


I've been working on computational number theory for my book and recently wrote a few new articles on:
- calculating modular inverse using binary exponentiation and extended Euclidean algorithm (spoiler: Euclid wins on average);
- Montgomery multiplication and fast modulo / division / divisibility checks for when the divisor is constant (which can often be used to speed up modular arithmetic by 5-15x);
- how to use them in various factorization algorithms (upd: fixed link) (writing a 3x-faster-than-state-of-the-art implementation of Pollard's algorithm in the process).
This is largely inspired by Jakube's tutorials and Nyaan' library implementations. Thank you!
If someone is interested, I may or may not try to optimize the sieve of Eratosthenes next: I believe it is possible to find all primes among the first $$$10^9$$$ numbers in well under a second.








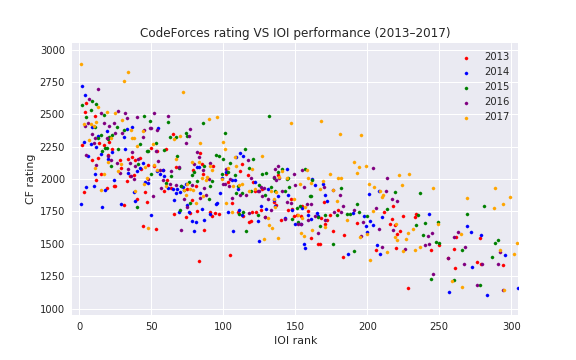
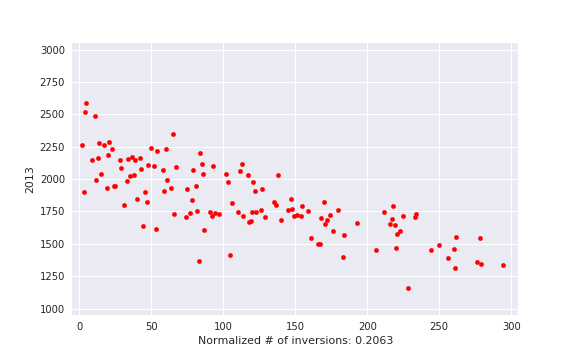
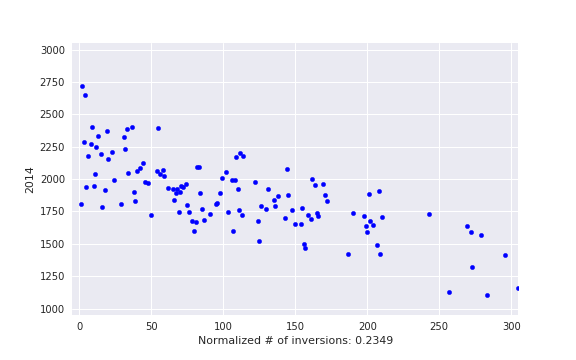
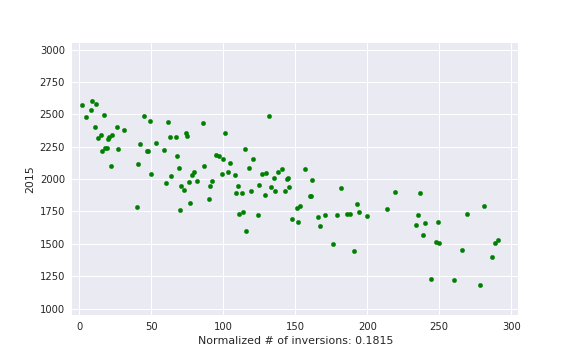
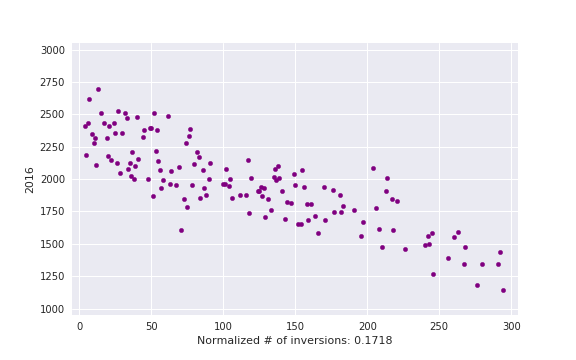
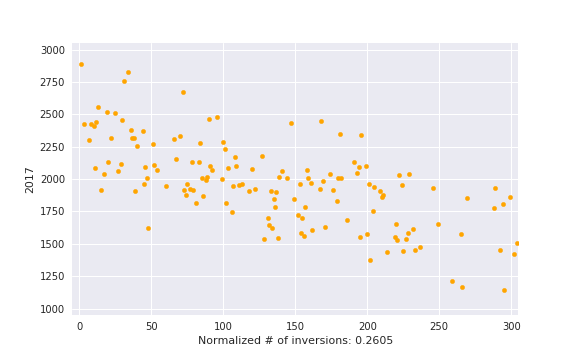
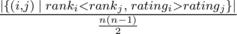 , i. e. actual number of inversions divided by maximum possible. This is some kind of measure of a contest being close to a standard CF round.
, i. e. actual number of inversions divided by maximum possible. This is some kind of measure of a contest being close to a standard CF round.