


Hi everyone!
Recently, I came across two CSES problems, Company Queries I and Company Queries II. And I had an unusually simpler approach for both of the problems, which doesn't use binary lifting or LCA algorithms, rather it uses binary search on the levels of the tree
Recap
- An ancestor of node $$${X}$$$ is node $$${Y}$$$, where node $$${X}$$$ is contained within the sub-tree of node $$${Y}$$$ (downwards)
- The LCA (lowest common ancestor) of nodes $$${A}$$$ and $$${B}$$$ is the nearest node which have $$${A}$$$ and $$${B}$$$ in its sub-tree
Company Queries I
The algorithm described here needs $$$O(N\log N)$$$ for preprocessing the tree, and then $$$O(\log N)$$$ for each query
Here's the step by step algorithm to get the $$$k$$$-th ancestor of a node:
- use depth-first search on the tree, and assign each leaf node an arbitrary increasing index (unique for all leaf nodes)
- in the dfs function, keep track of the maximum index the current node covers, and store it for every node
- use breadth-first search, and assign for each node the level in which it's in. Also for every level, add the nodes contained in that level and sort them by the maximum index they cover
- for every query of the form "what is the $$$k$$$-th ancestor of node $$$X$$$" we will get the level in which our answer is in simply as
- if $$$lvl$$$ is below 1, means it's an invalid level. Otherwise, binary search in that level on the node that contains the maximum index that node $$$X$$$ covers
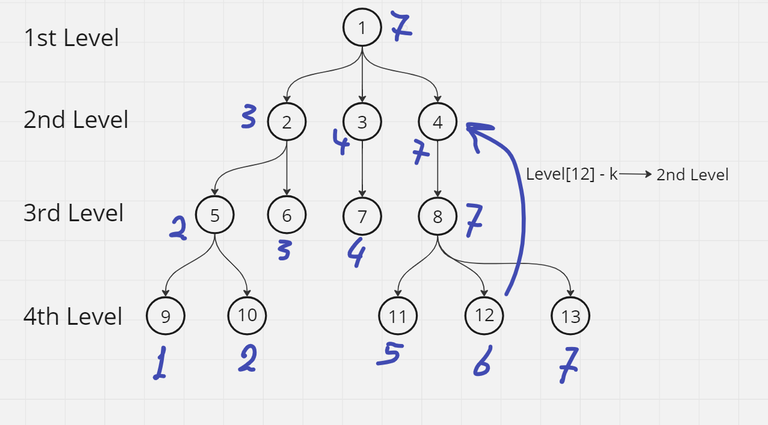
Here is an image to help you visualize how the algorithm works, the number written beside each node is the maximum index it covers in its sub-tree. in this image we query on node $$$12$$$ and $$$k = 2$$$, so we go back to the second level, then binary search on the node that covers the index of node $$$12$$$ which will be node $$$4$$$ in this case
Here's the code for $$$k$$$-th ancestor of a node:
Company Queries II
The algorithm described here needs $$$O(N\log N)$$$ for preprocessing the tree, and then $$$O(\log^2 N)$$$ for each query
This problem wants us to find $$$LCA(A, B)$$$. This algorithm does mostly as the previous one did, here's what we'll change:
- for every node, store the maximum index it covers and also the minimum index it covers
- for each query, identify the range of indices they cover as: $$$X$$$ covers from $$$mn1$$$ to $$$mx1$$$ and $$$Y$$$ covers from $$$mn2$$$ to $$$mx2$$$
- binary search on all the previous levels, and binary search inside the current searched level on whether there is a node that covers from $$$mn1$$$ to $$$mx2$$$ (covers all the range that $$$X$$$ and $$$Y$$$ covers)
- if we find a node that satisfies this condition, save it and search in deeper levels, else, go search up the tree
Here's the code for $$$lca(a, b)$$$:
Conclusion
These algorithms run in time complexities worse than the standard LCA and binary lifting algorithms but just optimized to be accepted as a solution. As we store a tree level's information we can use binary search to construct a simple beginner-friendly solution for these two problems without the kind of complicated LCA and binary lifting algorithms






