


Don't use rand(). Why? Let's jump right into some code. What value will the following code print, approximately?
#include <cstdlib>
#include <iostream>
using namespace std;
const int ITERATIONS = 1e7;
int main() {
double sum = 0;
for (int i = 0; i < ITERATIONS; i++)
sum += rand() % 1000000;
cout << "Average value: " << sum / ITERATIONS << '\n';
}
Should be about 500,000, right? Turns out it depends on the compiler, and on Codeforces it prints 16382, which isn't even close. Try it out yourself.
What's happening here?
If you look up C++ documentation on rand(), you'll see that it returns "a pseudo-random integral value between 0 and RAND_MAX." Click again on RAND_MAX and you'll see that "This value is implementation dependent. It's guaranteed that this value is at least 32767." On the Codeforces machines, it turns out RAND_MAX is exactly 32767. That's so small!
It doesn't stop there though; random_shuffle() also uses rand(). Recall that in order to perform a random shuffle, we need to generate random indices up to n, the size of the array. But if rand() only goes up to 32767, what happens if we call random_shuffle() on an array with significantly more elements than that? Time for some more code. What would you expect the following code to print?
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
const int N = 3000000;
double average_distance(const vector<int> &permutation) {
double distance_sum = 0;
for (int i = 0; i < N; i++)
distance_sum += abs(permutation[i] - i);
return distance_sum / N;
}
int main() {
vector<int> permutation(N);
for (int i = 0; i < N; i++)
permutation[i] = i;
random_shuffle(permutation.begin(), permutation.end());
cout << average_distance(permutation) << '\n';
}
This computes the average distance that each value moves in the random shuffle. If you work out a bit of math, you'll find that the answer on a perfectly random shuffle should be 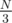 = 1,000,000. Even if you don't want to do the math, you can observe that the answer is between
= 1,000,000. Even if you don't want to do the math, you can observe that the answer is between 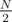 = 1,500,000, the average distance for index 0, and
= 1,500,000, the average distance for index 0, and 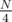 = 750,000, the average distance for index .
= 750,000, the average distance for index .
Well, once again the code above disappoints; it prints out 64463. Try it yourself. In other words, random_shuffle() moved each element a distance of 2% of the length of the array on average. Based on my testing, the implementation of random_shuffle() on Codeforces matches the following exactly:
for (int i = 1; i < N; i++)
swap(permutation[i], permutation[rand() % (i + 1)]);
So naturally if RAND_MAX is much less than N, this shuffle will be problematic.
rand() itself has more quality problems than just RAND_MAX being small though; it is typically implemented as a relatively simple linear congruential generator. On the Codeforces compiler, it looks like this:
static long holdrand = 1L;
void srand(unsigned int seed) {
holdrand = (long) seed;
}
int rand() {
return (((holdrand = holdrand * 214013L + 2531011L) >> 16) & 0x7fff);
}
In particular, linear congruential generators (LCGs) suffer from extreme predictability in the lower bits. The k-th bit (starting from k = 0, the lowest bit) has a period of at most 2k + 1 (i.e., how long until the sequence takes to repeat). So the lowest bit has a period of just 2, the second lowest a period of 4, etc. This is why the function above discards the lowest 16 bits, and the resulting output is at most 32767.
What's the solution?
Don't worry, as of C++11 there are much better random number generators available in C++. The only thing you need to remember is to use mt19937, included in the <random> header. This is a Mersenne Twister based on the prime 219937 - 1, which also happens to be its period. It's a much higher-quality RNG than rand(), in addition to being much faster (389 ms to generate and add 108 numbers from mt19937 in Custom Invocation, vs. 1170 ms for rand()). It also produces full 32-bit unsigned outputs between 0 and 232 - 1 = 4294967295, rather than maxing out at a measly 32767.
To replace random_shuffle(), you can now call shuffle() and pass in your mt19937 as the third argument; the shuffle algorithm will use your provided generator for shuffling.
C++11 also gives you some nifty distributions. uniform_int_distribution gives you perfectly uniform numbers, without the bias of mod -- i.e., rand() % 10000 is more likely to give you a number between 0 and 999 than a number between 9000 and 9999, since 32767 is not a perfect multiple of 10000. There are many other fun distributions as well including normal_distribution and exponential_distribution.
To give you a more concrete idea, here's some code using several of the tools mentioned above. Note that the code seeds the random number generator using a high-precision clock. This is important for avoiding hacks specifically tailored to your code, since using a fixed seed means that anyone can determine what your RNG will output. For more details, see How randomized solutions can be hacked, and how to make your solution unhackable.
One last thing: if you want 64-bit random numbers, just use mt19937_64 instead.
#include <algorithm>
#include <chrono>
#include <iostream>
#include <random>
#include <vector>
using namespace std;
const int N = 3000000;
double average_distance(const vector<int> &permutation) {
double distance_sum = 0;
for (int i = 0; i < N; i++)
distance_sum += abs(permutation[i] - i);
return distance_sum / N;
}
int main() {
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
vector<int> permutation(N);
for (int i = 0; i < N; i++)
permutation[i] = i;
shuffle(permutation.begin(), permutation.end(), rng);
cout << average_distance(permutation) << '\n';
for (int i = 0; i < N; i++)
permutation[i] = i;
for (int i = 1; i < N; i++)
swap(permutation[i], permutation[uniform_int_distribution<int>(0, i)(rng)]);
cout << average_distance(permutation) << '\n';
}
Both shuffles result in almost exactly 106 average distance, like we originally expected.
Additional References
This post was inspired in part by Stephan T. Lavavej's talk "rand() Considered Harmful": https://channel9.msdn.com/Events/GoingNative/2013/rand-Considered-Harmful
If you want even faster, higher-quality random number generators, take a look at this site by Sebastiano Vigna.







Thanks for an interesting and well-written post. Since we are on Codeforces, it would be nice to also see a real competitive programming scenario where the good old rand()%N doesn't work but mt19937 works. While your post shows strong evidence that rand()%N is bad, does this really matter in competitive programming?
An example would be any problem which requires random numbers of the order 100 000 or greater. Here's one such problem (from local training in Russian, so no public contest link, sorry!):
The jury has a string of 2n letters (1 ≤ n ≤ 100 000), fixed in advance in each test. Of these, exactly n are
as, and exactly n arebs. The contestant known only the value of n, and has to find any letterain the string. For that, the contestant can interactively ask up to 100 questions of the form “what is the letter at position p?”, and the jury gives back the letter. As soon as it is ana, the contestant's solution passes the test.Sounds simple, right? But the actual number of incorrect attempts is usually considerable, and a good portion of them is the result of using
rand()(the judge is using Windows and MinGW / Visual Studio, so the upper bound is 32 767, as explained in the post).I recall several problems requiring "pick random element" idea, where you can easily get WA if you aren't really picking random element.
Example: you have N lines, no two of them are parallel, you know that there is a point P such that at least N/2 lines pass through that point, your task is to find this point.
You'd want to take random pair of lines and check if their intersection is a solution, right? Sounds like 1/4 chance of guessing it for each try. Or zero chance, if the test has been build in such a way that all "good" lines have IDs larger than 32767 and you don't do any random_shuffle on the input (because why would you?..)
Sure, fair question. While the mediocre results of
random_shufflewill often still be good enough for you to pass a problem (case in point: 39639107), one big situation where you really need good randomization in your code is when doing hashing.When hashing you don't want to use fixed values, as someone can find a hack for your code fairly easily using a collision attack.
If you choose your multiplication base using
rand(), you'll be limiting yourself to 32767 possible values which isn't ideal. Worse, if you choose your hashing mod usingrand(), you'll be stuck with a very small mod value and extremely prone to collisions on big test cases.Even if you look for a mod by generating, e.g.,
1000000000 + rand()and repeating until prime, this only leaves you with about 1600 primes that you could end up with. It's actually very doable to perform a separate collision attack on each of those primes and concatenate all of the results into a single monster string that breaks this code. Especially so in a contest with an open hacking phase.Another common practice when using
rand()is to dosrand(time(NULL)). This is another vulnerability becausetime(NULL)only changes once per second, making it quite easy to hack again: just run collision attacks for each second in a 60-second range, and then submit the hack in those 60 seconds.So in summary, you may be able to get away with using
rand(). But don't do it. Just usemt19937.Here's an example of a virtually unhackable solution of mine using hashing with
mt19937_64and a high-precision clock: 42357469.AIM Tech Round 4 Div. 1 B. A lot of solutions with
rand()%Nandrandom_shufflefailed on this problem.Another advantage of C++ random generators over rand() is that they are independent objects instead of single static function. This comes in handy in the following case: suppose that you write a solution that uses random somehow and a random test generator in the same file (extremely useful in interactive problems, but in my opinion it is better than usual bash/bat scripts for classical problems also). Then you can create two separate instance of RNG to be used by your solution and by test generator respectively, this way changes in the solution and test generation don't influence each other, which makes testing and debugging easier.
OMG yesterday my team got many WAs in Problem F NWERC 2014 because of this issue. fixed the rand and got AC. Thank you so much.
You should at least mention the most common workaround for the original problem: instead of rand() % 1000000 use rand()*rand() % 1000000 or (rand() * RAND_MAX + rand()) % 1000000
This is enough in 99% of those few cases when just rand() isn't enough
Second version is working almost perfectly (though to fully avoid the same effect that makes the first version bad it is better to change it to
(rand() * (RAND_MAX + 1) + rand()) % (int)1e6), however the first one is a complete disaster unless you are fine with some results having probability more than 250 times higher than some other results: Simulation here, it times out on ideone, but you can run it locally.range = 1000000
rand_max = 32767
min occurences = 324
max occurences = 81403
And of course, you need to run code like this only on Windows testing systems (if RAND_MAX = 231 - 1, both versions are technically undefined behaviour and sometimes yield negative numbers anyway), so you need to also write a platform-dependent ifdef or something like this, increasing the amount of code even more.
A solution to the overflow problem is casting rand() to an unsigned type because in unsigned types overflow is not an undefined behaviour, even though this is a bit akward.
Also another option to generate a random numbe would be:
This is good because as you probably know << is faster than * (although this does not matter much as % will take the most time I think). What I said is correct because RAND_MAX in codeforces is 2^15-1 and in fact if MAXN and RAND_MAX are both powers of 2 (which is the case of codeforces) I think the results of this adaptation are equiprobable. I also suspect that RAND_MAX is a power of 2 most of the time (as you said it is the case in Windows).
Thank you so much!
I was really looking into generating random numbers and random shuffles while creating my first contest. This helps a lot.
Use functions from testlib.h if you create a contest. https://github.com/MikeMirzayanov/testlib
Thank you. It's a good idea though to know what is happening behind the scenes of testlib.h
Yes, it is. Looking through it and reading important functions (given in the very first comment) will take you around 10 minutes.
Can anyone tell, is it good idea to use such random functions?
#include<bits/stdc++.h>using namespace std;#define random() ((ll)rand() << 32 | rand())int main(){srand(time(NULL));cout << random() % 10000 ;return 0;}Sorry, ignore unintended code, i don't know how do i write readable code in spoiler
Tagging neal, I_love_Tanya_Romanova, Errichto and Gassa with all respect, hoping to get answer :)
Bad idea
The only advantage is that you can generate long long's now (some places like CF being exception, where
rand()returns a number up to 216). Disadvantages: smaller cycle (you will quicker get the same values), possibly losing some pseudo-random properties, slower program, you're doing something you don't understand. Read the blogs by neal.The following code: http://codeforces.com/contest/1114/submission/49736578 using:
as explained here: https://en.cppreference.com/w/cpp/numeric/random/uniform_int_distribution
gets WA. After a change to:
It gets AC. Do you know why?
I also got WA because of this. Apparently the MinGW implementation of
std::random_deviceis deterministic, see https://sourceforge.net/p/mingw-w64/bugs/338/.If problem authors prepared a test to kill this solution, it's really unfortunate and not fair in my opinion. Should we appeal to judges?
It's working after compilation with Clang++17 Diagnostics
Wow that's really unfortunate for us. I don't think problemsetters made that testcase, it was probably added to systests after someone used it in a hack, so I'm not sure if we can appeal the judgement.
Because of this problem I have added
mt19937 rng((int) std::chrono::steady_clock::now().time_since_epoch().count());to my template and will only use that from now on...No, you can't appeal judgements just because you don't like them. If your worst case isn't going to pass, it's on you to make sure that it isn't realistically possible for anyone to be able to break your code even if they are boundlessly clever. In java, for example, calling Arrays.sort() on an array of primitives will get you TLE on pretty much every contest because people will provide the worst case n^2 case to it in hacks, even though this would NEVER happen in the real world and isn't the sort of thing that is at all possible to make unless you reverse engineer Java's implementation of dual-pivot quicksort just to break it.
I didn't appeal it at all. Anyway, if you had read before posting your condescending comment, you would realize that this is a bug in the C++ compiler that CF uses: https://sourceforge.net/p/mingw-w64/bugs/338/. This does not comply with the C++ standard. The same code would pass in MSVC or any other compiler. So yeah, even if I did appeal, I'm not "appealing a judgement because I don't like it".
Could someone give me some evidences about how to do "work out a bit math of perfectly random shuffles"? It puzzled me.
Go through this.
Thanks a lot.
Hi, my question is related with Treaps, as they need random numbers.
I was trying to solve this problem: C2. Exam in BerSU (hard version), but during the contest I made this solution with Treap: My code and i got TLE.
Then I read the problem again and I solved it based on the limit for the time t_i
And after the contest I asked if somebody had solve this problem with treap and the answer was yes and this is the code Solution with treap
Now, I am asking to myself if my code doesn't work because of the way I use the random number generator (maybe the treap is unbalanced or i don't know) or my implementation of the treap is wrong.
I have no idea why my solution doesn't work
Any help will be appreciate. Thanks in advance and please feel free to asked about any part of my code. Here is the discussion after the contest: Here
How to generate random numbers between a specified range(say 1 to 25) without repetition?
If you want to generate a random numbers between the range $$$[l,r]$$$, you should use
rand()%r+l.UPD: Really sorry :( I made a huge mistake...
to generate a random numbers between the range [l,r], use
rand()%(r-l+1)+l!!NOT
rand()%r+lAre you sure the modulo operator will maintain the uniform random property of the distribution?
How do we show this?
By symmetry this is equivalent to the expected distance between two randomly chosen points between 0 and N. If the larger of the two chosen points is $$$x$$$, then the average distance over all choices for the other point will be $$$\displaystyle D(x) = \frac{x}{2}$$$.
We can then integrate over $$$x$$$ to find the answer. We need to know the PDF over $$$x$$$ though: it turns out that the PDF $$$P(x)$$$ should be directly proportional to $$$x$$$ since this is essentially the "number of choices" for the smaller point. So then the PDF is exactly $$$\displaystyle P(x) = \frac{x}{\int_0^N x dx} = \frac{x}{\frac{N^2}{2}}$$$. So then we get:
$$$\displaystyle \int_0^N D(x) P(x) dx = \frac{\int_0^N \frac{x^2}{2} dx}{\frac{N^2}{2}} = \frac{\int_0^N x^2 dx}{N^2} = \frac{\frac{N^3}{3}}{N^2} = \frac{N}{3}.$$$
There should be some nice non-calculus ways to think about this too. One way to visualize it is that we're looking for the "average" height of a triangular pyramid whose base is an $$$N \times N$$$ right triangle and whose height has length $$$N$$$ and is directly above the right angle of the triangle. But based on the formula for volume of a pyramid, the "average" height for any pyramid is just $$$\frac{H}{3}$$$.
Can please explain how did you find the Probability Density Function?
In gcc under Linux RAND_MAX is INT_MAX, so one should always be cautious even with that.
Thanks for the post, really helped in this task https://codeforces.com/contest/1514/problem/D?locale=en.
But I'm just curious why we can't use bit operations like this
(rand() << 15) | rand()to get randomized number that bigger than 32767, and use XORrand() ^ rand()to get more randomized number ?So finally it's look like
((rand() << 15) | rand()) ^ ((rand() << 15) | rand()).As Errichto has already written above, the only advantage of this code is possibility of generating big numbers. The disadvantages are smaller cycle (you will quicker get the same values), possibly losing some pseudo-random properties, slower program. I tetsed the following code in custom test
and it was running about 400 ms and printed 1073777492, which is quite near to $$$2^{30}$$$. Changing
sum += rng() / 2tosum += ((rand() << 15) | rand()) ^ ((rand() << 15) | rand()), as you are suggesting, made the program worse. It became 10 times slower (4 seconds) and printed 536866157, so the numbers are much less random.In fact, xoring
rand() ^ rand()can't make more randomized number. Really random numbers (if exist any) are already random and pseudo-random numbers still remain pseudo-random. It just can avoid failing system tests. But if there exists any hack that uses pseudo-random nature ofrand(), your solution can also be hacked.I used g++ 9.3.0 and tested the code given in the post, but my
rand()function returns 32-bit integers instead of 16-bit ones, whether itsc++98,c++11,c++14orc++17.Does anyone know what's going on? Thanks a lot!
Edit: I'm an idiot. I got it.
I just wanted to let you all know that you can use the hardware specific assembly instruction RDRAND to generate a true random seed.
RDRAND uses the on-chip hardware random number generator so it is virtually impossible to guess the seed in a competitive programming environment.
Example:
There are different alternatives for the size of the generated number:
You could also use rdrand to generate the random numbers and get rid of the c++ mt19937 generator entirely but beware because empirical tests showed that it is ~20 times slower
One last note is to use the pragma "rdrnd" if you want to use RDRAND and "rdseed" if you want to use RDSEED. The only difference between RDRAND and RDSEED is the fact that in RDSEED you will get independent random numbers from one another while with RDRAND you just need to guess one of them to know all the next ones. RDSEED is more useful when security is a concern, in this context I don't think it's useful at all.
Thanks so much for this interestring and useful post. It should be known by more people. I am Chinese, Could I translate it into Chinese to spread it? I will give the source,of course.
sure
I want to highlight that c++ stdlib mt19937 has a serious limitation, that makes it unusable in a multi-threaded apps b/c its logic gets random from /dev/urandom that is guarder by OS mutex that is a choke point.