


Problem statement :
There are N planets in the galaxy. For each planet i, it has two possible states : empty, or it is connected to some other planet j ≠ i with a one-way path. Initially, each planet is in the empty state (i.e. there are no paths between any pair of planets)
There are three types of operations :
If planet i is in empty state, connect it with planet j with a one-way path (i and j are distinct)
If planet i is currently connected to planet j with a one-way path, remove that path. Consequently, planet i is now in empty state again
For a pair of planets u, v, find a planet x such that one can travel from u to x and v to x. If there are multiple such planets, find the one where the total distance travelled by u and v is minimized (distance is the number of paths it passes through). If there are no solutions, output - 1.
Q, N ≤ 106. Time limit is 10 seconds.
One of the official solutions uses splay tree to solve this problem, but I have no idea how it works (I haven't use splay trees before). Can anyone tell me how to use splay tree on this problem? Thanks.





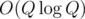 or
or 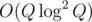 solution.
solution. parts of
parts of 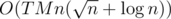 . My solution with this algorithm ACs the problem.
. My solution with this algorithm ACs the problem.
