


Let's discuss the various approaches used to get the maximum points. :)
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Apr/26/2024 08:47:27 (k1).
Desktop version, switch to mobile version.
Supported by

Use dp approach
I agree, best approach
In A?
If you want
WasteOfTime
We used Alltheirmothers technique.
Can you explain what this technique is?
The Hog Rider card is unlocked from the Spell Valley (Arena 5). He is a very fast building-targeting, melee troop with moderately high hitpoints and damage. He appears just like his Clash of Clans counterpart; a man with brown eyebrows, a beard, a mohawk, and a golden body piercing in his left ear who is riding a hog. A Hog Rider card costs 4 Elixir to deploy.
Strategy
His fast move speed can boost forward mini tanks like an Ice Golem in a push. At the same time, he can also function as a tank for lower hitpoint troops such as Goblins as he still has a fair amount of health. Most cheap swarms complement the Hog Rider well, as they are nearly as fast as him and usually force more than one card out of the opponent's hand.
The Hog Rider struggles with swarms, as they can damage him down and defeat him quickly while obstructing his path. Barbarians in particular can fully counter him without very strict timing on the defender's part, though be wary of spells.
A Hunter can kill the Hog Rider in 2 hits if placed right on top of it. However, if you place something in front of the Hog Rider, the Hunter's splash will damage the Hog Rider and hit the card in front of it more.
The Hog Rider in conjunction with the Freeze can surprise the opponent and allow the Hog Rider to deal much more damage than anticipated, especially if the opponent's go-to counter is a swarm, or swarms are their only effective counter to him. Skeletons and Bats will immediately be defeated by the spell, while Spear Goblins, Goblins, and Minions will be at low enough health to be defeated by a follow up Zap or Giant Snowball.
However, this strategy isn't very effective against buildings as the Hog Rider will take a while to destroy the building, giving the opponent ample time to articulate another counter.
Against non-swarm troops, it can deal a lot of damage during the freeze time, but this can allow the opponent to set up a massive counterpush. For this reason, players should either only go for a Hog Rider + Freeze when they have other units backing it up from a counterattack, or if the match is about to end and they need to deal as much damage as possible.
It is not a good idea to send in a Hog Rider simply to destroy a building, especially if it is the only building targeting unit available, as defeating Crown Towers becomes substantially more difficult. Spells or simply waiting out the lifetime of the building are more effective. The exception to this is an Elixir Collector placed in front of the King's Tower. If a Hog Rider placed at the bridge, he can destroy the Collector for a positive Elixir trade, though the damage from both Princess Towers will usually mean he does not survive to deal any damage to them. However, if the opponent sends in defending troops, it can be an opportunity to gain spell damage value.
In a deck with several low-cost cards, it might be worth it to simply send the Hog Rider against one building. These decks shuffle their card rotation quick enough, that they will arrive to their next Hog Rider before the next building arrives in the opponent's card rotation.
Long-ranged troops like Musketeer and Flying Machine can snipe those buildings, preserving some of the Hog Rider's health, possibly allowing it to get some Tower damage.
When there are buildings placed in the middle to counter the Hog Rider, understanding the placement of the Hog Rider and the type of building placed can help the Hog Rider to bypass certain buildings.
Passive buildings such as spawners and Elixir Collector have a larger hitbox than defensive buildings; which means that if a passive building was placed 3 tiles away from the river in the middle of the opponent's side, then it is impossible for the Hog Rider to bypass that placement as the Hog Rider will get pulled to that building.
Defensive buildings have a smaller hitbox than a passive building, which means if that if a defensive building was placed three tiles away from the river in the middle of the opponent's side, a Hog Rider placed at the very left or right side of the Arena may be able to bypass it due to its smaller hitbox.
If the player has a building already placed down in the center of the arena, and the opponent tries to bypass it with a Hog Rider at the edge of the arena, they can use certain air troops to push the Hog Rider towards the building as it jumps over the river, effectively denying the bypass attempt. They must be already hovering over the correct placement, as very quick reflexes are required to correctly perform this technique.
For Bats, Skeleton Dragons, and Minion Horde, they should be placed right in front of the Hog Rider as soon as it is deployed.
For Minions, Skeleton Barrel, Mega Minion, Flying Machine, Electro Dragon, Baby Dragon, Inferno Dragon, Balloon, and Lava Hound, stagger the above placement one tile to the right if the Hog Rider is placed on the left side of the arena, and vice versa.
They can also use ground troops to achieve the same result. Something like an Ice Golem deployed at the Hog Rider’s landing spot will obstruct his path and force him to go around the unit, which causes him to be closer to the building instead of the Crown Tower.
The Hog Rider can kite Very Fast non-building targeting troops due to his own Very Fast speed and building only targeting if he is placed on the fourth tile from the bridge, slightly into the opposite lane. He can also stall grounded units when placed right at the bridge. He will pull them towards him while deploying, and then be untargetable by them when he jumps over the bridge. After landing, he will pull them back. This can be useful when the player needs to deal damage in the same lane they are defending. It will also help separate troops behind a tank in a large push.
A Tornado placed on the second tile front of the player's King's Tower and staggered two tiles towards the Princess Tower will activate it without any damage dealt to the Princess Tower, helping them in defending future pushes. This can also be a method of mitigating all damage dealt to a Princess Tower, but doing this more than three times may result in the King's Tower's health being low enough to be targeted directly, opening up the possible threat of a back door three crown. A better alternative is to pull the Hog away from the Princess Tower into the attacking range of all three Crown Towers, which will negate all damage as long as none of them are already distracted
A very powerful combo is the Hog Rider, the Musketeer, and the Valkyrie, typically referred to as the Trifecta. The Musketeer will defend against most troops, while the Valkyrie can protect her and the Hog Rider from swarms or high damage units. The Hog Rider is used to deal damage to the tower.
This can be effectively countered by Lightning, one-shotting the Musketeer and severely damaging both the Valkyrie and Hog Rider. The Minion Horde is also effective, but the enemy can Zap them and the Musketeer will one-shot them all. Even if the Musketeer is defeated, the Hog Rider and Valkyrie will have enough time to severely damage the Tower.
The Hog Rider should be placed behind the Valkyrie to give it a boost so that it stays in front of the Hog Rider, protecting it.
A Hog Rider combined with a Goblin Barrel can be awkward for the opponent to defend against. Timing it so that the Hog Rider is tanking the tower shots for the Goblins is the most effective way to deal damage. However, a Barbarian Barrel can shut this down with minimal Tower damage for a positive Elixir trade, as long as the Goblin Barrel was placed directly on the Tower.
Pairing the Hog Rider with the Balloon can deal devastating damage. If executed properly, the Hog Rider will act as a tank while the Balloon threatens to deal massive damage. The Hog Rider can also destroy any buildings attempting to slow down the combo. However, this combo is very vulnerable to swarms and anti-air cards as neither of the troops target anything but buildings. Additionally, they are easy to separate, due to the disparity in move speeds. Alternatively, the Hog Rider and the Balloon can be played in different lanes to spread the opponent's defenses thin. However, a building or Tornado can bring them back together for an easier defense.
The Hog Rider can be paired with the Lumberjack as both a swarm bait and damage combo. It is a very fast combo with an extremely high damage output potential, so the enemy will likely try to counter it with a swarm. If this happens, use a spell like Arrows to render the opponent defenseless. If they manage to defeat the Lumberjack, the dropped Rage will make the Hog Rider even more dangerous than it normally is.
A fast and deadly combination is the Hog Rider and Mini P.E.K.K.A. combo. Both units are fast but the Mini P.E.K.K.A. does much more damage and does not attack only buildings so the Mini P.E.K.K.A. can deal with troops like the Executioner and Musketeer. However, this combo can be defeated with swarms like Skeleton Army, which will defeat both of them since neither of them can deal area damage. They are also unable to target air troops, so the Minion Horde can stop this easily.
A risky play is to deploy the Hog Rider at the bridge as soon as the match starts. If the opponent does not react fast enough, the Hog Rider will deal a significant amount of damage to the Princess Tower. This can also allow the player to quickly scout the opponent's deck if they happen to react to him fast enough
Reply your scores in this thread ≧◠‿◠≦
A : 30 B : 743841 C : 211486 D : 133020 E : 159604 F : 558019
Total : 3244220
A:33 B:743829 C:193461 D:133020 E:1590866 F:470440
Total:3131649
Team: JaySharma1048576 PR_0202 abhidot yash_daga
A: 33 B: 901197 C: 194206 D: 251751 E: 1596710 F: 558276
Total: 3502173
A:33 B:900580 C:124667 D:251751 E:1640110 F:276248
Total: 3193389
A:33 B:901059 C:141216 D:66363 E:1637258 F:48425
Total: 2794354
A-33 B-275518 C-282 D-45860 E-1637258 F -0 Total1958951
A: 33 B: 743797 C :198398 D :126518 E : 1637258 F : 452267 Total : 3158271
$$$>$$$ teammate tries
int func(project a) { return (a.b * a.s) / a.d; }as a discriminant between projects$$$>$$$ teammate writes 220 line code sorting those projects by that discriminant
$$$>$$$ teammate leaves
$$$>$$$ "team" gets 3038681 points
When will they unfreeze the scoreboard ╥﹏╥
Why does it have to take so long to reveal the results? :(
We repeatedly took the task with maximum "score upon completion" / "total hours needed to complete". Used some bipartite matching stuff to find earliest time we can start a task. This was good for 3.486434 million points.
Do you mind explaining the bipartite matching part? We thought about it but got notwhere
We ignored mentoring except in easily solvable special cases, which makes it possible to use bipartite matching to figure out if you can do a job with a given set of people.
Not sure if practice is broken, but my solution for D was few mins late https://twitter.com/FakePsyho/status/1496973852093685760/photo/1
Edit: Posting pictures is hard, Got 2M on D in practice
Our story is also the same. No difference.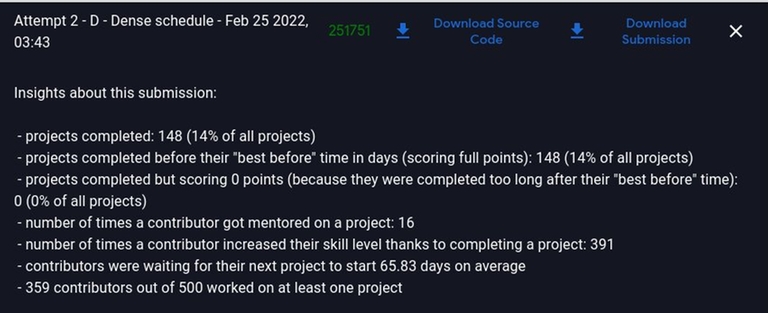
Our total would have been ~3754630. Missed potential WFs. :/
You're off by one zero ;)
Sorry. Definitely today is not a good day, to begin with. ;/
Nice! What is your solution doing? Is there something special in the test structure?
No special structure. The trick was in mentoring.
I believe D was designed in a way that's fully solvable with an extremely narrow path. Each contributor starts with a single skill, but some projects have 2 roles requiring the same skill. Most probably for some of those projects you only have 1 contributor with that starting skill so you have to train another one.
If all of your people have single skill there two way of learning another skill:
If you have 2 roles with the same skill and one of them is lvl 1, you need a mentor + any other contributor (and they will get lvl 1)
If you have two lvl 1 roles with different skills, you can take those contributors and swap them: instead of getting (potentially) to level 2, they will become mentor to each other and learn a skill.
Impressive! Could you elaborate on how SA can be applied here?
I didn't do SA, but my teammate (sullyper) did.
You can do SA on the order of projects. This should work fairly well even if your "matching" (subproblem of finding contributors for specific project) is not fully deterministic. Alternatively, you could add a "seed" to each project that makes matching more reliable. Then, your state transition is either moving projects or changing seeds.
His SA that ran for 4H got 3.1M (out of ~3.2M max). In my case (random order of projects), I got a score of 2M around once per 1000 runs, but each run took less than 0.1s.
This was my first hashcode and I was overjoyed with our performance. Though we did greedy we managed to place ~1K globally (≧▽≦). Edit: Got around 2.4 Million with it
What was your approach for F? Its name "Find great mentors" suggested that maybe you should prioritize mentoring somehow, but the obvious approach of greedily selecting people to increase their level or otherwise to select people with lots of skills only got around 250K. How do you get to 500K+?
We got 770k+ on F (on practice) greedily selecting the project which maximizes $$$\frac{score}{timestamp_{completed} \cdot r}$$$.
Priorotizing people with low skill levels got us to 600k
Weren't they supposed to announce the finalists by now? Did anyone hear anything from them?
The scoreboard is now finalized according to the competition platform, so they should notify qualified and waitlist teams in the upcoming days.
Score distribution of qualifier round
Score distribution of subtasks and previous years here. Source files and code here.
I made a GitHub repository of solutions scoring more than 5.7M in total (at the moment I write this message)