possesses :)
One concern with such autocomplete is that in the majority of cases most of the tokens are faster to type than to select from the list. To address it, in the second demo we introduce beam search that searches for the most likely sequences of tokens. Here’s what it looks like:
Here there are more rough edges, but notice how early on the model can correctly predict entire lines of code.
Currently we do not condition the predictions on the task. Partially because number of tasks available on the Internet is too small for a machine learning model to predict anything reasonable (so, please help us fix it by participating here: https://r-nn.com). Once we have a working model that is conditioned on the statement, we expect it to be able to predict variable names, snippets to read and write data and computing some basic logic.
Let’s review Seq2Seq models in the next section.
Sequence to sequence models
Sequence to Sequence (Seq2Seq for short) has been a ground-breaking architecture in Deep Learning. Originally published by Sutskever, Vinyals and Le, this family of models achieved state-of-the-art results in Machine Translation, Parsing, Summarization, Text to Speech and other applications.
Generally Seq2Seq is an extension of regular Recurrent Neural Networks (we have mentioned them before in http://codeforces.com/blog/entry/52305), where model first encodes input tokens and then tries to produce set of output tokens by decoding on token at a time.
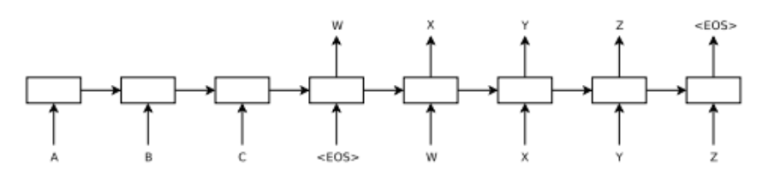
For example on this picture the model is first fed three inputs A, B and C and then it is given <EOS> token to indicate that it should start predicting output sequence [W, X, Y, Z]. Here each token is represented as a continuous vector [embedding] that is learned jointly with parameters of the RNN model.
At training time, model is fed with correct output tokens shifted by one, so it can learn dependencies in the data. The signal comes from maximizing the log probability of a correct output given the source sequence.
Once training is complete this model can be used to produce most probable output sequences. Usually to search for most likely decodings a simple left-to-right beam search is applied. Beam search is a greedy algorithm of keeping a small number B of partial hypotheses to find the most likely decoding. At each step we extend these hypotheses by every possible token in the vocabulary and then discard all but B most likely hypotheses according to model’s probability. As soon as “” (End of Sequence) symbol is appended to hypothesis, it is removed from the beam and is added to a set of complete hypotheses.
The model that we use right now is not a seq2seq per se, since there’s no input sequence given to it, so it only consists of the decoder part of the seq2seq. After being trained on the entire set of CodeForces java solutions, it achieved 68% accuracy of predicting the next token correctly, and 86% of predicting it among top 5 predictions. If the first character of the token is already known, the prediction reaches 94%. It is unlikely that a vanilla seq2seq will achieve a performance sufficient to be usable in practice, but it establishes a good baseline to compare the future models against.







I wish I had that when was competing in Java :( Hope you can do something similar to c++!
So one must inquire, what made you switch from Java to C++?
Many things.