


You'll be given an Array of N elements and Q queries.
Here N and Q is a non-negative integer and maximum value of N and Q is 100000.
There are two types of query.
One is : 1 P V , this means that you have to change P-th element of the array to V.
Another is : 2 L R X , this means that you have to output the number of elements less than or equal to X in L to R range of the array.
How can I solve this problem? I know the solution if there is no update operation. But this problem contains update operation.
Thanks in Advance. :)







There is a solution with treap in every node of segment tree
Could you please describe in brief?
A solution is sqrt decompress. Let divide array into sqrt(N) blocks. Then sort each of blocks. Complexity O(Q * sqrt(N) * log(N) / 2). Using fenwick2d we can reduce complexity into O(Q * sqrt(N) + Q * log(N)^2) per query.
Use a persistent segment tree to maintain the initial configuration while use a BIT or segment tree to maintain the modification of persistent segment tree (notice that each modifcation is first substrcation of value of specific index in a prefix of segment trees represented by the persistent segment tree, then an addition). O(NlgN+QlgNlgN)?
could you please elaborate more on the segment tree used to store the modifications ?
How to handle updates?
Can anybody please help me out here :(
Is it even possible to handle updates with persistent segment tree? Nezzar
Can't this question be done simply using merge sort tree?
link to the problem please
There is an online solution working in O(log^2(N) per query, this should be enough if the time limit is not strict.
You can answer how many values are less than X in a binary search tree (BST) in O(logN), so create a segment tree where each node contains a BST, if the node covers interval [L, R] the BST contains all values in the interval [L, R].
To update a value just remove the old one and insert the new one in each BST in the path from leaf to root of segment tree.
To query how many values are less than X just do a query to each BST in the range (there are upto logN).
BST in every node? but what is memory complexity?
NlogN, because in every layer(depth) of segment tree you have all N elements exactly once. Segment tree depth = logN, so total memory is NlogN
Excuse me for noob question
but how does the merge between two binary search trees work ?
i mean besides the obvious way of taking every node from one tree and inserting it to the other
OK, I'll try to explain it.
Let's keep a treap in every node
vof segment tree. This treap will contain all elements from range[l..r]— the range which nodevis responsible for.How to add(on building stage) or modify element at position
idx? Let's find all nodes which haveidxin their range(it meanstl <= idx <= tr; wheretl,tr— borders of segment which current node is responsible for) — it is just all nodes in the path from root to some leaf withtl = tr = idx. Let's add given value in all treaps of these nodes. It is easy to modify element — just erase old values from all these treaps and then add new. Asymptotics for adding / modifying isO(log^2N):logNlayers and adding number in the layer is alsologN.How to answer for a query
l, r, x? Just do everything you have done in a usual segment tree, but for a query in some node which is fully contained in[l..r]the answer is a number of elements less thanxin this treap. Asymptotics is alsoO(log^2N)—logNnodes withlogNfor answering in every nodeSo, it is
O(Nlog^2N)for building,O(log^2N)per any query andO(NlogN)of memoryAs you could understand it is no need to merge sons' treaps(as you said)
Why treap instead of bst ? I don't know a treap data structure, but I think that it might work using bst
I like treaps and don't like BST :)
Thank you so much !!
the whole time i was trying to build from the bottom up the whole array together
inserting element by element didn't cross my mind
if not much trouble do you have any source for self balancing BSTs or treaps ?
can u give me some treap problem in codeforces
Try problem E in contest 367. It's not the official solution, and may not pass all tests due to memory and / or time, but it can be done.
Why so many down votes ? It's really interesting problem. Please provide a link to this problem
A similar problem just different a bit, but it's in Vietnamese: http://www.spoj.com/problems/KQUERY2/vn/
english version — http://www.spoj.com/problems/KQUERY2/en/ ;)
how can I solve it if there are updates for ranges?
chemthan's idea can be extended to range update and query and will work in O(N*log(N)*sqrt(N)). The difference is that you'll need a segment tree with lazy for range update in each bucket.
chemthan's solution or kefaa's solution ?
can you tell me the solution when there are no updates?
I am also interested.
merge-sort tree
I think I have an idea for an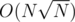 solution. It should be quite similar in speed to O(Nlog2N).
solution. It should be quite similar in speed to O(Nlog2N).
First there exists a method to maintain an array of size 100000 with update to change number at a position, and O(1) query sum within range. We can do this by splitting this array up into blocks and maintaining cumulative sums within and over these blocks. This allows us to keep track of how many things less than X are in here. Keep in mind this structure is secondary and is separate from our actual array.
update to change number at a position, and O(1) query sum within range. We can do this by splitting this array up into blocks and maintaining cumulative sums within and over these blocks. This allows us to keep track of how many things less than X are in here. Keep in mind this structure is secondary and is separate from our actual array.
Now, let's split the actual array into blocks. Each blocks holds the above structure. When we update a position, we look at the block that it is in and update it. Specifically, if we change it to some value, we update the count in the structure described. This is an
blocks. Each blocks holds the above structure. When we update a position, we look at the block that it is in and update it. Specifically, if we change it to some value, we update the count in the structure described. This is an  update.
update.
Now to query, we look at all the full blocks contained in the range and query each in O(1). As there are max blocks, this is
blocks, this is  total query. Next, we count each of the extra positions within the range which aren't in a full block. This is also
total query. Next, we count each of the extra positions within the range which aren't in a full block. This is also  because each block has size
because each block has size  .
.
Thus we have a solution with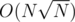 which can be easier than treap+segtree, and possibly faster due to treap constant factor.
which can be easier than treap+segtree, and possibly faster due to treap constant factor.
Edit: oops I didn't realise this thread was dead >.<
How are you going to get the answer for a single block in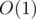 time?
time?
So in the first structure which I described we can get O(1) query by maintaining a prefix sum array. We keep 1. prefix sum array inside each block 2. prefix sum array over the blocks. Every time we update we can afford O(sqrt) operations so we update the cumulative sum array inside the block, and also over all the blocks (both sqrt operations).
Now to query, we look at sum of all full blocks inside range in O(1) using prefix sum. Next, we look at sum within partial blocks using prefix sum and get the value in O(1).
This allows us to keep track of how many things less than X are in here.How can you use the prefix sums to figure out how many things less than X there are, when X is changing every query?
I'm not sure what you're asking... A regular prefix sum let's you query for every X anyway — this system is no different. You just query twice, once for big blocks, once for a partial block.
I think he doesn't understand how to query in O(1) using prefix sums. I don't understand too. How about ordering each block and use binary search to find numbers less than x? Query-O(sqrt(N)×logN) Update-O(logN). Is it too much?
nice solution
Nice solution.
alternatively, couldn't you just store an ordered_set (from gnu pbds namespace) in each node of the segment tree?
you can use segment tree or sparse table to solve it
Can you explain a bit? Thanks
there is a solution with Merge Sort Tree.
https://discuss.codechef.com/questions/94448/merge-sort-tree-tutorial
This problem is almost same as SPOJ : Giveaway.