Помогите, пожалуйста, решить задачу "Женитьба" с X Жаутыковской олимпиады. Условие
Я нашел разбор этой олимпиады, но я его не понимаю :(
В разборе написано, что алгоритм Куна работает за 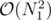 (разве не за
(разве не за 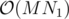 ?)
?)
Если закрыть на это глаза, то я понимаю оценку 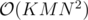 : перебираем отрезки за
: перебираем отрезки за 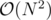 и поверяем за
и поверяем за 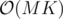 Куном.
Куном.
Но как получить из 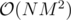 я не понимаю. Если применить идею, что если какой-то отрезок подходит, то подойдут все отрезки, содержащие его, то мы получим оценку
я не понимаю. Если применить идею, что если какой-то отрезок подходит, то подойдут все отрезки, содержащие его, то мы получим оценку 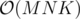 .
.
Что происходит в последней части разбора я вообще не понял.
Теперь о том, как делал я.
Запустим плавающее окно. Проверять будем с помощью Диница, который должен находить паросочетание быстрее Куна (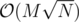 против
против 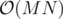 ). Но мы не будем каждый раз строить граф и находить паросочетание заново. При сдвиге правой границы добавим ребра в граф, а при сдвиге левой удалим ребра из графа, при этом откатим поток, который проходил по этим ребрам (наверное, что-то похожее имелось в виду в последней части разбора).
). Но мы не будем каждый раз строить граф и находить паросочетание заново. При сдвиге правой границы добавим ребра в граф, а при сдвиге левой удалим ребра из графа, при этом откатим поток, который проходил по этим ребрам (наверное, что-то похожее имелось в виду в последней части разбора).
За сколько эта ерунда будет работать, я понятия не имею, но берет 62/100.
Как решить эту задачу? Имеет ли смысл использовать здесь Диница вместо Куна?






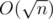 не придумал.
не придумал. блоков
блоков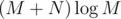 , но, видимо, с громадной константной, ибо TL 37.
, но, видимо, с громадной константной, ибо TL 37.