


400A — Inna and Choose Options
Not difficult task. Let's iterate param a. If 12 % a != 0, continue. Calculate b = 12 / a. Let's iterate column (from 1 to b) and for each it's cell (i, j) check, if it contains X or not. Cell (i, j) — is ((i–1) * a + j) -th element of string.
400B — Inna and New Matrix of Candies
In the final version of statement we must choose all lines we haven't finish already. If it is a string where we have S...G — answer - 1.
Otherwise, the answer is the number of distinct distances, as one step kills all distances of the minimal length.
400C — Inna and Huge Candy Matrix
Let's note that the number of 90 clockwise make sence only by modulo 4. Horizontal — by modulo 2, and 90 counterclockwise — by modulo 4, and 1 such rotation is 3 clockwise rotations.
90 clockwise: newi = j; newj = n–i + 1 don't forget to swap(n, m).
Horizontal: newj = m–j + 1
If the distribution is correct, after deleting all ribs with cost more than 0 graph will transform to components of corrects size. Also, the nodes are numereted so we should turn dfs for the first node of each type and be sure that we receive exact all nodes of this type and no ohter.
Now simple floyd warshall, and put in each cell of adjacent matrix of components the minimal weight between all ribs from 1 component to another.
Let's solve this for each bit separately. Fix some bit. Let's put 1 if the number contains bit and 0 otherwise. Now we receive the sequence, for example 11100111101.
Now let's look on sequence of 1 without 0, for this sequence current bit will be added to the sum on the first stage (with all numbers single) on the second stage (with all neighbouring pairs) on the third stage and so on, the number of appiarence for sequence of neighbouring 1 is a formula which depends on the length of sequence only.
The last is to learn how to modificate. For each bit let's save the set of sequence of 1. When the bit is deleted, one sequence is sepereted on two, or decreases its length by 1. When the bit is added, new sequence of length 1 appears, or some sequence increases its lentgh by 1 or two sequence transform to 1 biger sequence.






Problem "A" using Perl regular expresions 5953657 (more clear 5953597). Idea: to find in a row these combinations of symbols: 1) X, if you find X, then it makes column in 1x12, 2) X.{5}X, if you find X + 5 any symbols + X, then it makes column in 2x6, 3) X...X...X, X + 3 any sym + X + 3 any sym + X, then it makes column in 3x4, and so on.
Problem "B" using regexp — G\**S. I use the length of match of regexp, and make set. Answer is number of elements of set. (Perl 5953796).
i got one WA on problem C because i forgot to
swap(n,m)! this was a good thing "hidden" in the problem statement!Is the explanation for 400D correct? I get WA for the below test case when I implement a solution as described in tutorial.
"be sure that we receive exact all nodes of this type and no ohter."
Even I think that the statement "be sure that we receive exact all nodes of this type and no ohter." does not hold.
it is possible to reach from 1 to 2 via zero weight path (1->3->2), so as per question
"Dima's Chef (Inna) calls the type-distribution correct if there is a way (may be non-direct) to move energy from any bacteria of the particular type to any other bacteria of the same type (between any two bacteria of the same type) for zero cost"
Or you can use dsu for all nodes which can be reached via zero weight path and check whether the representative of kth category is the parent or not.
Here's my solution: 38347316
"no other" part is wrong
Couldn't understand B clearly :( can someone help me?
yeah I am also unable to understand the first sample test case.
could someone please explain ?
What is wrong with my solution to Problem E
Your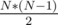 numbers.
numbers.
buildfunction is somehow invalid. Would you mind explaining your approach? As far as I can tell, you are using segment tree to calculate SUM and AND over entire array. This confuses me. The problem asks you to take AND on multiple "layers". So if the array has length N, then you must output sum ofBesides, in this problem answer can be as high as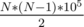 , which exceeds
, which exceeds
int.as I understood from the problem statement, the first layer contains the N elements I read from the input.
For each new layer I should apply AND operation between every two consecutive numbers and add the result to the new layer's sequence.
The final answer is the sum of all elements in All layers.
so when calculating values of the tree, for each individual element of the first layer, the answer is the element it self.
Then for each node I will merge the left and right child with these steps:
1- Add the sum of all elements on the left and right children.
2- Take the result of AND between the left and right children and add it to the result.
3- Now if neither one of both children has one element then you have a missing element in the new sequence which is the AND operation between the right most element of the left child and the left most element of the right child, I'll add the result to the sum.
Example on the 3rd step:
1st layer: 1 1 1 1
you will notice that there are two nodes will be merged together, a node with the first two elements and a node with the last two elements, but the resulting node will be missing the AND between the two elements in the middle, so I have to handle this case.
but in given test case: 1 1 1
you will have a node with the first two elements and a node with last element
and the result in the upper layer will have no missing elements.
the same steps are applied in the update part.
ok I got where I was mistaken, No I thought of another Idea, I will complete the array of the first layer to the next power of 2 so I wouldn't have any individual element in any other layer except the last one, and I'll set 1 to each valid element and 0 to any other.
Then the merge step will depend on the element if its valid or not, because in my first approach some if you have an array of 5 elements the last one will be presented in two layers and must be counted twice.
will the above suggestion fix this problem ??
Solution of problem D is wrong, this:
"If the distribution is correct, after deleting all ribs with cost more than 0 graph will transform to components of corrects size. Also, the nodes are numereted so we should turn dfs for the first node of each type and be sure that we receive exact all nodes of this type and no other."
Should be:
"If the distribution is correct, after deleting all ribs with cost more than 0 if we do dfs for the first node of each type we must visite every node of the same type."