


Hope you enjoyed our contest! The editorial is below:
Author: sg2themax
For this problem, you maintain an index counter pointing to the current song, starting at 0. At each step, you always ensure that you mod by the length of the record. You start off by playing the song at the index of the first number. After printing each song, you increment by one since Noah has "finished listening" to it. Then, you add the number of skips, print the next song, and repeat.
Author: blueberryJam
We first check whether the conditions can be satisfied, then if so compute the number of arrangements.
Pruning
Consider a situation in which a disk appears three times or more among all the distinct pairs. This is impossible to arrange since each disk is next to at most two other disks. Any arrangement with a loop of three or more disks is also impossible. Let there be an edge between two disks $$$A,B$$$ iff $$$A$$$ is adjacent to $$$B$$$. Then checking the graph (more specifically, forest) for these conditions can be be done in $$$\mathcal{O}(n+k)$$$ time with a DSU, BFS or DFS.
Computation
We can count the number of ways to arrange the disks using combinatorics. Assume there are $$$m$$$ trees in our forest. There are two ways to arrange the disks within each tree, by taking the original sequence or reversing it. There are $$$m!$$$ ways to permute the $$$m$$$ trees. Hence, the total number of arrangements is
where $$$q$$$ is the number of trees with 2 or more elements.
Author: mwen
For each song, let's count how many noteworthy subarrays there are where that song is the noteworthy song (has an excitement level greater than the sum of excitement levels of the other songs in the subarray). Consider the following two pointer approach:
Suppose our song is at index $$$i$$$. We first extend our left pointer $$$L$$$ as far left as possible while our song is still the noteworthy song in subarray $$$[L, i]$$$. Now, we iterate over each possible left endpoint $$$l\in [L, i]$$$, and for each $$$l$$$, extend our right pointer $$$r$$$ as far right as possible while our song is still noteworthy in the subarray $$$[l, r]$$$. Then any subarray starting at $$$l$$$ and ending in the range $$$[i, r]$$$ will be noteworthy. So for each $$$l$$$ we consider, we can add $$$r-i+1$$$ to our answer.
At first glance, this approach looks like it runs in $$$\mathcal{O}(n^2)$$$ time, but we can prove it is faster than that. The trick is, instead of counting how many times we move our pointers, we count for each song how many times a pointer passes over it.
Given a song with excitement level $$$a$$$, let's count how many times a left pointer passes over it. Let $$$b_1$$$ be the excitement level of the first song to the right whose left pointer passes over $$$a$$$. Then, it must be that $$$b_1 > a$$$. Now, consider $$$b_2$$$, the second song to the right whose left pointer passes over $$$a$$$. Since its left pointer passes over $$$b_1$$$ as well, it must be that $$$b_2 > b_1 + a > a + a = 2a$$$. Continuing this line of reasoning, for $$$b_3$$$, we can see that $$$b_3 > b_2 + b_1 + a > 2a + a + a = 4a$$$. In general, for $$$b_i$$$'s left pointer to pass over $$$a$$$, we must have $$$b_i > 2^{i-1}a$$$. If the maximum excitement level of songs is bounded by $$$A$$$, this implies we can only have at most $$$\log A$$$ songs whose left pointer passes over $$$a$$$. The same reasoning applies for right pointers.
Since each song only has $$$\mathcal{O}(\log A)$$$ pointers passing over it, this means the runtime of our two pointer algorithm is actually $$$\mathcal{O}(n\log A)$$$, which is fast enough as $$$A\leq10^9$$$. For reference, my code can be found here.
Author: Daveeed
Notice that $$$f(k)$$$ is defined in terms of a product of previous $$$f(x)$$$. The key observation here is that every $$$f(k)$$$ can be represented as the product of $$$f(1), f(2), \dots, f(n)$$$.
Then, if we could calculate each $$$p_i(k)$$$, then we could calculate $$$f(i)^{p_i(k)}$$$ for each $$$i$$$ and then multiply them all together. That is, we calculate the exponents of the factorization of $$$f(k)$$$ into $$$f(1) \dots f(n)$$$.
Calculating exponents.
Let's try to calculate $$$p_1(k)$$$, or the exponent of $$$f(1)$$$ in the factorization of $$$f(k)$$$. Then, clearly $$$p_1(1) = 1$$$ because $$$f(1) = f(1)^1$$$. For $$$2 \leq i \leq n$$$, $$$f(i)$$$ is defined without regard to $$$f(1)$$$, so $$$p_1(i) = 0$$$ for those $$$i$$$.
By definition, when $$$k > n$$$, $$$f(k) = \prod_{i=1}^nf(k - i)^{f(i)}$$$. If we only care about the exponent of $$$p_1(k)$$$ in this product, we have that $$$f(1)^{p_1(k)} = \prod_{i = 1}^n f(1)^{p_1(k-i)^{f(i)}}$$$. Then, $$$f(1)^{p_1(k)} = f(1)^{\sum_{i=1}^n (p_1(k-i) \cdot f(i))}$$$. So,
Then, since $$$p_1(k)$$$ is defined recursively and we have well-defined base cases, we can use matrix exponentiation to calculate $$$p_1(k)$$$.
We can use similar logic to find $$$p_i(k)$$$ for other $$$i \leq n$$$, and then use binary exponentiation with these exponents to find our final answer $$$f(k)$$$.
Note that because we need to find the final answer $$$(\text{mod}:10^9 + 7)$$$, we need to calculate $$$p_i(k)$$$ $$$(\text{mod}:10^9 + 6)$$$. This is because when our modulo $$$p$$$ is prime, Fermat's little theorem tells us that $$$a^p \equiv a \pmod p$$$.
Author: jxin31415
This problem is conceptually simple but tricky to get right. There are also multiple ways to go about this: I'll describe a couple.
VINYL
We'll start by doing most of our analysis for the VINYL case. We want to construct an equation for the given points, such that the equation is a circle and all points satisfy the equation. If not all points satisfy the equation, then this circle cannot be correct, and the object must be a cassette.
There are standard ways to try to write down the equation of a circle given points. GeeksForGeeks provides some existing code using three points. Then we can just check if the remaining 7 points satisfy the equation. If so, print VINYL, otherwise, print CASSETTE. Just make sure you handle NaNs correctly!
CASSETTE
Perhaps you are wondering, or you have already observed, that the number of points I provided is no coincidence. It's possible that a smaller set of points could fit both a circle and a rectangle.
This is easy to see in the following figure -- we can just take the points on the intersection of the rectangle and circle.
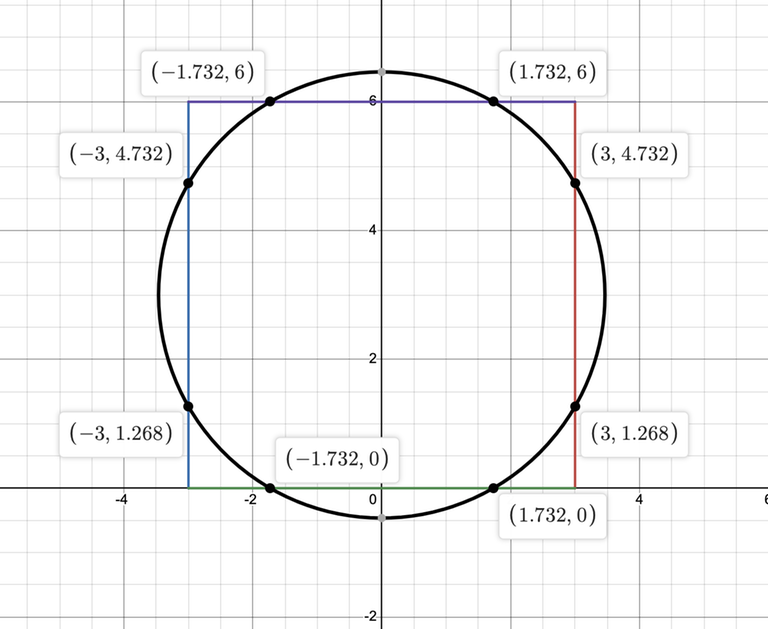
In fact, we can prove that 9 points is the necessary threshold to uniquely determine if the shape is a circle or rectangle. Consider a rectangle, which has 4 sides. If 9 points (or more) are provided, then by the generalized pigeonhole principle, at least 3 of those points must be on the same side, i.e. at least 3 points must be collinear. But there is no circle that fits three collinear (but distinct) points, hence there is no ambiguity. This lends itself to an alternative solution: check if any three of the points are collinear. If so, it must be a CASSETTE, if not, it must be a VINYL.
A brief aside.
Problems like these can be susceptible to floating-point imprecision; that is, computers often cannot represent floats perfectly and must provide an approximation. Hence, make sure your comparisons are based off of absolute difference rather than perfect equality (i.e., abs(x - y) < epsilon rather than x == y).
Author: isaac18b
We can solve this problem by doing some pre-processing on the grid of record values, and then iterating over the grid to find our shortest path.
From each position, we can either move up or left with costs that depend on the rest of the row/column. Looping over the remaining row/column to compute this cost would be too slow. Instead, we can store the sums of values in the rest of the row/column in prefix sum arrays, and then square these when we need to compute the cost of an action. In more detail, we can have two 2D arrays: one that stores the prefix sum of each row, starting at col 1, and another that stores the prefix sum of each column, starting at row 1. With these arrays set up in $$$\mathcal{O}(NM)$$$ time, we can now compute the cost of an action in $$$\mathcal{O}(1)$$$ time.
Once the prefix sum arrays are set up, we can iterate backwards over the grid (starting at position $$$(N, M)$$$ and ending at position $$$(1,1)$$$), updating the minimum cost of $$$(i - 1, j)$$$ and $$$(i, j - 1)$$$, where $$$(i, j)$$$ is an arbitrary location in the store, to be the min of $$$minCost(\text{old position}) + cost(\text{moving from old position to new position})$$$ and $$$minCost(\text{new position})$$$. After this $$$\mathcal{O}(NM)$$$ iteration, the answer will be the minimum cost of $$$(1, 1)$$$.
Author: DylanSmith
We can consider a graph with one node for each record, and an from record $$$i$$$ to $$$b_i$$$ for each $$$i$$$. Then, the problem can be stated as counting the number of $$$m$$$-colorings of the constructed graph. Since this graph is functional (every node has exactly one outgoing edge), we can decompose the graph into components, where each component consists of a cycle and a set of trees rooted at each node in the cycle. For any node not in a cycle, we may construct a coloring from its root, so each node will have $$$m - 1$$$ possible colors regardless of the color of its parent in the tree. For nodes in a cycle, we can model the cycle of length $$$k$$$ as a list of colors of length $$$k + 1$$$ such that the first and last colors are equal. We can then find how many such colorings exist with dynamic programming, using two states for each index. Let $$$z_i$$$ be the number of colorings of a sequence of length $$$i$$$ such that the first and last nodes are equal, and let $$$o_i$$$ be the number of colorings such that the first and last nodes are not equal for some fixed color of the last node. Then, we have the following recurrence:
with $$$z_1 = 1$$$ and $$$o_1 = 0$$$.
We can precompute this dp to make implementation easier, so all we need to do is find the size of each cycle, multiply $$$z_{k+1}$$$ for all cycle sizes $$$k$$$, and multiply that value by $$$(m - 1)^l$$$ where $$$l$$$ is the number of nodes not in a cycle. We can find the cycle sizes using a dfs, knowing that the first time we visit a component, a cycle will be found. Then, $$$l$$$ is equal to the sum of all $$$k$$$ subtracted from $$$n$$$.
In order to solve the problem, we need to make use of the fact that
So, what are some things that we can notice about the prefix multiplications? Most notably, we can decompose the multiplication as follows:
and in particular, focusing on the coefficient on $$$a$$$. If we model the coefficient as follows, we get
and so, we can see will form Pascal's if you exclude the first row. Therefore, using some basic combinatorial formulas, we can get $$$\binom{x - i + k - 2}{k - 1}$$$ where $$$i$$$ is the $$$i$$$-th number in $$$a$$$. This will be the exponent that we take, and it needs to be mod $$$\phi(m) = m - 1$$$ for prime $$$m$$$ (so in this case, $$$10^9 + 6$$$). This can be computed via Pascal's triangle's formula: $$$dp[i][j] = dp[i - 1][j] + dp[i - 1][j - 1]$$$. This is done in $$$\mathcal{O}(n^2)$$$, and only needs to be done once. Finally, in order to compute our answer for each query, we can just take
which runs in $$$\mathcal{O}(n)$$$ per query, giving us a final time complexity of $$$\mathcal{O}(n\cdot \sum q)$$$.
Author: zekigurbuz
The most straightforward approach to this problem would be an $$$\mathcal{O}(N \cdot M)$$$ dynamic programming solution. In short, we may store the optimal solution using the first $$$m$$$ bytes (for $$$m \in {0, 1, 2, \dots, M}$$$), and then output the optimal solution using all $$$M$$$ bytes. Each of the $$$M$$$ states will then need $$$N$$$ transitions, considering trying to store each record type (or not). However, $$$N \cdot M = (2 \cdot 10^5)^2 = 4 \cdot 10^{10}$$$ in the worst case, so our naïve solution will not pass in time (even with heavy optimization).
Key insight.
It might intuitively appear useful that, for two records that have the same size (in terms of the length of their title), it is always better to store the one which has a higher value. As such, we can reduce the number of transitions from $$$N \leadsto \mathcal{S} := |{|S_i| \mid i \in {1, 2, \dots, N}}|$$$, where $$$\mathcal{S}$$$ represents the number of unique title lengths among the strings in the input. How can we bound $$$\mathcal{S}$$$?
Some analysis.
We use the fact that $$$\sum_{i=1}^N |S_i| \leq 2 \cdot 10^5$$$ to our advantage. In the worst case, the unique title lengths could be $$$1, 2, 3, \dots, k$$$, for some $$$k \in \mathbb{N}$$$. But,
Conclusion.
As such, $$$\mathcal{S} = \mathcal{O}(\sqrt{2 \cdot 10^5}) \approx 500$$$, so the naïve solution along with the optimization of taking only the best record of each length yields a solution with complexity $$$\mathcal{O}(500 \cdot M)$$$, which comfortably passes since $$$M \leq 2 \cdot 10^5$$$. The judge solution in C++ can be found here.
Author: tn757
The problem asks us to report the most new records listened to in a day, so we need a way of knowing whether or not a record is new. We can use a map or an array of size $$$N$$$ to keep track of whether or not we've listened to a record before. Then, for each day, if a record is new, add 1 to that day's count and add it to the map. Then, return the max count across all days.
Author: fishy15
The critical observation for this problem is that the maximum number of distinct palindromes in a string is $$$n$$$. To prove this, we will show that there is at most one new palindrome when we insert a new character to the end of a string.
Suppose that we are able to make at least two new palindromes when we insert a character at the end. Let the largest length of a palindrome ending at the new character be $$$k_1$$$, and some other length of a palindrome ending at the new character be $$$k_2$$$. We note that the palindrome of length $$$k_2$$$ is a substring of the palindrome of length $$$k_1$$$, and so we can internally flip it to find another instance of the palindrome. For example, in the palindrome "aabaa," the subpalindrome "aa" appears earlier in the string once already. Thus, the palindrome of length $$$k_2$$$ has actually appeared in the string already, so it does not contribute to the total number of distinct palindromes. Only the largest palindrome ending at that character could potentially be a new character, so the total number of palindromes is at most $$$n$$$.
Now, to solve this problem, we can compute the largest palindromes centered at each character for odd-length palindromes or centered at each pair of adjacent characters for even-length palindromes. This can be computed using Manacher's algorithm or simply binary searching with string hashing.
Starting from the largest palindrome, we can keep inserting them and incrementing the count of the palindromes we have seen as long as we see a new palindrome. When we encounter a palindrome we have seen before, we know all smaller palindromes centered at the same location have also been seen before, so we can skip them. Thus, we only ever process $$$n$$$ new palindromes. Overall, our runtime is $$$O(n \log n)$$$ if we use binary search or a BBST, but we can also implement in $$$\mathcal{O}(n)$$$ with Manacher's and a hashmap.
Sample Code (C++): link.
Author: DylanSmith
Consider the array $$$b'$$$ where $$$b'_i = 1$$$ when $$$b_i = 0$$$ and $$$b'_i = 0$$$ otherwise. We can define $$$a'$$$ similarly for $$$a$$$. Then, if position $$$i$$$ of the first pizza is aligned with position $$$j$$$ of the second pizza, $$$a_i \cdot b'_j + a'_i \cdot b_j$$$ will equal the contribution of this pair to the tastiness under the rotation that creates this alignment. This is because if $$$a_i > 0$$$ and $$$b_i = 0$$$, the expression evaluates to $$$a_i$$$ since $$$a'_i = 0$$$ and $$$b'_i = 1$$$. Similarly, the expression evaluates to $$$b_i$$$ if $$$b_i > 0$$$ and $$$a_i = 0$$$. If $$$a_i > 0$$$ and $$$b_i > 0$$$ then $$$a'_i = b'_i = 0$$$ so the expression evaluates to $$$0$$$, and if $$$a_i = b_i = 0$$$, then it also evaluates to $$$0$$$. So, for some rotation by $$$k$$$ ($$$0 \leq k < n$$$), we can express the tastiness as
Each sum can be calculated for all $k$ simultaneously with fast correlation, which we can solve using FFT. Then, we can find the answer by taking the maximum of this expression over all $$$k$$$.
More information about fast correlation can be found here: link.






what is generalized pigeonhole principle? you mentioned it but didn't provide any further references.
The base pigeonhole principle states that if we have $$$n$$$ objects and $$$m$$$ boxes where $$$n > m$$$, then at least one of the boxes has more than one item. The generalization is that at least one box has $$$\lfloor n / m \rfloor$$$ items for any value of $$$n$$$ and $$$m$$$.
I think there's a typo in the solution for H. It should be x-i+k-1 choose k-1. Or x-i+k-1 choose x-i
Hi, great catch! We had written this formula with $$$i$$$ being 0-indexed, as it was in our code. The formula you gave is correct when $$$i$$$ is 1-indexed, which would be consistent with the rest of the solution.
A solution that doesn't involve hasing for K is using eertree. You only add to the answer when you create a new node on the tree