


Hello, Codeforces!
This blog is heavily inspired by TLE's blog using merging segment tree to solve problems about sorted list. I don't know exactly how well known this data structure is, but I thought it would be nice to share it anyway, along with some more operations that are possible with it.
What it can do
We want a data structure that we can think of a set/multiset of non-negative integers, or even as a sorted array. We want to support all of the following operations:
- Create an empty structure;
- Insert an element to the structure;
- Remove an element from the structure;
- Print the $$$k$$$'th smallest element (if we think of the structure as a sorted array $$$a$$$, we are asking for $$$a[k]$$$);
- Print how many numbers less than $$$x$$$ there are in the set (similar to lower_bound in a std::vector);
- Split the structure into two: one containing the $$$k$$$ smallest elements, and the other containing the rest;
- Merge two structures into one (no extra conditions required).
Turns out that, if all elements are not greater than $$$N$$$, we can perform any sequence of $$$t$$$ such operations in $$$\mathcal{O}(t \log N)$$$, meaning that each operation costs $$$\mathcal{O}(\log N)$$$ amortized (as we will see, all operations except for (7) have worst case $$$\mathcal{O}(\log N)$$$).
How it works
We are going to use a dynamic segment tree to represent the elements. Think of each of them as an index, a leaf on a segment tree. We want the segment tree do be dynamic (we only create the nodes when we need them).
So, initially, there are no nodes on the structure (grey nodes are not present in the structure):
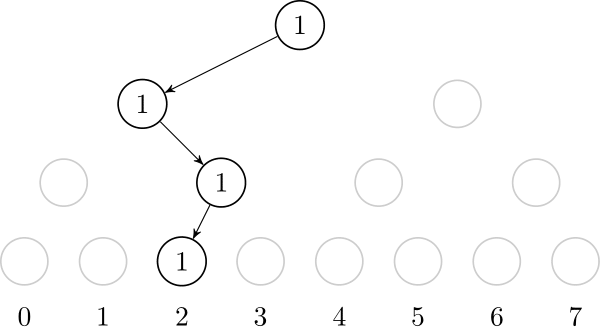
If we insert the value $$$2$$$, we need to create the path from the root to the leaf that represents $$$2$$$. It is also useful to store, on each node, the number of created leafs on that node's subtree.
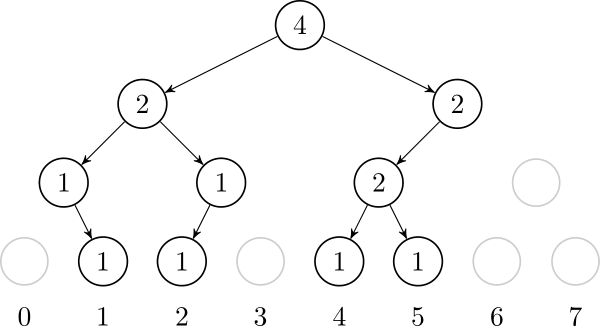
Let's also add $$$1$$$, $$$4$$$ and $$$5$$$. In the end, the tree will look like this:
Using this representation, it is very straightforward to implement operations (1), (2) and (3). Operations (4) and (5) are also easy, they are classic segtree operations. To do operation (6), we can go down the tree and either call recursively to the left or right child. Here is a pseudocode of this operation:
node* split(node*& i, int k) {
if (!k or !i) return NULL;
node* ret = new node();
if (i is a leaf) {
i->cnt -= k; // assuming multiset
ret->cnt += k;
} else {
if (k <= i->left->cnt) ret->left = split(i->left, k); // split the left
else { // take everything from the left and split the right
ret->left = i->left;
ret->right = split(i->right, k - i->left->cnt);
i->left = NULL;
}
}
return ret;
}
It is clear that all these operations cost $$$\mathcal{O}(\log N)$$$. On operation (6), note that we only go down recursively to the left or to the right child.
But what about operation (7)? It turns out that we can merge two structures in the following way: to merge the subtrees defined by nodes l and r, if one of them is empty, just return the other. Otherwise, recursively merge l->left and r->left, and l->right and r->right. After that, we can delete either l or r, because they are now redundant: we only need one of them.
Now let's see why any sequence of $$$t$$$ operations will take $$$\mathcal{O}(t \log N)$$$ time. The number of nodes we create is bounded by $$$\mathcal{O}(t \log N)$$$, because each operation creates at most $$$\mathcal{O}(\log N)$$$ nodes. Now note that the merge algorithm either returns in $$$\mathcal{O}(1)$$$, or it deletes one node. So total number of times the algorithm doesn't return in $$$\mathcal{O}(1)$$$ is bounded by the total number of created nodes, so it is $$$\mathcal{O}(t \log N)$$$.
Implementation
There are some implementation tricks that make the code easier to write and use. Firstly, we don't need to set $$$N$$$ as a constant. Instead, we can have $$$N = 2^k-1$$$ for some $$$k$$$, and if we want to insert an element larger than $$$N$$$, we can just increase $$$k$$$, and update the segment tree (we will only need to create a new root, and set its left child to the old root).
Also, it's easy to change between set and multiset representation. It is also easy to insert $$$x$$$ occurrences of an element at once, just increase the cnt variable of the respective leaf accordingly.
This implementation uses $$$\mathcal{O}(t \log N)$$$ of memory, for $$$t$$$ operations.
Memory optimization
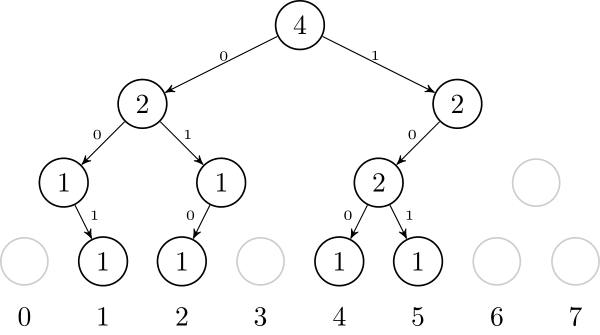
Another way to think about this data structure is as a trie. If we want to insert numbers 1, 2, 4, and 5, we can think of them as 001, 010, 100, and 101. After inserting them, it will look like this:
Using this idea, it is possible to represent this trie in a compressed form, just like a Patricia Trie or Radix Trie: we only need to store the non-leaf nodes that have 2 children. So, we only need to store nodes that are LCA of some pair of leafs. If we have $$$t$$$ leafs, that is $$$2t-1$$$ nodes.
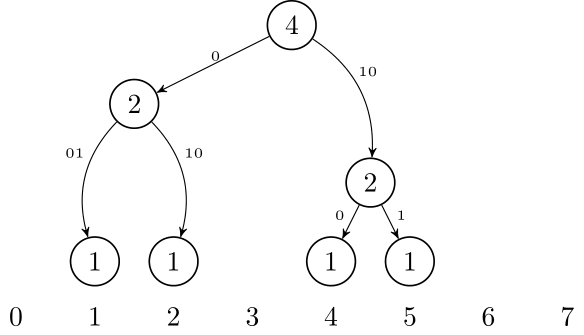
This is very tricky to implement, but it can reduce the memory usage from $$$\mathcal{O}(t \log N)$$$ to $$$\mathcal{O}(t)$$$ (see below for implementation).
Extra operations
There are some more operations you can do with this data structure. Some of them are:
- Insert an arbitrary number of occurrences of the same element;
- You can modify it to use it as a map from int to something, and also have a rule of merging two mappings (for example, if in set $$$A$$$ $$$x$$$ maps to $$$u$$$ and in set $$$B$$$ $$$x$$$ maps to $$$v$$$, it can be made so that in the merged set $$$x$$$ maps to $$$u \cdot v$$$);
- Using lazy propagation and possibly modifying the merge function, it is possible to do operations like insert a range of values (insert values $$$a, a+1, a+2, \dots b$$$ all at once), or flip a range of values (for every $$$x \in [a, b]$$$, if it is in the set, remove it, otherwise insert it), etc, maintaining the complexity of all operations;
- It is possible to use an implicit treap (or other balanced binary search tree) to represent an array, so that in each node of the treap you store a sorted subarray represented by this structure. Using this, we can do all of the usual operations of implicit tree such as split, concatenate, reverse, etc (but not lazy updates); however we can also sort a subarray (increasing or decreasing). To sort a subarray, just split the subarray into a treap and merge all of the subarray structures. The time complexity is $$$\mathcal{O}((n+t)(\log n + \log N))$$$ for $$$t$$$ operations on an array of size $$$n$$$.
Downsides
The memory consumption of the data structure might be a problem, though it can be solved with a more complicated code. The code is already not small at all. Another big downside is the amortized complexity, which leaves us with almost no hope to do rollbacks or to have this structure persistent. Also, the constant factor seems to be quite big, so the structure is not so fast.
Final remarks
The core of the idea was already explained on TLE's blog, and I also found this paper which describes its use as a dictionary (map). Furthermore, while I was writing this, bicsi posted a very cool blog where he shows an easier way to have the memory optimization, but it seems to make the split operation more complicated.
Problems
Using this structure to solve these problems is an overkill, but they are the only examples I got.
UPD: I have implemented the memory optimization for segment trees, you can check it out here: 108428555 (or, alternatively, use this pastebin) Please let me know if there is a better way to implement this.







this seems so intuitive yet I had never thought about it like that. Really nice
I really like your blogs. Keep it up!
I wonder if you can also reduce it to $$$O(t)$$$ space by structuring the tree like a Fenwick Tree (operations 2 through 5 remind me of Fenwick Tree)
Nice article brunomont, what did you use for the graph pictures?
Thanks! I used $$$\LaTeX$$$ and tikz. Example: https://pastebin.com/1DG900Cq
I am just curious to know, Can these operations be implemented using treaps and if so then which one would be the faster ??
bicsi has talked a little about that here, but I haven't tested it and I couldn't understand why that would give a good amortized complexity.
Ohh sorry i actually dont know how to merge two treaps maintaining the sorted format. I forgot about that before .
Regarding the name, I would say it's a dynamic segment tree. And well, a segment tree is the same with TRIE on bits (it's just that it needs all nodes first unless it's dynamic).
Hi !! What's the difference between lower bound and order_of_Key in your code ??
Hi, it is the same, I just added both so it would be more similar to other set structures.
Ohh ohkk Cool, btw it can be done like returning the actual lower bound which is just s[current_value_returned_by_lower_bound], and if the size is less we can return -1.
Actually 558E - Простое задание doesn't require such hard techniques. Only sinple segment tree can solve it.
If you were a bit less ignorant, you would have noticed that OP mentioned that in the blog. It does give a better complexity than "simple segment tree", though.
Using a simple segment tree is no slower than segment tree merge, they're both $$$26(n+q) logn$$$
Please read the blog more carefully. Using this technique we can achieve $$$\mathcal{O}((n+q)(\log 26 + \log n))$$$. Even for general keys we could just map them to $$$[0, n]$$$ in the beginning and get $$$\mathcal{O}((n+q)\log n)$$$, that is, we can get rid of the multiplicative factor of the size of the alphabet.
Auto comment: topic has been updated by brunomont (previous revision, new revision, compare).