


Round1
Problem B
The critical observation in this problem is that the points will be at the corners or very close to the corners. After that one simple solution would be to generate a set of all the points that are within 4 cells from some corner, and consider all quadruplets of points from that set.
Problem C
When the magician reveals the card, he has 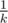 chance to reveal the same exact card that you have chosen. With the remaining
chance to reveal the same exact card that you have chosen. With the remaining 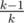 chance he will reveal some other card. Since all the cards in all m decks are equally likely to be in the n cards that he uses to perform the trick, he is equally likely to reveal any card among the n × m - 1 cards (-1 for the card that you have chosen, which we assume he has not revealed). There are only m - 1 cards that can be revealed that have the same value as the card you chose but are not the card you chose. Thus, the resulting probability is
chance he will reveal some other card. Since all the cards in all m decks are equally likely to be in the n cards that he uses to perform the trick, he is equally likely to reveal any card among the n × m - 1 cards (-1 for the card that you have chosen, which we assume he has not revealed). There are only m - 1 cards that can be revealed that have the same value as the card you chose but are not the card you chose. Thus, the resulting probability is 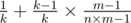
Problem D
One way to solve this problem is to maintain three deques, one per machine type, each one containing moments of time when the machines of this type will be available in increasing order. Originally each deck has as many zeroes, as many machines of that type are available. For each piece of laundry, see the earliest moment of time when each of the three machines will be available, and chose the time to put it in a washer in such a way, that there will be no delay when you move it to the dryer and to the folder. Remove the first elements from each of the deques, and push back moments of time when the piece of laundry you are processing is washed, dried and folded correspondingly. It can be shown that by doing that you will maintain all the deques sorted.
Problem E
This problem requires one to use one of the datastructures, such as suffix array, suffix tree or suffix automata. The easiest solution uses a compressed suffix tree. Build one suffix tree on all three strings. For simplicity add some non-alphabetic character at the end of each string. For every node in the tree store how many times the corresponding suffix occurs in each string. Then traverse the tree once. If the tree had no shortcuts, for every node that is a characters away from the root you would have increased the answer for a by the product of numbers of occurrences of the suffix in each of the strings. Since you do have shortcuts, you need to update the answer for all the lengths from a to b, where a and b are the distances of two ends of the shortcut from the root. One way to do it with constant time updates and linear time to print all the answers is the following. If the array of answers is v, then instead of computing v we can compute the array of differences p, such that pi = vi - vi - 1. This way when you traverse the shortcut, rather than adding some value at all the positions from a to b, you only need to add that value at position a, and subtract it at position b. When p is computed, it is easy to restore v in one pass.
Problem F
There are at least two different ways to solve this problem
First way is to notice that almost all the permutations have such numbers a and b. Consider solving the opposite problem: given n, build a permutation such that no subsequence of length 3 forms an arithmetic progression. One way to do that is to solve similar problem recursively for odd and even elements and concatenate the answer, i.e. solve it for  , and then form the answer for n as all the elements of the solution for multiplied by two, followed by those elements multiplied by two minus one. This way we first place all the even numbers of the sequence, and then all the odd or vice versa.
, and then form the answer for n as all the elements of the solution for multiplied by two, followed by those elements multiplied by two minus one. This way we first place all the even numbers of the sequence, and then all the odd or vice versa.
Now one observation that can be made is that all the permutations that don’t have a subsequence of length 3 that is an arithmetic progression are similar, with may be several elements in the middle being mixed up. As a matter of fact, it can be proven that the farthest distance an odd number can have from the odd half (or even number can have from the even part) is 6. With this knowledge we can build simple divide and conquer solution. If n < = 20, use brute force solution, otherwise, if the first and the last elements have the same remainder after division by two, then the answer is YES, otherwise, assuming without loss of generality that the first element is odd, if the distance from the first even element to the last odd element is more than 12, then the answer is YES, otherwise one can just recursively check all the odd elements separately, all the even elements separately, and then consider triplets of numbers, where one number is either in the odd or even part, and two numbers are among the at most 12 elements in the middle. This solution works in nlog(n) time. Another approach, that does not rely on the observation above, is to consider elements one by one, from left to right, maintaining a bitmask of all the numbers we’ve seen so far. If the current element we are considering is a, then for every element a - k that we saw, if we didn’t see a + k (assuming both a - k and a + k are between 0 and n - 1), then the answer is YES. Note that a - k was seen and a + k was not seen for some k if and only if the bitmask is not a palindrome with a center at a. To verify if it is a palindrome or not one can use polynomial hashes, making the complexity to be n × log(n).
Round 2
Problem A
The important observation one needs to make is that qn = qn - 1 + qn - 2, which means that we can replace two consecutive ‘1’ digits with one higher significance digit without changing the value. Note that sometimes the next digit may become more than ‘1’, but that doesn’t affect the solution.
There are two different kinds of solutions for this problem
The first kind of solution involves normalizing both numbers first. The normalization itself can be done in two ways — from the least significant digit or from the highest significant one using the replacement operation mentioned above. In either we will need O(n) operations for each number and we then just need to compare them lexicographically.
Other kind of solutions compare numbers digit by digit. We can start from the highest digit of the numbers, and propagate them to the lower digits. On each step we can do the following:
If both numbers have ones in the highest bit, then we can replace both ones with zeroes, and move on to the next highest bit.
Now only one number has one in the highest bit. Without loss of generality let’s say it’s the first number. We subtract one from the highest bit, and add it to the next two highest bits. Now the next two bits of the first number are at least as big as the first two bits of the second number. Let’s subtract the values of these two bits of the second number from both first and second number. By doing so we will make the next two bits of the second numbers become 0. If first number has at least one two, then it is most certainly bigger (because the sum of all the qi for i from 0 to n is smaller than twice qn + 1). Otherwise we still have only $0$s and $1$s, and can move on to the next highest bit, back to step (1). Since the ordinal of the highest bit is now smaller, and we only spent constant amount of time, the complexity of the algorithm is linear.
Problem B
One of the optimal strategies in this problem is to locate a node a with the most rows, then move all the data from the cluster a does not belong to onto a, and then for every other node b in the cluster that a belongs to either move all the data from b onto a, or move all the rows from the other cluster into b, whichever is cheaper.
Problem C
First let’s consider a subproblem in which we know how many votes we will have at the end, and we want to figure out how much money we will spend. To solve this problem, one first needs to buy the cheapest votes from all the candidates who have as many or more votes. If after that we still don’t have enough votes, we buy the cheapest votes overall from the remaining pool of votes until we have enough votes. Both can be done in linear time, if we maintain proper sorted lists of votes. This approach itself leads to an O(n2) solution. There are two ways of improving it. One is to come up with a way of computing the answer for k + 1 votes based on the answer for k votes. If for each number of votes we have a list of candidates, who have at least that many votes, and we also maintain a set of all the votes that are available for sale, then to move from k to k + 1 we first need to return the k-th most expensive vote for each candidate that has at least k votes (we had to buy them before, but now we do not have to anymore) back into the pool, and then get that many plus one votes from the pool (that many to cover votes we just returned, plus one because now we need k + 1 votes, not k). This solution has nlogn complexity, if we use a priority queue to maintain the pool of the cheapest votes. In fact, with certain tweaks one can reduce the complexity of moving from k to k + 1 to amortized constant, but the overall complexity will not improve, since one still needs to sort all the candidates at the beginning.
Another approach is to notice that the answer for the problem first strictly decreases with the number of votes we want to buy, and then strictly increases, so one can use ternary search to find the number of votes that minimizes the cost.
Problem D
The score function of a board in the problem is 2x, where x is number of rows and columns fully covered. Since 2x is the number of all the subsets of a set of size x (including both a full set and an empty set), the score function is essentially the number of ways to select a set of fully covered rows and columns on the board. The problem reduces to computing the expected number of such sets. For a given set of rows R and a given set of columns C we define pR, C as a probability that those rows and columns are fully covered. Then the answer is 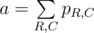 . For two sets of rows of the same size r and two sets of columns of the same size c the value of pR, C will be the same, let’s call it qr, c. With that observation the answer can be computed as
. For two sets of rows of the same size r and two sets of columns of the same size c the value of pR, C will be the same, let’s call it qr, c. With that observation the answer can be computed as 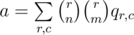 . qr, c in turn is just the probability that n(r + c) - rc numbers on the board are chosen from the k numbers that were called, and the remaining (n - c)(n - r) numbers on the board are chosen from the remaining m - (n(r + c) - rc) numbers available.
. qr, c in turn is just the probability that n(r + c) - rc numbers on the board are chosen from the k numbers that were called, and the remaining (n - c)(n - r) numbers on the board are chosen from the remaining m - (n(r + c) - rc) numbers available.
Problem E
Let’s begin by considering an arbitrary cycle in the given graph (if one exists). We could add some amount of flow to each edge in the cycle, and doing so must result in an equivalent or worse cost (otherwise the intern’s solution would clearly be non-optimal). Thus if we consider the function c(x) = sum(w_i * (f_i + x)^2), it should be minimized at x=0. Since this function is continuous, a necessary condition is c’(0) = 0. This implies sum(w_i * f_i) = 0 for any cycle.
Let us denote w_i * f_i as the “potential” of an edge. We can define the potential between two vertices in the same connected component as the sum of the potentials of the edges along any path between them. If the potential is not well defined, then the intern’s solution is not optimal. Additionally, the potential from node 1 to any other node must be positive (It cannot be zero because the original graph is biconnected), and similarly the potential from any node to node N must be positive. Furthermore no potential can exceed or equal the potential between node 1 and node N (if they are connected). These conditions can be verified in linear time using a dfs, allowing us to binary search the answer in O(N log N). Alternatively, the union-find algorithm can be modified to track potentials as well as components.
The true nature of the problem is revealed by making the following replacements:
weight -> resistance
bandwidth -> current
cost -> power
potential -> voltage
The problem asks you to determine if the given currents in a resistor network are optimal.
Problem F
The solution for this problem is a dynamic programming on a tree with O(n) complexity.
In this editorial “even tree” means a tree in which players will make an even number of turns, while “odd tree” is the tree in which players will make an odd number of turns.
We will be solving a slightly modified problem: one in which all the numbers on the leaves are $0$s and $1$s. Once this problem is solved, the general problem can be solved by doing a binary search on the answer, and then marking all the leaves with higher or equal value as $1$s, and all other values as $0$s.
If the tree is an odd tree, then the first player makes the last turn, and it is enough that at that moment only one of the two children of the root is 1. If the tree is an even tree, then the second player makes the last turn, so for the first player it is critical that by that time both children of the tree are 1 if he wants to win.
One simple case is the case when the tree is an odd tree, and both its immediate subtrees are even trees (by an immediate subtree, or just “subtree‘ of a node, here we will mean a subtree rooted at one of the nodes' immediate children).
In this case we can recursively solve each of the immediate subtrees, and if the first player wins any of them, he wins the entire tree. He does that by making his first turn into the tree that he can win, and then every time the second player makes a turn in that tree, responding with a corresponding optimal move, and every time the second player makes a turn in the other tree, making a random move there.
If both immediate subtrees are odd trees, however, a similar logic will not work. If the second player sees that the first player can win one of the trees, and the first player already made a turn in that tree, the second player can force the first player to play in the other tree, in which the second player will make the last turn, after which the first player will be forced to make a turn in the first tree, effectively making himself do two consecutive turns there. So to win the game the first player needs to be able to win a tree even if the second player has an option to skip one turn.
So we will need a second dimension to the dynamic programming solution that will indicate whether one of the players can skip one turn or not (we call the two states “canskip” if one can skip a turn and “noskip‘ if such an option does not exist). It can be easily shown, that we don’t need to store how many turns can be skipped, since if two turns can be skipped, and it benefits one player to skip a turn, another player will immediately use another skip, effectively making skips useless.
To make the terminology easier, we will use a term “we” to describe the first player, and “he” to describe the second player. “we can win a subtree” means that we can win it, if we go first there, “he can win a subtree” means that he can win it if he goes first (so “if one goes first” is always assumed and omitted). If we want to say that “we can win going second”, we will instead say “he cannot win [going first]” or “he loses [going first]”, which has the same meaning
Now we need to consider six cases (three possible parities of children multiplied by whether one can skip a turn or not). In all cases we assume that both children have at least two turns in them left. Cases when a child has no turns left (it is a leaf node), or when it has only one turn left (it is a node whose both children are leaves) are both corner cases and need to be handled separately. It is also important to note, that when one starts handling those corner cases, he will encounter an extra state, when the players have to skip a turn, even if it is not beneficial for whomever will be forced to do that. We call such state “forceskip”. In the case when both subtrees have more than one turn left, forceskip and canskip are the same, since players can always agree to play in such a way, that the skip, if available, is used, without changing the outcome. Below we only describe canskip and noskip cases, in terms of transitions from canskip and noskip states. One will need, however, to introduce forceskip state when he handles corner cases, which we do not describe in this editorial. The answer for forceskip will be the same as the answer for skip in general case, but different for corner cases.
even-even-noskip: the easiest case, described above, it is enough if we win any of the subtrees with no skip.
even-even-canskip: this case is similar to a case when there’s one odd subtree and one even subtree, and there’s no skip (the skip can be just considered as an extra turn attached to one of the trees), so the transition is similar to the one for odd-even-noskip case described below. We win iff we can win one tree with canskip, and he cannot win the other with noskip.
odd-even-noskip: if we can win the odd tree without a skip, and he cannot win the even tree without a skip, then we make a turn into the odd tree, and bring it into the even-even-noskip case, where he loses both trees, so we win. The other, less trivial, condition under which we win is If we can win the even tree with canskip, and he can’t win the odd tree with canskip. A motivation for this case is that odd subtree with a skip is similar to an even subtree, so by making a turn into the even case, we bring our opponent to an odd-odd case, where he loses both threes with a skip, which means that no matter which tree he makes a turn into, we will be responding to that tree, and even if he uses another tree to make a skip, he will still lose the tree into which he made his first turn. Since we make the last move, we win.
odd-even-skip: this is a simple case. We can consider the skip as an extra turn in the odd subtree, so as long as we can win even subtree with no skip, or odd subtree with a skip, we win.
odd-odd-noskip: we need to win either of the subtrees with a skip to win.
odd-odd-skip: to handle this case we can first consider immediately skipping: if he loses noskip case for the current subtree, then we win. Otherwise we win iff we can win one of trees with a skip, and he can’t win the other without a skip.
The more detailed motivation for each of the cases is left as an exercise.







I can't believe what I'm seeing, I had already lost hope!
Better late than never :) Thanks for the editorial!
Can someone please explain how ternary search is applicable in the question "ELECTIONS" ...
For problem 452E,can I ask we solve it with suffix array or suffix automaton?
First make a suffix array of the concatenated string.
Now, Observations and Algorithm:
Consider l->r suffixes in SA which have a common prefix of length L. Now to calculate the number of triplets we need to know the number of suffixes which belongs to S1, S2, S3. You can know if a suffix belongs to string i [1,2,3] part using Suffix array information. Using Cumulative sum array on this information , we can compute number of suffixes belonging to ith string in O(1) time. Say, a , b and c is that number. Then, number of triplets will be a*b*c. [this is calc() in my code]
Number of common substrings of length < L is atleast the number of common substring of length L. With this we can compute our answer in non-increasing order [L = maxn-1 --> 1 in my code] and ans[] will be a decreasing function.
My AC Code implementing same Algorithm.
Feel free to ask if anything is not clear.
A corollary of what is mentioned in the editorial makes the implementation much easier. Only check pairs of indices if they are $$$\le 15$$$ apart.
How to prove that this actually works? That is, how to prove that if they're > 15 apart, it doesn't matter.
In round 2 problem C, how to prove that the cost function is convex?