


Hi everyone!
Codeforces Round #373 (Div. 1 + Div. 2) will take place on 23 September 2016 at 16:05 MSK. Please note that the timing is unusual.
This time tasks for you were prepared by me (Matvey Aslandukov) and my brother _XuMuk_ (Andrew Aslandukov). It is our first codeforces round and we hope you'll enjoy it. We want to say special thanks to Seyaua (Ievgen Soboliev), AlexFetisov (Alexandr Fetisov) and winger (Vladislav Isenbaev) for testing the problems, GlebsHP for his help with the contest preparation, and MikeMirzayanov for the excellent platforms Polygon and Codeforces.
Coincidentally, the date of the round falls on my birthday, so I am very happy that I can spend that day surrounded by our friendly community :)
There will be five problems and two hours to solve them. Traditionally, the scoring distribution will be announced later.
Good luck!
UPD1:
Scoring:
Div. 2 : 500 1000 1500 2250 2250
Div. 1 : 500 1250 1250 2000 2500
The problems are sorted by difficulty but as always it's recommended to read all the problems.
UPD2:
Contest complete! Thank you all for participating :)
Unfortunately, as noted Um_nik, many solutions of div.1 B task, including the author's, were incorrect. Now we are working on this problem. If we still manage to find the right solution and answers on pretests will be the same, the round may be rated. Otherwise, it will be unrated.
Thus final results significantly delayed. We apologize for the situation. If you have thought about the correct solution — write to us.
UPD3:
We made a decision to start system testing with the current solutions and tests. The question will be round either rated or not is still opened.
UPD4:
After considering different option and estimating their pros and cons, Codeforces team decided that the main factor to make a decision on whether the round should be rated or not is how much the bug affected the results.
In the second division, only two participants managed to implement the correct greedy algorithm for the original incorrect version of the problem D, thus we consider the effect of this problem on the final standing to be negligible. The contest for division two will be rated.
Things are very different for division one, as there were plenty submission to problem B and problems B and C took the most part of participants worktime during the contest. Assuming this fact we suppose that this bug affected the final results a lot and there is no way to consider its influence on each particular participant. As a result, the contest for division one will be unrated.
The only thing left to do is to apologize to the participants. We will do our best to avoid such situations in the future.
UPD5:
Congratulations to the winners!
Div.1:
Div.2:
Editorial is ready!







Happy birthday BigBag
Big like for your phrase! CF :
our friendly commiunity :)and Big like for your reason of happiness! :I am very happyhappy big birthday. ;)a unrated contest on your birthday! :D hope to see contests on next birthday of your life! :D
how many times do you submit it?)
oh! there is a problem in judge! correct! :D
Why is the timing unusual? Quite early for working day.
ah...For us is at 9:05 PM..It seems much better than 00:35 AM as usual……
If it could be delayed it would be better
I hope that this becomes the usual time, or at least please hold more contests at this time, so that my students can participate. The usual time 12:35am — 2:35am local time is too late for them.
I totally agree with your idea too. The usual time (1:35am — 3:35am) is definitely harsh time to participate for our country. I'll be really appreciated if there are more chances to join contests for other time-zone coders:)
Obviously in such a situation, there simply cannot be a fixed time that suits everybody. What would you do in such a situation? Definitely set a time that suits a majority. Some people have to face the circumstances because of low participation from that area and different time zone.
You should rotate starting times, not pick a time that always screws the minority.
Duh, last contest was 6:35 AM for me and this is 6:05 AM, things are getting worse :P.
Contest will start at 20:05 UTC+7 in my area. Best time for me (y) . Happy Birthday, man!
tomorrow is also my birthday,a good time of the contest,it will start at 21:05,at the end of birthday,i can enjoy the contest.thank you for preparing the contest.
Happy Birthday, byene :)
I hope, you'll get a lot of enjoy. Happy Birthday!!!
Contest will start at 21:05 UTC+8 in my area.So I can spend at most 5 minutes on road.
The only good thing of being a Syrian, is as much as the timing is unusual, It's always great in here :D
Something is wrong with the registration. Number of registrants there and there are diferent. + my registration was cancelled.
I think you should reload both pages to get it fixed. It is OK!
Happy Birthday BigBag . Waiting for your dishes.! :)
This is Codeforces
.
Happy birthday.
BigBag Many many happy returns of tomorrow like tomorrow! :)
Many Happy returns of the day.
Wow, now even wishing someone is wrong too(go on don't be shy downvote this too).
Double Comments post.
Happy Birthday BigBag.
Happy Birthday, BigBag!
Happy Birthday Matvey Aslandukov[user:bigbag]!!!!!
GLHF
Happy Birth Day, hope the problem will be amazing as your birthday gifts :D
We want your birthday treat by easy problems to solve and good ratings. And Happy Birthday to you BigBag.
As a Chinese student, late Codeforces round make my routine little bit hactic...Thank U so much for choosing such a nice time for the contest.. Hoping to gear some of my rating points and wish everyone a high rating~~ :) and happy birthday BigBag
happy birth day, bigbag
Happy B'day.. BigBag
HBD BigBag :)
Happy Birthday Dude !!!
Happy Birthday, BigBag! :)
It is my birthday too Happy birthday to BigBag and me Wish everyone can have a good rating after the contest (Ps:The time is very good)
Happy birthday :D
Where is the dishes ? :P :"D
Great timing! Wish everyone many accepted solutions, and happy birthday BigBag :)
You are advised to read all the problems :D
Happy Birthday BigBag! :P
So where is the scoring distribution?
Do I get rated if I have registered for this contest, but I'm not able to participate due to unstable internet connection?
If you didn't submit anything, then you rating is not affected.
Problem A's pretests are so so weak!
Why Q, why!
submission in queue , it's been more than 5 minutes
It seems the judge server is even down now...
it seems BigBag is celebrating his birthday right now
What happened to the compiler? Submissions are in queue for almost 10 minutes already :(
LOL I've been watching the Status page for >10 minutes and NOT A SINGLE QUEUE has been processed????? :)
in queue for 10 min !!
Same here!
its working now
Thank you for weak pretest in Div2. A. It feels amazing to hack people :D :)
[del]In queue! What is wrong?[/del] It seems to be fixed, thanks.
I have nothing against hacks on Codeforces, but when problems div2 A or B have so weak pretests, solving problems pales into insignificance. As I think, solving skill should matter more in final standings than hacking skill. So pretests for problem A shouldn't be as weak as we see.
I agree. It would be nice if the system had a limit of hacks on a specific problem, so people wouldn't climb the rank so high because of silly details.
or a hack limit for each contestant, in my room the first guy had 19 hacks !!! and left no chance for others to hack :(
That's a great idea.
because some people (like the guy in your room) gets 19 hacks and the solve A and take about 500 points that's 2400 it's like solving E at the start of the contest that's not fair to take 2400 points form only div2 A.
that way the contests will be better and nobody will get to the top only from hacking.
Maybe a reducing function of hack points with number of successful hacks for each problem...
It is about 20 pages of submissions in queue now!!
There is a mistake in the announcement. Problems are not sorted by difficulty :)
Needless to argue.
BigBag's Birthday is a HACK day!!
I had to resubmit 11 times in C until I noticed pretest 6 had really large number before . :/ rip 550 points
So many people solved Div.2 E. Weird, looks completely unsolvable to me :D
Div.2 E is a great problem. You can consider the well-known method to calculate large Fibonacci Numbers , i.e., Matrix multiplication with doubling acceleration.
Let the first matrix being A, second matrix being B, then you will get fi by ABi.
You can build a segment tree maintaining the matrix B (or matrix AB, as you like).
When facing the update query, simple commit an interval update — multiplying Bk to the corresponding interval of each segment tree node. Multiplying a single number into a certain interval is not a hard job, then multiplying a matrix into a certain interval will not be hard either. ( You should use lazy marking technique to make your amortized time complexity O(log(n))).
When facing the sum query, simple extract the interval sum of matrix B (or simply AB, if you decided to maintain it rather than B) from segment tree and you are done.
How do I use the lazy marking technique on a range? This matrix multiplication works only on single values, not sum of values, right?
Hope this snippet helps.
ls --> left son, rs --> right son
lz is the lazy mark, update ready to pass to son.
t is the segment tree node saving matrix AB
init1(); is the function to put a matrix into identity matrix.
Segment tree is maintaining a sum of ABi, which is equivalent to the sum of fi (simply extract the [0][0] item of the matrix).Multiplying a matrix to such sum is okay due to the associative rule of matrix multiplication.
Here is a good article, explaining segment tree, at codeforces
Given that fib(ai) = Aaiv where:
You can use it this way:
First, the sum of fib(ai) in a range [l, r] can be seen as:
Now, fib(ai + x) is the same as (Aai + x)v, which is the same as
fib(ai + x) = (AaiAx)v
Now in order to add some value x to a range [l, r] :
So, you can use lazy propagation storing the Ax in each node of your segment tree, and pushing it to the children of each node when needed!
Great explanation !
You can use the following property of fibonacci numbers and this property can be used to solve the problem using segment tree with lazy propagation.
Fib(x + y) = Fib(x + 1) * Fib(y) + Fib(y - 1) * Fib(x)
DIV1 C is very well-known!
Was this Fibonacci property shifting F(m+n) = f(m+1)f(n) + f(m)(f(n-1)) used in Div2 E along with segment tree in O(n logn * logn) I had kind of idea but failed to implement in time.
Yep, exactly, consider the fibonacci matrix-vector multiplication:
{sorry I don't know how to write in latex}
([[1,1],[1,0]]^n)*[F(m+1),F(m)]=[[F(n+1),F(n)],[F(n),F(n-1)]]*[F(m+1),F(m)]=[F(m+n+1),F(m+n)]
since this operator is linear you can use it to update any segment range (I'll proof it later).
By the way, the optimal complexity is O(n*log(n)), in each query you can just compute the matrix expo once, and use it to update segment tree.
Yes. This was the property I was using. Successfully implemented it 7 minutes before the end. Idea was to store summation of F(ai) and summation of F(ai + 1) in segment tree.
But Sublime didn't let me submit because it couldn't fucking detect
+query(1,1,n,l,r);as a compilation error.
Where did you know about it?
I think it's subjective, for some people (including me) think this problem is well known, If you familiar with fibonacci, and multi data segmentree, for example this SPOJ-SEGSQRSS problem, then it's just a matter of coding skill (silly bug can hurt).
No.. No.. Sorry for being not clear enough but it seemed that you get me wrong :))
I just wanted to check if he learnt it from any books, tutorials... and if yes, then ask for recommendation :p
For B div1 problem, does O(nmlg) pass the pretests? is there any better solution?
I have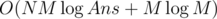 I believe.
I believe.
I have no idea how to prove that it can run faster than that. See this
Now i understand my O(nmlg) solution can be easily implement in O(MTlg^2) that T is max(ti).
Are you sure? Because not all machines(with same values of t) will start working at same moment.
the second lg is for that!
save all times they starts working after that all n machines filled for each t, so you can understand easily by a binary search that how many copy they will make after T seconds.
I don't think, that it will pass, my O(MTlog(ans)) works in 3s.
it is just: 2000 * 1000 * log2(1e13) * log2(2e5) ~ 2e9.
4 seconds will be about 3e9/4e9.
You forgot about % and / operations, which are too heavy for 2e9
I don't understand this. Many (Most, infact) of accepted solutions (.. so far) are NMlog(1e12) itself. But mine failed :(
Sad but true: I believe that mine works in O(nm), but it is too slow as the constant is quite big. I use nm divisions and O(nm) push_backs into vector and I have absolutely no idea how to optimize it. It works 6.5 seconds on my laptop on the max test.
See this: 20865418
I think that we can use Parallel Binary Search
I feel like Div. 2 C had really weak pretests. I noticed my two submissions in queue were wrong before they even got judged and they were both pretests passed.
Pretests were supposed to be weak. Otherwise how could we hack? :)
I couldn't lock my submission for more than 10 minutes in the beginning of the contest. How was I supposed to compete against those who could do it?
Is C a segment tree with matrices? Couldn't make it pass till the end... First, I copied my matrix structure from my library and it got MLE #10. Then replaced it with my previously written code with vectors — TLE #11. Then replaced the vectors with arrays and boom — some strange big values on the example test :D :D
I used Binet's Formula and store the numbers as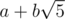 and directly use a segment tree. Unfortunately, it runs in 4.5s on pretests, so RIP. (and I failed some submissions because of a bug in my segment tree -_- )
and directly use a segment tree. Unfortunately, it runs in 4.5s on pretests, so RIP. (and I failed some submissions because of a bug in my segment tree -_- )
Thanks, I knew my math knowledge is very poor! Hope you pass systest :)
I used matrices and slow segment tree, but made precomputations so for each exponentiation I needed only one multiplication. On random maxtests works 3.5s on my laptop.
Also, you can reduce exponents modulo 2000000016.
Finally got it Accepted (I failed system tests :( )
The change I needed was to store the value that I need to multiply with directly and exponentiating before updating the segment tree.
It's enough to store 2 values. But yes, I did all by matrix(2x2) multiplication.
I have always thought that my codes are fast and you passed it in 1.6s, maybe I should stop copying old codes :)
What's the solution of B? nmlog doesn't seem to fit in this time limit.
Group the copiers by processing time; now nmlog is 1000mlog, which passes TL.
how to group the copiers by processing time?
At first you get this problem (by precalcing first n — 1 steps): find min x such that sum{i}{(x + b[i]) / a[i]} >= Y. Then you count this sum not with loop from 0 to n-1, but with loop from 1 to 1000.
what are a and b here? I still can't get how to group them since not all copiers will start working at the same time so I think we should for every query find minimum X such that sum(floor( (X-wait[i])/T[i])) >= number_of_copies_needed
since not all those have same T[i] will have the same wait[i] how can we group them?
UPD: I'm still interested to know how the grouping is done even if the solution is actually wrong :D
For every increase of T[i] in X, number of copies produced increases by exactly one for each machine. The different wait[i]s only matter for the last X % T[i] instants of time, and you can precompute how many copies are produced in those.
Not that this matters anyway, since everyone used a wrong method to calculate wait[i] ¯\_(ツ)_/¯
I've also group the machines for their unit times to produce one copy, then If they ask me for x copies, I just care about for every type machine all the possible reminder between x and unit time of these machines.
This is my code: http://ideone.com/dSHk6e
Precomputation takes: at most 1000*n every query takes aprox : log(10^12)*1000*log(average size of groups)
Group by (t, wait).
what are a and b here? I still can't get how to group them since not all copiers will start working at the same time so I think we should for every query find minimum X such that sum(floor( (X-wait[i])/T[i])) >= number_of_copies_needed
since not all those have same T[i] will have the same wait[i] how can we group them?
Oh... Bar is waiting for me. I tried to do something with right algebraic estimation. But no hacks could help me.(
Ahh so simple!
I got n * ti * log(maxtime), precalc first n possible answers, for another ai make binsearch on time to use. you can do it, because all n xeroxes will be working already and you know all the information about them(how much time for each xerox needed to create next copy).
What was Pretest 4 for Div2 C ?
edit :i guess 3.1617 or something like that ! i too got 2 wa on same !!
Am I supposed to get 3.142 as an answer no matter the value of t ? I got 10 WA on same, so I want to know. :P
Update: I got it.
I am giving up my "blue" color as a present to BigBag. Happy Birthday :P
How to solve Div.2 D?
For div2C check these cases for yourself:
4 1
9.45
4 2
9.45
5 1
1.055
Answers:
Case 1: 9.5
Case 2: 10
Case 3: 1.1
Also:
4 1000000 99.9
Answer is 100
I had to resubmit because of a silly mistake. In 7 4 10.4447 Answer is 11 (Like Second Test of egor.okhterov ) And I became 500 from 160 :((
EDIT: Didn't see post above me until refresh I hacked a couple people with this:
10 1 999.999999
which should just be 1000
failed on
5 1 1.055... Why didn't anyone hack me?Most people's code was atrocious for this question. I had a hard time reading through the ones that clearly didn't round repeating 9s, let alone forgot to check for rounding the leftmost available number first.
Yeah same. The code in my room either looked good or it was too confusing to read (especially since I'm not used to reading c++ code) so I didn't take the risk.
Well, after a second thought and reading Dabagh's comment, I found that my code wasn't wrong, and it was my brain that was wrong.
Seems you were not in my ROOM :P
I got :
9.5 10 1.06
That's correct, right ?
No, in Third one the answer is 1.1 you can round at first digit
Ok, I see. Thanks!
All these testcases work for me but my solution is getting WA on pretest 1.
Why Pixar... My code got WR for your 2 and 3 tests... you ruined my mood :'(
I pass all of these tests, but still got WA on pretest 5 :( Does anybody have any idea what was special about that case? I just can't figure it out... thanks :D
Isn't case 3 = 1.1?
yes, it is 1.1 (or at least it should be)
No ! You are wrong! case 3 is 1.1 that you round at first digit!
Sure, it's 1.1.
I wanted to put answers fast in my comment and made mistake in my own test case ;)
in your case 3 answer should be 1.06 not 1.1
Why do you think so?
during the contest, there was a large queue and it cost 15 min delay in my solution's judgement and unfortunately it gave wrong answer so just a waste of time !Shouldn't this contest be unrated if many others faced the same problem ?
bro same here was attempting E after a and submitted at 1:24 in hope to solve other after that but got wa after about 20 minutes and everything got messed up
It's not the first time.
I think an extension in time would've been a good idea since the queue was clogged after around an hour.
Div1-C: When your solution get WA because you wrote
(re*o.im+im*o.re)instead of(re*o.im+im*o.re)%MOD... I would have a sleepless night if that is the only mistake in my solution...Problem E is so beautiful, kudos to author(s). Let me describe my idea, which should give TLE.
I think I have an O(n·d5) approach where d is the size of the alphabet. From each of n positions I run BFS and for each letter I store its type: 0 if none letter of this type was visited, 1 is some letter was visited, 2 if there was type 1 in the previous turn, and 3 if there was type 2 in the previous turn (thus, these letters affect other letters within distance up to 2). It's possible to maintain types. Moreover, each of n letters belongs to one of 85 groups, defined by letters within distance up to 2 (five letters and alphabet of size eight gives us 85). If I know types of letters, for each group I can say whether all its letters are visited or none are. Btw. this solution calculates the number of pairs for every distance, but likely (?) the intended solution also can do it.
Can someone who solved B say answer to test:
4 1
2 3 3 3
6
Answer is 8.
Also, the answer would be the same for query 7, because at time 8 also machine 4 finishes its copy.
You are wrong. Answer is 7.
Time 2: M1 finishes 1 copy and gives it to M2
Time 4: M1 finishes 2 copy and gives original and copy to M3 and M4
Time 5: M2 fin 3 copy and gives it to M1
Time 7: M1, M3 and M4 fin 4,5,6 copies
My bad, sorry.
I see you got WA. I hope the reason isn't that the intended solution is incorrect.
No, I can't solve it with any complexity (even something exponential) because of this test :)
My solution says 8 too.
I wonder if author's solution is correct :)
Wooooo, nice!
Will organizers solution pass this test? If not, should that round be unrated?
If organizers solution doesn't pass this test (likely), definitely unrated :(
Maybe B should be taken out of the competition and then people should choose what happens with their rating — change or stay the same (if author's solution is wrong, ofc) so that people who solved C/D can get what they deserved.
Then people who solved C/D would compete only against other who solved C/D (ofc. it's a big simplification).
That's completely unfair to the people who devoted time to solve it.
Well, one may argue that this problem is extremely hard so it's your fault to spend much time on it.
Unless the problem setter fixes the solution (I don't mean to disrespect BigBag or dismiss his work preparing problems, but judging by what you, the reds, say, is very unlikely) nullifying its' score is pretty much ignoring everyone's time spent on that question because the setter's solution didn't consider everything.
While not a perfect solution, I think nullifying the score AND reducing the time penalty for every other submission after B (as if everyone who got Pre-AC on B never spent time on it at all), would be the second best option to making the contest unrated.
It won't be fair for them anyway, that's why I suggested that you can choose to have the round unrated, at least it may be a relief.
PS: Errichto, if you are reading this, sorry for not replying, I just didn't understand exactly what your point is. I know B is important in the current standings but still, there is no optimal solution (I mean optimal solution for resolving the mess) for this, I am just suggesting :)
Another possible solution is to make the round unrated for those who think they were affected by this test and for all others change the statement to match the authors solution.
That's precisely what I suggest. You know, why would I claim not to be affected by it when I am about to lose ~100 rating points and how do they really know whether it affected me? It becomes pretty much the same situation, unless we assume that everyone is honest, which is obviously impossible.
Well, no, the organizers solution won't pass this test. Moreover, we have never looked at the problem from this angle, as we had another formal model in mind. But of course, the statement matches your model better and now we have to think how to treat this situation.
Any recommendations and suggestions are appreciated.
Results will be delayed.
¯\_(ツ)_/¯
lol so either I do bad or the round becomes is unrated xD
Congratulations Tweety for candidate :D
Why must system testing for other problems wait?
Do not make div2 round unrated.
Just my recommendation :)
I see many downvotes but isn't it quite reasonable proposal? The issue affected much smaller percentage of competitors there, and many of affected will anyway get to div1 soon (if they are good enough to solve div2-D), right?
It is not just the final opinion that is a subject to judging someone's post. For me reasoning is main thing to be judged and here I see no reasoning.
That is deep :)
Summary of most opinions whenever the question arises
(Before anyone accuses me of doing the same thing, I did ask for it to be unrated before I knew I failed the n=1 corner case in D :P)
Well the pertests for A and C were very weak and people got a lot of points from hacking (some people got like 1900 and 2000 that's like solving D from the start!!!) and D is unsolvable the queue was not compiling for 15 mins.
Hmmm... not sure what are you going to do but making it unrated is the best solution I think.
note that a contest (I don't remember the number of it) was made unrated for a queue that lasted 20 to 25 mins
IMO only justified decision would be to make it unrated. Which is kinda sad because many people have looked at the problem from exactly the same wrong angle, but there's no way to fix it right now.
Making a round unrated is a fine solution. I think that giving everybody 0 points for B (or maximizing scores with 1000) wouldn't be terrible, though I'm sure many will disagree.
The number of strong people who didn't solve B is significant, so I think that it isn't good to make a round unrated for those who ask — there could be too many.
That's funny :) Looks like I made a bug somewhere in a greedy solution and instead of carefully check the code I have found a countertest.
Well, it is sad but I think this round should be unrated. Or for example unrated for all who didn't solve B (because it is hard to distinguish whether a person didn't came up with a greeedy / skip problem B or found the countertest).
In Div2 there are only 13 people who solved D, so...
... So other people found the countertests.:)
There isn't any hack for div.2 D, why rejudge for all submissions of div.2 D (WA and AC and all) isn't enough?
the problem is that the main problem with this looking will become NP!
Even those who can't solve B and C huh?
Ruining the whole div2 round for a problem where the number of the pretest passed solution is 13 would be unfair though.
giving them minimal points would be ok, they're 13 but don't ruin the whole round :/
In Div. 2 over 5100 people submitted solutions. I think that's the highest record, isn't it? It would be very sad to make the round unrated.
Plus in Div. 2 too few people solved it. We can make it unrated for them if they want, but for others that wouldn't be fair, as Errichto said here
well as Any recommendations and suggestions are appreciated.
1st I read D for 30-35 minutes got this test case wasn't able to think of anything and thought its beyond my level and left it after that I submitted my 1st solution at 1:24 and 2nd at 1:30 and 3rd at 1:35 long queue of solutiona were there.Verdict for all three came after 1:50 and sadly i got 2 wa and i had o time to correct them so in my opinion round should be unrated and now when i m looking my code again I see that I had done a silly mistake in E which could had been resolved if verdict had came on time.
So, In My Opinion round should be UNRATED
Statement can be changed so that machines cannot be reused once stops working to make the intended solution correct.
Let's change constraint for n to 3.
That's different. Everyone solved this problem including the author (and also many who didn't solve it IMO) have this constraint in their mind while every one certainly know n can be large.
My comment with n ≤ 3 wasn't serious of course. Yes, most people tried to solve the version you described. Still, it's hard to decide what to do with the round. Changing the statement won't change the fact that some people tried to solve an actual version.
I think not many, maybe only 1 or 2, tried to solve the actual version. I admit that it is hard to revolve this situation but there might be a better way than to just make it unrated.
This is just not true. Everyone TRIED to solve the actual version, but no one succeeded (including the authors).
If it's indeed 1 or 2, it's reasonable to make the round rated and indeed use the version almost everybody tried to solve.
It is not like "people had this constraint in their mind". It is like "everybody thought it would be optimal to do it that way", which is substantially different.
Yes, your description is more precise. I mean that even almost everybody thought it would be optimal to do it that way, but some did solve it that way while others didn't. We should not say their efforts are in vain.
As long as we do not add that constraint to description I would say there is no difference to how long will you follow a path if it is a wrong path.
I agree, I actually by mistake read N <= 1000 and M <= 1000000 instead and tried to solve that (though got WA).
Try this
3 1
1 3 4
7
:(
It is even better! Because we only send copies to other machines.
It is the version mentioned by GlebsHP, isn't it?
I don't understand mentioned where, but yes, we discussed this with GlebsHP. This test was inspired by halyavin, if it is important. Or I don't understand your question.
UPD. I think I understand about what version you a speaking. Yes, we cannot just add to the statement that machines should run contiguously. We should describe the whole greedy algorithm to make things work. And Gleb is notified about this.
I think it would be silly to make the Division 2 round unrated since only 13 participants actually got the pretests. I'm not really sure about the Div 1 round though.
Ok, but did it really was a problem for a lot of people? How many of them could honestly say that it affects them? It would be very sad if this round will be unrated. Problems were nice.
Maybe it's stupid suggestion but if you don't want to make it unrated then assuming people who realized that the greedy is wrong are very low and most people just assumed the greedy is correct, then just change the statement in a way to make the greedy correct and make the round rated. this will make it unfair for very low number of contestants (maybe only Um_nik )
Now everyone will tell you that they came up with the test too. xD
See
I will be sad :)
Just kidding. Maybe it is a good solution.
So maybe the following approach: in div1 allow participants to ask for unrated round and see what will happen. If many will demand it, make the round unrated for everybody.
And div2 unrated without any changes or with giving 0 for B for everyboyd.
That looks like a good solution. I belive in honesty of div1 contestants.
I was div.1 6 days ago. I think you shouldn't :-P
Well, I think to judge any answer equal to or better than the ''solution'' to ''Accepted'' is a good idea. (As I think my solution should be AC if judged with the original tests. :-P
Also, making this round unrated is OK.
(I don't think a rated round with changing the score is a good idea.
And no one is even discussing about long queues which affected some contestents very badly
Any recommendations and suggestions are appreciated.
Instead of making it completely rated make it partially rated. If dx is change in someone's rating scale it to some factor like 0.5x . It's a Win-Win for everyone. Unrating contest with such huge number of participants doesn't look good to me at least.
If there be a poll about that this contest be rated or unrated, I think many people don't vote at all! because they didn't think on Div.1 B! There were many people working on other problems and this contest was exciting for them I think!
Exactly! but If we ask in poll for contest to be rated or not. many will say unrated (for any contest). Most of us are never satisfied with our performance.
Can we make it optional for people who submitted at least once on Div2D to have rated/unrated? Otherwise rated for everyone else.
Well, having submitted a code for it at least once isn't a factor, what if someone knew this greedy won't pass and he/she spent his time to find a better solutions?
Silly suggestion:
Problem B is very hard. Its pretests were weak. The author decided to change his identity and move to another planet before posting the editorial. Everyone failed systest on B and up to this date no one knows how to really solve it. The round was rated.
Since you are blue, are you referring to Div2B?
For Div.2 there are no problems with D, that's why I'm saying B :-D
My guess is most people who read Div2D/Div1B and confident enough to attempt on submission consist of only a small fraction of the population. I really don't see the point of making unrated for ~5000 participants
Please don't make the contest unrated. This was my best ever Codeforces round!
In my opinion, not giving anyone any points for Div 2 D and keeping it rated is a fine solution.
I guess everyone used this line of thinking:
"The obvious greedy solution is to make the fastest machines work. The problem is rated B and the limits are large, so the obvious solution must be correct, there's no need to think further or try to prove it."
You could say the problem produced undefined behavior in many contestants :^)
tl;dr make it unrated unless you have a solution that works on the current limits with the current statement and the pretest results are identical.
But did the mistake affects you? Or you used the same line of thinking? If second one, than why to make this contest unrated by request is not a good decision? There was such a precedent in codeforces.
I think that round should be unrated when it is impossible to participate for a big chunk of participants. Otherwise, we are just ruining round expierence for 99.8% of people (though, those of them who loses their rating would be only happy, no matter from what reason they lose it).
B and C had the same amount of points assigned. Deciding which one to attempt first was basically a coin flip, until later in the round when you could see the number of submissions. Those who chose to do C first have a huge advantage purely because of luck, I don't see how it would make sense to adjust ratings based on that.
I don't understand what are you speaking about. I don't suggest to remove B. I suggest to change its statement and make this round unrated for those who think that they lose some time/points because of B.
Ok, so everyone who blindly submitted the greedy without proving it would get +rating, and everyone who thought about it would have the contest unrated. By doing that, you're rewarding something that probably shouldn't be rewarded.
Remember that rating is always relative to other people — if everyone except you gains rating, it's the same as when you lose rating.
The question is: how many are there people of second type? If it is only Um_nik than probably you are overestimating importance of this issue. If there are other people who has problems because of this in first div. than they should probably mention it already. By the way, if Um_nik is the only one who noticed this problem during round, than probably coordinators should consult with him and decide what to do with the round
That's meta-thinking is exactly what I hate in programming contests :(
Beautiful explanation of metathinking! Thanks.
Can you say what was the formal model?
Thanks!!!!!
Hi, I sleep over the contest, problem B seems delete from the database, someone could tell me what is the original problem? (Just content my curiosity)
Given N copy machines. The i-th machine can copy one file in ti seconds (either from the original file or a copy). Given M queries. Each query asks us to calculate the minimum time to get ai copies of files if we only have the original file at the beginning.
1 ≤ N ≤ 200000, 1 ≤ M ≤ 2000, 1 ≤ ti ≤ 1000, 1 ≤ ai ≤ 109.
Oh.. feels like the new trend on codeforces is tough Div2 D / Div1 B problems.. So much fun in the contest. Thank you BigBag for such great problems!
I feel implementation wise E is harder. Its just that lot of people just know how to do it.
the sarcasm is strong with this one
Can you solve Div2 E/Div 1 C using Range trees?
Segment Tree
Can you explain your solution?
It should be known that Fibonacci number can be solved by matrices,
[f_n,f_{n-1}]*A=[f_{n+1},f_n]where A is easily given. If we wanna know f[n], using matrices above can do; just [1,1]*A^n is ok. Then we use segment trees maintaining the summation of A^a[i] in a segment, the rest part is easy to solve.I think this contest is so great,the C problem in div1,give me great suprise!Though I don't know how to solve it......
What was pretest 1 for A/Div.2-C?
Pretest 1 is the example test.
Problem C test 7 100 109.998
I'm getting 110 Is that correct?
I believe that is correct.
Yeah.
Yes.
The moment when you submit your first solution at 90mins. Then during the long queuing process realize that the solution would give TLE and have no idea to optimize.
Why didn't you try div1A? I'm sure you could've solved it :)
Wow, that's one complicated moment
this contest is making me a creative guy, not only the questions, but also about the new story that i should make to tell my teacher which I haven't wrote the homework spending my time for the contest :P
Tell her that homework is useless and contests are at least very fun :P
challenge accpeted :D
HAPPY BIRTHDAY! BigBag too
but I was hoping that this round will be easy :(
That round very good super round in my life.:)
awkward moment when the rank 1 in div 2 solves 4 problems whereas the rank 2 solves 5 problems.
can 3 1 0.9 be a test for div1A?
why not?
Yes, it could and the output should be 1
my solution is getting 1 two but i think i could hack someone with this :(
OMG! Yeah It can be and I don't output anything :(
EDIT: Oh ! Thanks God! I just entered 3 0.9 1 instead of 3 1 0.9, It was a HORRIBLE moment!
Can 2 1 .9 also be a test?
BigBag isn't your birthday done ?! we are waiting for editorial, please! (And also Happy Birthday :D )
how to solve div2 B ? i can't figure out it for a long time
The string should be transformed to either rbrbrb... or brbrbr... For each you should calculate the number of blacks and the number of reds to be changed, and the answer is the maximum of the two because you want to maximize the use of the swap operation.
Think of rbrrrb as 101110.
We need to make it either 101010 or 010101. For any input there are always only 2 possible target strings(we need to figure out which one is the closest).
Go through your input and compare each character in input string with these two target sequences. The sequence that has fewer errors wins and now you just count how many errors there are.
how does counting the no of errors help?
The number of errors is essentially the answer ;)
If current character s[i] doesn't equal to the target character t[i] it means that it is
1. either in the wrong position
2. or painted in the wrong color
In any case we have to apply some action to it.
If there 10 zeros which are not on theirs places and 12 ones are also not on theirs places, we do 10 exchanges and 2 painting operations.
when can we start upsolving?
Div.2 contestants who solved problem A correctly could get a decent boost in rank after system testing :D
Also for Div2. C , Pretests are even more weak!
I tried hacking with "2 1 .9" for Div2-C, it gave "Invalid Input" though.
Prob stmnt doesn't say anything about before the decimal.
Actually .9 is not a valid number!
Isn't it upto the representation one decides on. I just thought this part was ambiguous and debatable.
Why it stays Pending system testing..
Because there is something wrong with the problem B. This contest may be unrated.
GlebsHP said here that system testing is delayed because the round will probably be unrated because the problem setters put too little thought into problem B.
Please don't make it to be unrated for just Div2
this div2 round is "hack war" :D just 4 fun
Is this testcase valid for Div 1 A?
No
No, because there are no digits after the decimal points. The test
3 1 9.0however is correct.Edit: This test is incorrect because the decimal representation of 9.0 ends with 0 but it shouldn't according to problem statement. Thanks
It's guaranteed that the grade is a positive number, containing at least one digit after the decimal points, and it's representation doesn't finish with 0.
It only said that there will be digits AFTER the decimal points, but nothing guaranteed there will always be a decimal point (?). Hence "9" is still okay... cmiiw
It isn't correct too:
"It's guaranteed that the grade is a positive number, containing at least one digit after the decimal points, and it's representation doesn't finish with 0."
The second line contains the grade itself. It's guaranteed that the grade is a positive number, containing at least one digit after the decimal points, and it's representation doesn't finish with 0.
not valid too :p
I left a football match for this contest.
Disgusted?
Is it the right word you wanted to use?
The truth has been spoken . Every problem except D had no "thinking" involved , just implementation .
"If we still manage to find the right solution and answers on pretests will be the same, the round may be rated."
and the answers should be the same for the hacks too, I think.
At least, div.2 hasn't any hack for D
It sounds like a non-important philosophical thing (whether there exists a solution). If nobody solved this problem, I don't see difference for the round between an NP-hard problem and the existence of solution. In the latter case nobody can say "I wasted my time because it can't be done" but how does it matter?
Forgot "If the answer is integer, do not print dot." in Div2.C until several minutes before the end of contest...
System test began. Is the round unrated?
I hope it doesn't become unrated it's my best performance an a round yet !
It's about the journey, not about the destination :D
don't be sure because my C solution passed the test and it's so week..sorry for bad english
they said that the problem which had a wrong solution was prob B div. 1 or D div. 2 I don't think problem C had any issues
yes but I found many tricky and simple test cases my solution gave wrong answer for it .. I hope to be blue in the next contest
I hope you have a good luck next round :)
Me too, if the current final standing is final. I cannot believe I can be in div1 top 10. Hope authors works out a good solution than to unrate this round.
I hope the round becomes rated!
Me too.
Please show us pretests so that someone can point out the mistake for those cases (if any).
pls, make it rated
there are very little people that solved D div2 so please don't make the round unrated
"is it rated?"
fairness' side says "NO" ..
I never thought this question become important one day xD
Make it rated ... Very less people bothered about solving the d problem.. so it wont affect anyone in a bad manner...
pls, make it rated
People who asking for the round to be unrated are acting pathetic though. I saw the problem and generated several test cases and knew my solution would fail so i skipped it. It isn't our problem if you lack the skill to know whether your solution will fail or not.
It is not about what people think about whether the round should be rated or unrated. Even if there is only one person that tried to solve the problem div2D/div1B and couldnt solve because of this then the round must be unrated because this is what should be done. Just because you were lucky and didnt even try to solve the problem cannot make the round rated. Please be rational
Let say someone attempted D, if they didn't submit at least 1 submission-> failed, if they spend on it for too long, it doesn't make any difference from spending on any D for too long -> failed. If they don't read it, then it doesn't matter. Make it unrated for people submitted on D. and rated for everyone else!
If we use your logic then why do they make some contests unrated ??? Lets consider the last contest when the website collapsed but still some people solved some problems. Why was the contest unrated for those people ?? lets make it rated for only them ???
Your question contains the answer: "...the website collapsed but still some people solved some problems..."
When the majority of people are affected, the contest is made unrated.
Round is shit. Unrated pls
Make DIV2 rated please
Only Regarding Div2 : I think it would be best to make it unrated for those who attempted Div2 D (if only they want). Making it unrated for more than 5000 participants just because of ~100 people is not a desirable thing in my opinion.
It would be fair to make it rated even for those who attempted Div.2 D and give them 0 points on it. After all, they didn't solve it correctly, right? :-)
How do we know who attempted to solve it? Note that "didn't submit" doesn't mean "didn't attempt to solve it" :)
I don't agree with you on this. People might have spent too much time thinking D even if they didn't submit while they might have been able to solve E using that time.
Please at least make div2 rated. I'm pretty sure whether author's solution for problem D is correct or not won't affect about 99% of the participants in div2.
I have spent 1.5 hours on it before giving up. Can we make this round unrated at least for some individuals?:)
why didn't you give up if you can't think of the solution?
How can you ask him to give up if he is not able to think of a solution? -_-
Anyway, Just make contest unrated please :)
It might be NP-hard.
salam
it is my best performance in the codeforces but if it is rated contest then it is oppression in the right.
please make it rated atleast for DIV2 as 4th question hardly matters for most of the contestants.
I doubt keeping div 2 as rated would affect too many people. More than 5000 submissions but very very few on D!
Not many div 2 contestant sovled D but may be many of 5000 contestant was spend many time to this (because problem A B is not hard and problem C make confused). So I think problem D affect the result
I dreamt of being purple from so long. When I did good, rounds were declared unrated twice. I am currently at 1878, and got a rank of 35. Then first surprise, my E got tle on 16. I almost broke. Then I found that my rank is still 145. I will get to become purple :D.
People doing CP seriously have great attachment with their rating. Before hosting the future rounds, it should be made sure that the round goes smooth.
As luck would have it you'r purple! Congrats !
Congrats !
Thanks guys! :D
chi l olon um yrisnaas bolj naad Bigbag chn bantsanda ingeleeshde bandi chn
Now, you will not see a rated contest for yourself for a long time =)
But now the frequency of Div1 contests has also increased.
Make it rated, please.
Where can we find problem B? If you publish it there will be more chance to be solved.
You have 1 <= n <= 200000 copy machines and 1 <= m <= 2000 queries. Each machine takes 1 <= t_i <= 1000 seconds to copy a paper. For each query 1 <= q_i <= 10^9, output the minimum required time to create q_i copies from one original paper. The copy can be made from the original or copy, either one.
Input: n m t_1 t_2 ... t_n q_1 q_2 ... q_m
I hate getting nothing after 3 hours of work. I would perfer "rated".
Please publish editorial for rest of the problems..
Contest should be unrated. There was a long queue.
I really don't understand the people who can't solve A and B asking for unrated because of D....
Internet points are important to people. :D
They use it as an excuse :D
Giving poll to people who did bad and didn't even attempt div2D doesn't make any sense.
That's the problem that none tends to notice most of those who are asking for unrated mostly didn't solve b or c, how come would they have solved D
They're just slacking off to avoid bad ratings. apparently in the past weeks because of the queue problem, the demand for unrated contest grew so childishly.
plzz make it rated at least for div2 considering the hardness of the problemset uptil c problem it wont be injustice to anyone!!!!!!!!!!!!
please make it rated at least for div 2,since the number of people who solved D is very less,compared to the total number of participants.
I believe keeping it rated is the way to go (for div 2 only)because only 13 people solved the question.
Make DIV2 unrated please
Could anyone please prove the solution of D? It's obvious, that if oriented trees for some vertexes u and v are equal, then if we add new vertexes to both of them, then we get the same trees. I can't understand why it's enough to check. Why can't be there such a bijection, that added vertex will correspond to the old vertex of other tree?
So I will take one step back and ask — what is the solution to that problem you are talking about (I don't know any)?
I'm surprised, you know so much random stuff I thought you were the walking encyclopedia of classical algorithms!
For rooted tree isomorphism, represent each subtree with the same number of nodes by an unordered hash of its children (you can make it perfect hashing, but I just use some large numbers and hope nothing collides). Then the trees are the same if hashes of root subtrees are the same.
I can't answer the original question because I didn't actually prove it (the same way no one actually proved B).
He is the walking encyclopedia of random stuff.
Hm, I know how to check isomorphism of trees, I even came up with it on my own like 5 years ago (but beware not to use polynomial hashes >_>), but it seems that any slight modification of classical algorithm can be sufficient to make encylopedia dizzy :P. Or maybe that was 6AM that "helped me" here :D.
So, how to use that to solve that problem? I thought about rooting it in centroid, but I didn't know how to update hashes and still there are some problems with it.
EDIT: Ahh, thanks guys. That was kinda written in -XraY- post, but somehow I didn't get it, but now it is clear :).
My guess is try every node to be the root, for each node v calculate the hash of the rooted tree which is rooted at v then store the hash in set, the answer is the number of distinct numbers in the set. of course don't consider vertices of degree 4, this is naively implemented in O(n^2) but I think it can be done in faster way
Then you need to use fact -XraY- mentioned: trees with a leaf added to i and j are isomorphic iff the original tree rooted in i was isomorphic to the original tree rooted in j.
I haven't proved this, but my intuition said that if you are changing exactly one subtree in both cases and ending up with the same thing, then the subtree you changed had to be the same (this wouldn't necessarily be true if you were adding 2 or more nodes).
Are the system test cases for problem C Div2 strong?
I think They are strong. I remember at the end of the contest about 1200 people solved it and now about 700 people did !
I think The question "Will be round either rated or not" is harder than Div.1 B
From quite a few times the rounds are being unrated .. for div2 the contest must be rated because the issue with the problem d wont affect the rating of anyone.. Many people didnt reach Problem D
I hope this will not be a rated round. :'(
uillaa ci buur specialist um bj yasn c ydii :)
Can you please fuck off? :)
is question D open question?
i was working very hard this round , it seems to me really not fair to get nothing at all .
you're right man
MAKE IT UNRATED PLS!!!
I spent less then 5 minutes on solving each of ABC and the whole contest I was thinking only about D! Really! It's unfair!!!
You didn't submit anything on D. Even if the author solution is correct, you still fail D anyway. WHy would it matter???
I could spend all this time on solving E of course
I was thinking about D between submissions
I was thinking about E Div 1 too :( lol :3
You won't believe but i was thinking about D in exctly same way that you was thinking about E. ;-)
You won't believe but his comment was sarcastic.
You won't believe but so did the original comment
I don't think you want it unrated now, do you?
unrated twice when i manage to become purple,sad
It's rated and you are purple, lol
im lucky not to think about D,and im sorry that you've spent a lot of time on it,pity for you
oh,i am purple,thanks god
Whyyyyyyyyyyyyyyyyy! Pleaseeeeeeeeee!!!!!!!!!!!!!! I want this is contest rated. Maybe only div2
Rated! Excited!
is there any way to check if my div1B had passed pretest or not?
Make the round unrated.Once a question is wrong, it should not be rated. Even the queue was there. It would be unfair who tried D but couldn't get it.
I think this is going to be a harsh comment but I really have to make this comment. I have posted asking for more contests in codeforces and so many people downvoted me and they said that it takes a lot of time preparing contest and testing it. Seriously if you guys have spent a lot of time on that, what kind of contest was this ? The test cases are seriously very bad. There is an incorrect solution and there was a queue or 20 minutes at some point. The questions were not unique. I seriously do not understand why some people say this round was so nice. I am not being disrespectful to the author but just because you did well on the contest dont say it was a nice round, justify your idea , dont just say it .
The people saying "this round was nice" just performed good or got a +ve rating change . These might be the least interesting problems amongst recent rounds. A,B,C,E were totally implementation related no actual thinking required . And as usual your rank depended on "how fast can you implement or how accurately can you implement or just plain hacking" . People give contests because they like problem solving , the only problem that was difficult enough to "think" about was wrong . xD
The testcases are bad? Why do you think so, have you got AC with wrong solution?
The problems were good, I personally like div1A very much.
What problem is not unqiue? div1C uses classical idea about matrices but I haven't seen this exact problem before. Nobody posted a link to a similar problem so even there exists one I don't think it is widely known.
I have also read div2AB and found div2B very interesting.
Yes, author's solution to div1B was wrong. Or maybe it has wrong legend. It happens. I think that other problems were good.
I think he meant the pretest is too weak. There are many people getting >= +12 hacks in div 2, which kinda make it a hacking contest. In my Opinion, hacking is good, but however to hack a problem 18 times with the same test cases sounds a bit ridiculous. The contest itself become a matter of luck (whether there are other hacker in your room). I only got +2 in hacking div 2 C as there is another guy who just spend all his time hacking div 2 A instead of trying to solve other problems.
Also, the problems is a matter of taste. I personally didn't like div1A as it is just messy coding and does not really helps in thinking. But overall, the problems are not bad.
I was accidentally printing '\0' without knowledge :( The submission details told me, but custom invocation didn't! Not trying to sound rude but I'm disappointed.
Thank god!! It is rated party!!
Can someone give me a convincing reason for making the round unrated? It's not that some people solved the problem and got WA because the author's solution was wrong. No one solved it!
Maybe there are people who solved only Div1 B.
It's unfairly.
Thanks for making Div2 rated! :)
huts muu bandi min dungj specialist um bj bakaal chn
sorry mate, can't understand you! But I think you're happy as your rating increased! :p
"current incorrect version of problem E?" You mean E has problems too? o.O
Problem D. Fixed.
I think you can consider group ones who 'solved' Div1B together and the rest in another group and consider it as two CF round then rate both them only in their group.
If you think about it, that sucks.
I didn't say my idea is a good one. You can come up with a good one.
I already said mine opinion :D. Unrated :P.
Yadag muu bandi we :) Bigbag gdg nuhur tursun udruuruu ingej hun amitnii durguig hurgeh hereg bdimuuu nofshhh we iim arcaagui temtseen zohiocod :)
ulun bandi nar ygaad -1 draad bnaa
If the round is rated for Division 2, I think the two people who solved problem D should be given credit for it. Part of coming up with a solution is knowing that the problem has a valid solution. Therefore, if there is only one solution you can possibly think of, it makes sense to code it up. They shouldn't be punished for the bad problem. Throwing out the problem is unfair to them.
Can someone explain Div2. C? I got TLE on #25 :/ http://codeforces.com/contest/719/submission/20858479
ciniii l sugiih bainda naadh chn bi ywuulad shuud tentene shde :)
?
nvm I got it now. Shouldn't have used BigInteger for what comes before the dot...
The complexity of your solution is O(n2), because you have a loop inside a loop. In general, for the problems of size n = 200000 the worst complexity we can afford is O( ·n). Luckily, this problem can be solved with complexity O(n) (that is, without nested loops).
·n). Luckily, this problem can be solved with complexity O(n) (that is, without nested loops).
Are you sure it's N^2? I the second loop onlyou runs once. I got accepted by just fixing the BigInteger bit
Sorry, my mistake. I didn't notice
breakright after the second loop.I'm glad you solved it!
It is totally unfair that contest be rated after a problem is deleted because I know people who spent most of the time of the contest in this problem.
You have to think about it again because this decision is unbelievable!
I'm one of the people that spent most of the time for problem D (needed 1 minute to submit the the wrong-idea solution). But if you think a little, you would notice that there isn't a major reason for div-2 to be unrated. People who are badly affected are the two guys with AC on the pretests. But all other people (including me) who didn't submit (or failed at the pretests) just had the bad luck to spent their time on problem D, not on problem E. However this is no different than in regular codeforces round with equal points for the last two problems.
You can spend the majority of time on D and still fail. It is very likely that for div2, less than 1% could get an accepted solution anyway. It's your fault to put all eggs into 1 basket in any contest
That's precisely what I said.
Think about the juicy 2500 points, I was all in for that huge treasure thinking that I have a possible solution.
This could not have been worse for me =[:
I missed out the back==0 and back==15 cases in Div2A
For some reason I thought the swap action can only be performed between neighbors in Div2B
I spent the majority of the contest time trying to solve Div2D
I messed up the string constructor in Div2C, I wrote string(char, quantity) instead of string(quantity, char).
I am thankful to remain blue after this contest...
You are lucky. I've lost 132 points in the previous round =)
I think the round should have been unrated. Not because I did poorly. Codeforces is so popular now. Everyone participates in contests here regularly. I know that the authors did some unintentional mistake maybe. But there are people who tried Div2 D and thus wasted time. Also for some time (nearly 20 minutes) the server was down or super slow. In Codeforces rounds, every second counts. Everyone knows that mistakes like this take a huge toll on the participants. And also, however fair the judgement maybe, it will still be unfair to many contestants who lost points because of this mistake. I believe it wouldn't hurt to make the round unrated. Still, whatever they decide :)
I had submitted a hack for div2 C, and it was in the queue till the end of the contest. Now I see that it was never evaluated. :/
Am I the only one who feel weird for a round to be rated on only for one division?
Won't it cause rating inflation? Since Div 2 is rated (and assume Div 1 is not rated), there will be people upgrading to Div 1, but nobody downgrades to Div 2. Therefore, we will have more Div 1 people at the end of the day.
I was born in TopCoder (meaning that I started TopCoder first before joining Codeforces), and I remember there were several occasions in SRMs where the problem only affected one of the division, but the round were not rated for both because of this issue.
Well, the rating calculation is different between the CF and TC, so the problem in TC probably will not happen here. I don't know though.
It isn't the first div2-only round.
In Div2 only round,people will only upgrad to Div1. In this round,there are also some people in Div2 had down rating.
What?!
Happy Birthday
It is quite sad when a solution for Div1C gets TLE because of missing inlines :/ (Well, even with inlines it got 4898ms, so perhaps I should have made it O(n log n) instead of O(n log^2 n))
"Because in Division 2 only two people managed to pass the system testing for the current incorrect version of problem D, jury decided that the round should be rated for Division 2."
What about the contestants who spent most of their valuable time to solve D? Wouldn't it be unfair to them? As problem D is supposed not to exist there from the beginning of contest, then there must not be any time lost because of that "problem", must it?
I am one of them and I still think that it is okay to do so I have been waiting for so long to compete that I would cry if it was an unrated contest
Please post the editorials..
When will be editoral?
which editorial u want the one for the correct solutions or the one for the incorrect solutions ?
One with correct solution. Give me now?
Can somebody explain how is the the answer for the following test case 2 for the following test case. 5 10 1.555
round it to zero decimal place. 1.5 -> 2
Are'nt we supposed to do rounding off after the decimal point ?!!!
you can round up to the nearest whole number. 1.555 to 2. you use 1 Energy so its possible
Are'nt we supposed to do rounding off after the decimal point !!!
there is even a case in problem statement "If the number was 1.5 we will round it to 2 "
Couldn't the Div2 D , the problem that was removed be solved using parallel binary search ? My implementation — http://ideone.com/dXcbpq
I don't think so. Try generating test with this generator.
I'm 100% sure that the complexity of the solution will be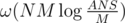
My solution fails to surpass this test in proper amount of time. Tested yours, it also fails to print solution in 10 seconds limit.
Read comments above. Your solution is just as incorrect as other solutions.
Its realy sad to be rated
Incorrect questions
The contest wasn't estimate the real problim solving skills for participate since of very weak pretests , so the first one who lock his solution he will hacks all the wrong submissions in his room .
CF is going to its end :(
So true ! From the previous 4-5 contests , there is some issue or the other . Never thought about not participating in codeforces contests until now .
After 5 hours of waiting, the regular "is it rated" question makes sense :P When can we expect editorial? With problem B(1) or without
I think the editorial isn't done because the problemsetter needs to deal with div1b/div2d first, it has higher priority than editorial and also he can't write editorial and fix tests/fix his solution/rejudge at the same time, so patience you must have, young codeforcer
Maybe the author will come up with a solution for problem B on his next birthday and declare this round as rated.
Can someone post this div2D/div1B problem statement please? I couldn't participate and now this problem does not appear when you enter contest from the past contests list.
Enjoy!
very very Happy birthday BigBag :)
So will div 1 be rated now? I suggest that if someone can get rating rising,than he can be rated,ohterwise not.
This case reminds me round 330 which was also unrated because a wrong greedy model solution. So the moral is that authors have to be very careful when setting greedy problems.
Well, I think Div2 D (Div1 B) is a good (and the method to solve it is useful in ICPC or OI or some other algorithm contests) problem if we can change its description to make the greedy algorithm correct. Could you update the task and make the new problem public? Thanks.
It seems to me that to make the greedy algorithm correct, one must add an additional constraint on t_i. If they are all powers of two, then I fail to find such counter examples.
I love you guys(ง •̀_•́)ง
Thanks for a really awesome problem set. Really enjoyed the contest. Did learn some trick ,such 1C
will there be an editorial?
Here.
Why not change the problem statement of B a little bit(not allow the situation [user:Um_nic] mentioned) and put it back into the problemset. It seems like a nice problem. Because of the limited time, I didn't pass the pretest during the contest, and have finished it now. I wanna know whether my program is correct or not, but have nowhere to test.:D
Can you pass test from this comment?
He has a point, I'm very interested in the solution of div1B. I did a dirty solution which could possibly pass, but what I am interested is in the official solution (without the tricky unexpected cases), if the problems is changed I could learn of it, or at least if i found comments about its solution, I have not seen any.