


| AGM 2021, Qualification Round |
|---|
| Finished |
At the peak of his pandemic-induced boredom, Johnny decided to write his own Japanese parser. He already figured a way to map romaji (Latin transliteration of Japanese characters) to kana (the two Japanese alphabets), but he still needs a way to split his text into romaji.
Given a block of text without spaces, consisting of lowercase Latin characters and basic punctuation marks (. , ; ! ? - ( ) ), Johnny needs this text split into romaji (and punctuation marks), separated by a single space.
Romaji are split into two categories: simple and compound. They are listed below. Compound romaji will be treated the same as simple ones.
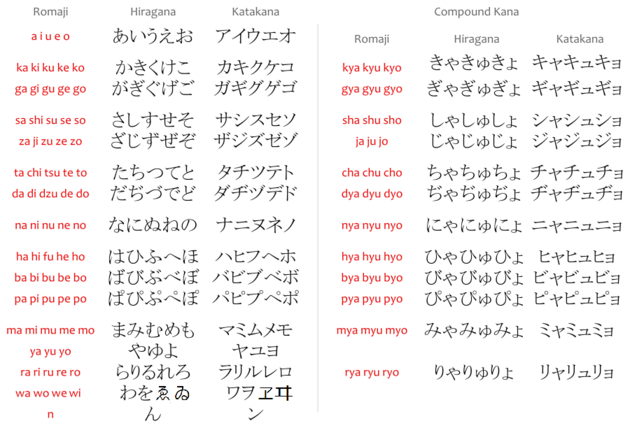
On top of these, Johnny needs to take extra care for some rules. In Japanese, some consonants are "double consonants" and they are marked in a special way. For the purposes of his parser, he decided to mark this by separating the doubled consonant as a lone character. For example "kitte" will be transformed into "ki t te". Double consonants can only appear only at the beginning of a romaji.
In cases where there's ambiguity, Johnny decided that simple romaji take precedence over compound ones (so "nyu" becomes "n yu"), but longer simple romaji take precedence over short ones (so "nu" remains "nu").
To make sure his parser is thoroughly tested, Johnny is using a combination of extracts from articles in Japanese and files he generated randomly, using the rules outlined above.
The input file consists of text up to $$$100000$$$ lowercase Latin characters and punctuation marks, guaranteed to lead to a correct solution.
The output should be a sequence of romaji, separated by spaces. Punctuation marks should be treated the same way.
arigatougozaimasu
a ri ga to u go za i ma su
tottemogenkidesu
to t te mo ge n ki de su
nazekorewohonyakushitanodesuka
na ze ko re wo ho n ya ku shi ta no de su ka
