


Since nobody posts it, I do.
C: Can we solve it faster than 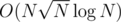 ?
?
B: Is there a simple way to solve this? We want to count the number of integers that appear odd number of times in a given range. To do this, we can use bitset for frequent numbers and sweepline + data structure for rare numbers, but it looked much harder than some other tasks...







for B we used Mo's algorithm to solve it in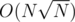 time and it was very simple to implement.
time and it was very simple to implement.
anyone know how to solve problem G?
G : We can decompose the grid into O(N + M) strips which have height or width 1 — If we build a graph for a crossing strips, the minimum number of mirrors for a cell equals to the length of shortest path.
However, the graph have too many edges (O(N2)), so we should reduce it. We can do it with a tricky application of binary trees — Build a segment tree over a [1, N] interval, which every node in a tree is some auxiliary node of a graph, and there is a directed edge from parent to vertex for each node. Now, if we want to add a edge to all vertex in interval [L, R], we can just find a relevant O(lgn) node, and add an edge to the selected O(lgn) node.
Now if we use a sweep line to make a graph, we just have to handle two queries : * Adding an edge to an interval. If the tree is appropriately constructed, then this is same as above. * Updating the vertex in the position. This can be dealt in a "persistent" manner — we can make new segment tree, with only that vertex changed, by introducing only O(lgN) new vertex.
So, we constructed a graph with |V|, |E| = O((N + M)lg(N + M)) in a reasonable time. But the story doesn’t end… we should calculate the sum of cost for each cell, which is eventually the intersection of strips. With another sweep line, this reduces to the following query problem:
This can be done by 2d segment tree, which can be implemented as a vector of fenwick trees. Phew!
In the contest I had to implement this in only 50 minutes. I miraculously got an implementation that passes sample, 30 seconds before contest, but it unfortunately got WA :/ It turned out that changing 3 line was enough for AC, while finding the bug from 264 lines of code is a different story. Code
Model solution also goes like that, but it uses a fact that for each cell if the distance to its row is x then the distance to its column is either x - 1 or x + 1 (different parity for rows and columns). So if for each row and column we'll take sum of its_length·distance_to_it then it'll be equal to result·2 + number_of_reachable_cells. So we second sweeping is not needed.
Nice observation! Now I don't need almost half of my code (including that problematic 3 line)
I've solved C in O(N * log2(N)
Note that sum of answers ≤ N * log(N) and then we can use some greedy strategy maintaining current_subtree_size - index in segment tree.
My code: https://pastebin.com/hz5wWNEd.
How to solve E?
For each vertex, we must find matchings of paths. We can pick two edges of different neighbours and match them. Almost perfect matching(depending on parity) is possible only when maximum element is no more than sum of rest. Otherwise, match everything to largest edge.
How to solve A? I thought about it about 2 hours, and still have no idea..
We need to find minimal subset with AND equal to 0 and number of these subsets, it can be solved with AND-convolution.
My implementation was: 20*20*2^20 (max answer 20, and nlogn = 20 * 2^20) which got tle.
So you can use binary search by answer and get log(log)*nlog (i've solved it this way):))
Or you can find A[0] in O(n), just avoid calculating useless values, and it will be n+n/2+...+1 = O(n)
How to calculate it in O(n)?
If you know what do these values after transformation mean, then it can be deduced that you have to take sum of av·( - 1)parity of number of bits in v and it will be equal to A0.
300iq, what do you mean by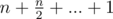 ?
?
I think it's something like:
Or same, but not recursive implementation. This is obtained explicitly from the inverse transformation function.
But anyway you have to do transformation for first time, don't you? So complexity remains O(n·log(n)), yea?
Yes, I think he wrote O(n) about A0 calculation part, which should be done log(n) times.
Yup
How to solve F and J?
For problem J, I see many Russian team solved it easily. I can't squeeze my solution into TL.
I also have a question about the intended solution of problem I. I implemented a solution with time complexity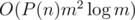 . I also spent many time on optimization.
. I also spent many time on optimization.
You don't need log(m) in I I think, you can precompute all gcds and all powers of k. When you have fixed partition you should calculate some dp with m states, each of them in O(m) time. Calculating this dp goes as follows: iterate over length of cycle (in permutation of m elements) which contains 1, denote it by i and take dp[m - i] multiplied by something. This "something" is multiplication of some factorials and a value assigned to i. You can precompute all these assigned values once when you have fixed partition of n, just by iterating over i, then over cycle in partition of n and then taking proper power of k. Precomputing these values takes O(number_of_cycles_in_partition·m) time and then dp takes O(m2) time.
Are you sure that you have no logs in complexity of J? If you have, then there is a hint: values are up to 220 so you are able to have bitsets, each of size 220. I'm assuming that you already know that we want to split whole array into
bitsets, each of size 220. I'm assuming that you already know that we want to split whole array into  arrays. Also note that calculating Dijkstra doesn't need O(2k·k) calls of data structure, it needs only O(2k), because you should consider only first time when you try to get into some XOR/subset/vertex.
arrays. Also note that calculating Dijkstra doesn't need O(2k·k) calls of data structure, it needs only O(2k), because you should consider only first time when you try to get into some XOR/subset/vertex.
In F you should iterate over a turn and maintain big array which stores the information "in which sets of cards (with their assignment to players) some player would already say that he knows". When the turn is fixed you also know which player should now say something. So you can iterate over possible sets of cards. In each of them look at every other proper set which differ only by the current player's card. Some of them aren't possible to still be in the game because somebody would already end the game (you have this information in your big array). If in each of possible sets current player has this same rank then he'd end the game right now. It turns out that every game ends in at most 13 turns.
Using the opportunity: I'm the author of all tasks, so I hope that you found them interesting. :)
I really liked problem C / G. Thanks for the great problems! However, our team had complaints over D. I thought it was too much to implement for a nondeterministic (risky) solution.
By the way, was it a part of some official Polish contest? (If that's true, I'm interested in the scoreboard)
Our solution to D was quite simple, actually. We did the following: first randomly shuffle array b, then split array b into two halves of size c and d. Then consider all permutations of the first min(8,c) elements of array 1 and all permutations of the first min(8,d) elements of array 2 and find the two that result in the lowest matching. Repeat until you run out of time.
The problems were really interesting. Could you please share the solution of problem H?
What is the intended solution for G? Our team upsolved it after contest using O(N log^2 N) time and O(N log N) space using sort of 2D segtree, with lots of optimizations. I wonder this is a right way to do it.
Considering this reply it seems the solution has O(nlgn) time / space complexity.
My O(nlg2n) implementation above uses 3.1s / 940MB so it's pretty close on ML, although I didn't tried to squeeze time / memory in any means. I think removing the second sweep will reduce space or time significantly.
Thank you!
Oh, I missed comment above, nevermind.
D, H, I?
How to solve Problem H? Is it some kind of dsu problem?