


| # | User | Rating |
|---|---|---|
| 1 | jiangly | 3640 |
| 2 | Benq | 3593 |
| 3 | tourist | 3572 |
| 4 | orzdevinwang | 3561 |
| 5 | cnnfls_csy | 3539 |
| 6 | ecnerwala | 3534 |
| 7 | Radewoosh | 3532 |
| 8 | gyh20 | 3447 |
| 9 | Rebelz | 3409 |
| 10 | Geothermal | 3408 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
|
+90
Your English will become worse |

|
+41
Not red, but I read novels and do crosswords to improve my English skills so I can solve Div. 2 A |
|
+93
Ready for contest!
|

|
+34
Finally... a perfect excuse to join a rated round after nearly two years! Oh, it's Div. 2 only... |
|
+4
It should be 1. But my code doesn't even output anything lol. |
|
+25
Seems like n = 1. My code fails on this case, nobody hacked me :( RIP my rating. |
|
+17
The answer can possibly exceed the range of a 32-bit integer. Try the case consisting 99999 characters, with 1 ., 49999 # and 49999 . characters. Of course the answer is 2499900001 but your code outputs some garbage (it outputs -1795067295 on my machine, but signed overflow is undefined). |
|
+143
As the author of Codeforces Round #419, which probably pioneered this whole "anime pictures in statements" fiasco (Codeforces Round 426 (Div. 1), Codeforces Round 447 (Div. 2), Codeforces Round 449 (Div. 1)), I feel like I have an obligation to weigh in. My contest was rather well-received; the announcement received 724 upvotes, which was much higher than average. There were but a few complaints about the anime pictures; and, if the comments are to be believed, most people even loved them. I believe I crossed the line when I added the same pictures to the editorial—thanks to dalex for pointing it out, if rather abrasively; and I realized my mistake and removed them immediately. The issue is always going to be one of professionalism. Adding (any—drawings, clipart, etc.) pictures to the statement that do not immediately supplement understanding of the problem is always risky, and it's always a balancing act. If done poorly, it comes off as childish and even cringe-worthy. The most recent round has definitely given this impression, what with the, as you described,
in the announcement and completely unnecessary pictures in the problem statements. The trouble is exacerbated when the problem is shoehorned to fit the picture or story, rather than the other way around; it's always obvious when this happens, and always makes the problem frustratingly more difficult to understand. It's obvious when the author just wanted to throw the anime in there when a formal statement would have been much better; the problem statement feels unnatural and forced. (You can spot many examples of this in the problems today; "arbitrary operations on n talismans", when it is obviously just an array, "playing a game in order to determine who can use the kitchen", etc.) It's extremely frustrating when this happens, especially to people who already dislike the theme of the contest. It's almost as if the theme is ruining otherwise perfectly good problems. I took all these into consideration when writing my contest; I can't say how well I did. (You be the judge—you joined that contest.) I had commissioned an artist to do the artwork, so that the pictures would fit the statements exactly and at least serve some purpose (e.g. 815E - Karen and Neighborhood has identical houses in a row, which you will never see just scouring the Internet. Someone had to specifically draw that with that detail in mind.) All the statements, at least to me, felt natural, as most of them actually arose naturally and did not come from a formal statement first. (e.g. 815D - Karen and Cards was a real game I used to play with my little sister.) The pictures were as neutral as possible; I had to repeatedly stress to the artist that they had to be professional, and nothing even slightly suggestive was allowed. I don't discourage problem setters from adding images to their contests. But, please, exercise some discernment. Will it really make the contest better and more memorable? Remember, the contest isn't just for you; they're being given to the whole community, and people aren't coming here to see anime, they're coming here to solve problems. |
|
0
I'm not sure about it being on USACO, but what you're describing sounds like this UVa problem. It's basically n-queens but n ≤ 15, so you had to exploit many strategies to really squeeze the runtime. |
|
+17
This problem is actually a subproblem for the sweep line solution of the area of union of rectangles problem. It can be solved rather straightforwardly with a segment tree with lazy propagation. For each node in the segment tree, simply maintain the minimum m as well as the number of occurrences c of the minimum. Since m is always nonnegative, we can simply check whether m is zero; if it is, the node contributes its c occurrences of zero, and otherwise, zero doesn't appear at all, so this node doesn't contribute anything. You should be able to maintain these values without too much difficulty if you are familiar with segment trees already. |
|
+5
Yeah. |
|
+24
I'm not so sure about the point raised by BekzhanKassenov but I do know that downvotes on comments aren't displayed until they hit -5, to prevent herd voting / bandwagon effect. They will, however, still affect your reputation. It's very possible that your first comment got -4 and your second comment got +1, so the net result is still negative. |
|
0
You're right; thanks for pointing this out! My code specifically is actually But actually there is a way to knock out the extra n factor make it run in around First we will need to find all the ranges with all Afterwards, we can cumulate all the values, it will give the same sum array but in |
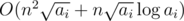 with very low constant factor, so it still passes.
with very low constant factor, so it still passes.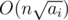 , with some log factors, using some clever bookkeeping.
, with some log factors, using some clever bookkeeping.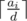 constant like before. Now we initialize all the sums to zero, then we can do the
constant like before. Now we initialize all the sums to zero, then we can do the 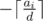 to the one after
to the one after 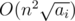 .
.|
+109
Basically problem is asking to maximize d such that:  We can do some algebra to get: 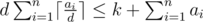 The right hand side doesn't depend on d, so basically we can consider it some constant C and just try to find the maximum d such that Now, if this were monotonic, we could find d easily using binary search. Unfortunately, it's not, because The trick here is that there aren't many distinct values of So what we can do is get all the possible distinct values of Now, for each range, we can now binary search d within the range; since all The runtime should be If it helps, here's my code. 28521138 |
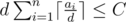 .
.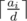 is decreasing while
is decreasing while 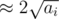 such distinct values. Anyway all the possible distinct values are given by
such distinct values. Anyway all the possible distinct values are given by 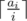 for all
for all 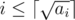 .
.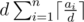 will be monotonically increasing. Actually we don't even need binary search at this point, but at least binary search requires less thinking. (Make sure to preprocess all the sums
will be monotonically increasing. Actually we don't even need binary search at this point, but at least binary search requires less thinking. (Make sure to preprocess all the sums 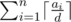 for each range before doing the binary search.)
for each range before doing the binary search.)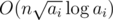 or something along these lines.
or something along these lines.|
0
Actually small-to-big works as well; limits aren't too tight. |
|
+65
It's a well-known game called Green Hackenbush. |
|
On
jonathanirvings →
Invitation to 2017 Indonesian National Olympiad in Informatics Open Contest, 7 years ago
0
Makes sense. That's a pretty neat trick! |
|
On
jonathanirvings →
Invitation to 2017 Indonesian National Olympiad in Informatics Open Contest, 7 years ago
+20
Dynamic programming. First assume that in our solution string there will be no intersection of prefix s and suffix t. We can use the following state: dpt(i, j, k) means that there is a way to visit some cells from (i, j) such that the resulting string is tk, tk + 1, tk + 2, ..., tlt (where lt is the length of t). We can do a similar thing for dps, but we should reverse s first. This means that we can find two cells (i, j) and (i', j') where dps(i, j, 1) and dpt(i', j', 1) are true. Then a valid solution is "start somewhere and end in (i, j), go to (i', j'), and end somewhere" and this string will contains s as a prefix and t as a suffix. We can compute dps(i, j, k) and dpt(i, j, k) in O(nm(ls + lt)); details are not very complicated, for example here is recurrence for t (gi, j is the cell at (i, j)): 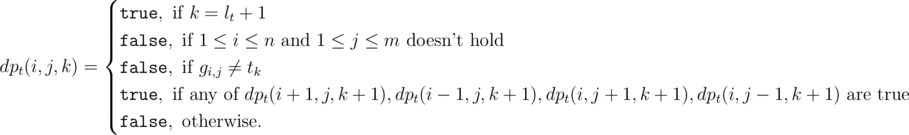 So, now all we have to do is "link" two cells where dps(i, j, 1) and dpt(i', j', 1) are true using the minimum number of cells. So we should find the "closest pair of cells" (i, j) and (i', j') (i.e. where |i - i'| + |j - j'| are minimum) where dps(i, j, 1) and dpt(i', j', 1) are true. We can do this using some sort of binary search in Now, what happens if our answer has prefix s and suffix t overlapping? Then we will miss the optimal answer. You can see it by testing this solution on the test case given in subtask 2; the optimal answer is The remedy to this is surprisingly simple. Look for all u such that sl - u - 1, sl - u, sl - u + 1, ..., sl and t1, t2, t3, ..., tu are equal. You can do it in O(ls2), no need for any fancy algorithms 'cause ls is very small. This lets us find all the "cutting points" where s will overlap t in our solution. Now we simply look for all pairs (i, j) where dps(i, j, 1) is true and check if dpt(i, j, u + 1) is also true (basically skipping t1, t2, t3, ..., tu, since they are already covered by s) for some cutting point u (just check all up to ls cutting points). You can then recover the answer in this case in O(nmls). In total, it runs in |
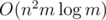 ; basically, list down all the values of
; basically, list down all the values of 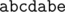 but this solution will give
but this solution will give 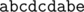 .
.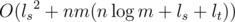 and it passes all subtasks.
and it passes all subtasks.|
+39
Understandable. The editorial is already quite long, and adding the pictures just makes it a bit longer and less readable. They should be removed in a while. Have a great day! |
|
+736
|

|
+11
I am depressed
|

|
+1
Wasted too much time, could not spot this bug Such silly mistake cost me like 20 minutes >_< |
|
+38
I'm pretty confident of the following solution. The amazing trick is to always let a + 1 = b whenever we query. Thus, this gives us the following information: "there is a dish closer to the left" or "there is a dish closer to the right". We are able to find the first dish this way. We perform a sort of "binary search" on the range [1, n]. Each time, we will query two consecutive midpoints m and m + 1 (where m = (l + r) / 2 as usual), then if it tells us there is one closer to the left, we go to [l, m], otherwise [m + 1, r]. Once the range has been compressed to 1 or 2 elements only, we will have found one dish. The second dish can be found similarly. Let x be the location of the first dish. Then, we will perform two separate binary searches like the one above: [1, x - 1] and [x + 1, n]. The amazing thing here is that the first dish x will never conflict with any dish in those ranges; that is, if a dish in either range exist, our binary search will find that and not x. We start with [1, x - 1]. If the answer to the queries is always Overall this takes |
 , and query
, and query 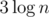 queries which fits comfortably in
queries which fits comfortably in |
+3
Missed submitting the Div. 1 C by 1 minute... horrible feeling ever! :( |
|
+21
tourist finished with the entire problemset in just a little over an hour, it's crazy. |
|
+10
I didn't solve it (made pretty bad mistake), but I think this is the intended solution. The only thing left would be to find σ, which can be done using Knuth-Morris-Pratt. So this solution runs in O(M) time. |
|
On
DeshiBasara →
ICM, Technex 2017 and Codeforces Round #400 (Div. 1 + Div. 2, combined), 7 years ago
+5
Seems like a lot of people did miss the k = 1 or k = - 1 case, so we could probably expect some changes in the leaderboard. |
|
+13
I don't really see a reason it wouldn't be okay. Checking every single possible case is a valid proof. (e.g. Four Color Theorem) If you tried every possible case and the slowest one is xxx, that constitutes a proof that the slowest case is xxx. Sure, it may be better to know why (especially when explaining it in editorials), but for the sake of posing it as a contest problem, I don't really see much of an issue with it, especially if the constraints are small enough that contestants can also stress-test it on their own computers. I recall 735D - Налоги, the "Goldbach's conjecture problem", being controversial not because you had to assume Goldbach's conjecture, but because many people thought it was uninspired and was just a basic application of some well-known results, and a similar problem had appeared on Codeforces before. |
|
+2
In a frenzy, I accidentally submitted my STRELICE solution for POKLON, and got 0 points... after the contest, I submitted the old POKLON solution and it got full points :( |
|
0
You can read the editorial of this problem. |
|
+61
2191 :| I'm starting to think maybe my rating is asymptotic to 2200.
|
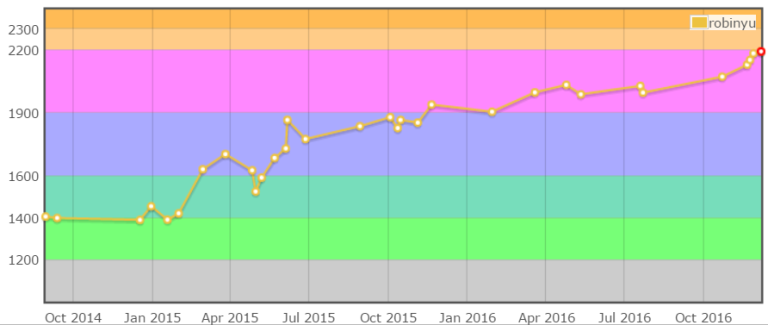
|
+35
We need a bit more positiveness these days :) |
|
+3
Well, there are some cool coincidences, like:
So, I hope increase of rating will also become coincidence :P |
|
+4
|
|
+58
Perhaps it's also important to raise this issue from albertg's post:
Did albertg get informed that contest begins in two weeks, and he must change new problems in that short time? Or, he got informed about problems quality and was given as much time as he wants to prepare some new problems? If it was the former case, I can understand why albertg (or any other problemsetter) might do it. Even for Div. 1 A, (good) problem ideas do not come from the snap of a finger, and sometimes I can come up with many good problem ideas in a day, sometimes I can think a week and I get not any good ideas. Still, in this case, he should tell GlebsHP (problem coordinator) that he cannot think any good idea, so maybe GlebsHP can contribute his own reserve problem, or he can request for more time. Better to have a delayed but good contest than a rushed but bad one. If it is the second case, then this is just absolutely unacceptable, and albertg absolutely have no excuse for this situation. This is just a sign of laziness, and problem writers should absolutely never compromise the quality of a contest just because they are too lazy to come up with new problems. This is cheating the community from a good experience. I also sent a proposal around this time (early this January), until now my problems quality have not been checked yet. At least, I know waiting game is being played by everyone else as well ;). Hopefully, problemsetters can learn from this event and take steps to avoid this tragedy from happening again in the future. |
|
+20
I think those that are part of official Codeforces (like Admins) are removed from the list, to be fair. That's why Zlobober was not there while he was coordinator, and also MikeMirzayanov, who should be surely #1 with +212! It's only fair since they have huge ratings boosts from stuff like official announcements. I guess it motivates the community to make more contests or blogs to increase their contribution, haha |
|
+3
We are assuming the best case scenario (maximum number of games played), so we can assume that 6 will win in this case. |
|
+20
behold the power of MS paint
|
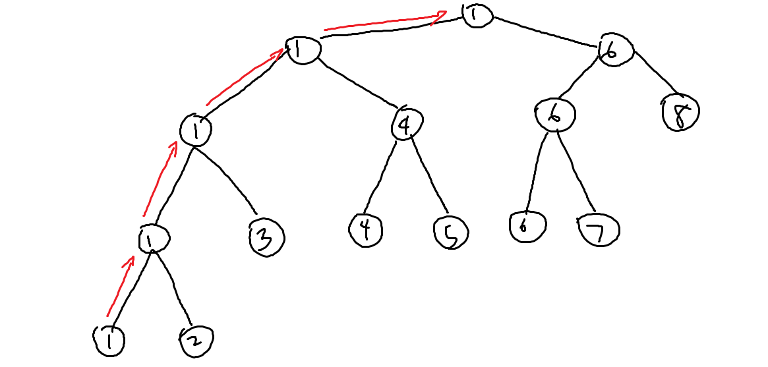
|
+8
The number of permutations of n elements, where there are a1 copies of the first element, a2 copies of the second element, a3 copies of the third element and so on (so a1 + a2 + a3 + ... + ak = n) is: 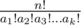 You can preprocess all factorials up to 100, and compute the above formula. Most likely, it will overflow even a 64-bit integer, so either you can use BigInteger for it, or I'm assuming that the problem asks for it modulo some prime (e.g. 109 + 7). In the latter case, you can use modular inverses to divide. |
|
On
nyan101 →
How can I solve query problems like "count the number of different elements in [l, r]" on array?, 7 years ago
+18
A red coder posted this as a comment a few months back. I have not implemented it myself and I don't really understand the idea behind it, but he is red, therefore he must be correct ;) The runtime is somewhere around O(N5 / 3), though, which is cutting it pretty close considering this probably has some constant factors. The benefit is that it can be used in other situations where Mo's algorithm is the only solution. |
|
On
nyan101 →
How can I solve query problems like "count the number of different elements in [l, r]" on array?, 7 years ago
0
Yes, the BBSTs are only for the first query. I'm not quite sure how you can guarantee |
 runtime per query using only a simple array. Maybe you can explain your approach for it, but I figured the BBSTs approach was the simplest. :)
runtime per query using only a simple array. Maybe you can explain your approach for it, but I figured the BBSTs approach was the simplest. :)|
On
nyan101 →
How can I solve query problems like "count the number of different elements in [l, r]" on array?, 7 years ago
+5
Sorry, it's a typo. I've fixed it. |
|
On
nyan101 →
How can I solve query problems like "count the number of different elements in [l, r]" on array?, 7 years ago
+28
Other solutions here only solve offline version, but it's not enough since his problem has updates. I heard of a way to do Mo's algorithm with updates, but if I don't quite remember how to do it (and it certainly isn't explained in the other comments :P) I will describe one way to solve this problem in Let's create an array B. Bi contains the first index j such that i < j and Ai = Aj, or ∞ if there is no such index. That is, it is the first index to the right which is equal to this element. Now, also create N + Q BBSTs. The ith BBST should contain the indices of all the elements whose value is equal to i. We should now create segment tree on B. If a node in the segment tree is responsible for the range [i, j], then it should contain a BBST with all the elements Bi, Bi + 1, Bi + 2, ..., Bj. Note that you cannot use C++ set for this, you must implement your own. Now let's look at how to answer the queries.
You can try implementing it here: UVa 12345 — Dynamic len(set(a[L:R])) |
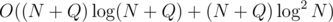 time. First, compress all the elements in
time. First, compress all the elements in |
+15
Here's what I did for E (I'm not sure if it's correct, but it seemed intuitive): Consider the 40% subtask. Go through each dwarf starting from the first one. At each point, the choice for an optimal solution is uniquely defined (didn't prove it, but seems intuitively correct):
This can be extended to the full solution. First, because we have exactly N elves, there is always at least one point i where the elves will not "spill over"; that is, no elf will ever come from dwarf i - 1 to i (or from N to 1 if i = 1). This is the critical observation. For example, if N = 6 and there are 3 elves assigned to dwarf 3 and 3 elves assigned to dwarf 5, then the point where the elves will never spill over is 3: because, an elf can never come from dwarf 2 to dwarf 3. Hence, we can relabel all the dwarves, shifting their labels such that i = 1. Now we just perform the same algorithm as earlier. Make a set with all unused elves who were originally assigned at dwarf 1 (relabeled), and then perform the algorithm described for the 40% subtask. When we move to a new dwarf, add all the elves assigned to that dwarf to the set. Due to our relabeling, we will never run out of elves at any point. Also, we can be sure that no elves can come from dwarf N to dwarf 1 by definition, so we don't have to worry about that. If anyone can come up with a counterexample to this solution, please let me know :) EDIT: It seems like this is the same as the author's solution. haha :) |
|
+30
I got TLE using even AC after switching to printf and scanf. |
|
0
Generally speaking, the problems in an Educational Codeforces round are some of the more "classical" problems unfit for a regular contest. In any case, it would not be a good idea anyway, changing all the problems last-minute. |
|
No. If there is, we can sort in faster than Keep getting the smallest element, and update it to ∞ after. But, it's already a well-known fact that there's no way to sort in faster than So, it's not possible. |
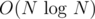 time.
time.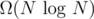 time (unless data has some special properties like counting sort or radix sort).
time (unless data has some special properties like counting sort or radix sort).|
+1
Let's say we want Stjepan to get contiguous segment from 1 to a - 1, Ivan segment a to b - 1, and Gustav–segment b to N. So, we will simplify the problem. Let's call Stjepan's difficulties A1, A2, ..., AN, Ivan's difficulties B1, B2, ..., BN, and Gustav's difficulties C1, C2, ..., CN. Let's define the function What's the minimum sum of difficulty of solving up to problem i, if only Stjepan can solve problems? Obviously, answer is A1 + A2 + ... + Ai. In other words, Now, what's the minimum sum of difficulty solving up to problem i, if only Stjepan and Ivan can solve problems? We can assign problem i to Stjepan, then the answer will be What's the minimum sum of difficulty solving up to problem i, if Stjepan, Ivan and Gustav can solve problems? It's quite similar to the previous one. We can assign problem i to either Stjepan or Ivan, then the total difficulty will be In this simplified problem, the answer is simply
Then get the minimum of all possible assignments. Then, that is the answer. |
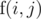 , to be the minimum total sum of difficulty to solve up to the
, to be the minimum total sum of difficulty to solve up to the 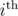 problem, using up to the
problem, using up to the 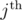 person. Of course, if
person. Of course, if 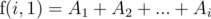 .
.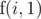 (since if we give this problem to Stjepan, we have to give all problems
(since if we give this problem to Stjepan, we have to give all problems 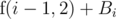 . Obviously we want to minimize the total sum, so we pick the smaller of the two. In other words,
. Obviously we want to minimize the total sum, so we pick the smaller of the two. In other words, 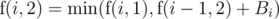 .
.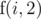 or we can assign problem
or we can assign problem 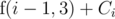 . So,
. So, 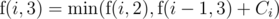 . If we implemented it correctly (store the previous answers using DP), then it should run in
. If we implemented it correctly (store the previous answers using DP), then it should run in 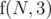 . Unfortunately, we kind of cheated, since it's not guaranteed that Stjepan will get
. Unfortunately, we kind of cheated, since it's not guaranteed that Stjepan will get |
0
They must be beside each other. So you can't take the fifth and the seventh one. (They are looking for substring, not subsequence) |
|
+1
I think you misunderstand the problem, the two substrings that you find should not be overlap. For example, you can find such answer: They don't overlap. |
|
+2
So many hacks with I'm also wrong. |
|
+6
I can see biggest problem, many people will just make multiple accounts. So Div. 2 participants, can make unrated account to "scan" problems first. Div. 1 participants, will make lots of fake accounts (which is already very big problem), get first place in Div. 2 contest, which makes the account becomes Div. 1, and then use it to "scan" problems for Div. 1 contest. So I think, it will cause more problems. |
|
+1
Needs to put in main page. Hope for high rating! |
|
0
Wow, I am amazed by it, can you explain the solution? :) |
|
0
I had lots of fun in solving, very nice problems! Very strange, I got almost half points for the sightseeing problem just using 3-fors algorithm. |
|
+14
So what do you want? Sereja tutorial? Or maybe you wanted this tutorial. I think long tutorial is good because it explains all necessary concepts, so it's easy to understand it. Besides, the point of editorial is to let people who didn't get problem understand the solution. So, it should be clear and easy to understand. |
|
+5
Everyone thought it's "can cut out as many substrings as you want" But actually it's only allowed to cut once. (Clarification) So contest went directly to hacking, to hack people who didn't update their code yet |
|
0
Also, I am not able to validate the UVa account or the Codeforces account. I have changed already my first name, I even changed the last name and the native name for the Codeforces, but it is still stuck to "Paste this key in your firstname". Is this a bug, or it just takes a long time? |
|
0
It's a very nice website! The format and layout is really clean, and there's not many ads. But you know, Ahmed-Aly already does something similar. But I like this one, since the layout is cleaner and easier to use. I think, you should add a bit more online judges here. For examples:
Also, it's better if "Browse Equivalence" and "Report Equivalence" are in the "More >>" tab. Then, you can move "Blogs" or "Dashboard" to the main tab, since I imagine more people will use those. It's also nice if we can chat with friends, like in Facebook (that would be the "social network" aspect of it). Then we can discuss problems or solutions. Finally, I think that "My Online Judge" should have some of its own unique problems too! Maybe it's quite difficult to set up an online judge, but it would be a great addition. I can see this website getting more popular in the future, so I hope that you will make it the best it can be! |
|
0
Same here, my C got pretests wrong, because of integer overflow! So I make up for it with lots of hacks :) |
|
+1
Many people did a slow O(NM) solution, reverse all the segments. Of course it's not passing for test case like:
|
|
+20
My hope has been granted :) |
|
0
Thanks for very fast system testing! |
|
+4
Hope for finally become blue :) |
