#include <iostream>
#include <algorithm>
#include <vector>
#include <ctime>
#include <map>
#include <set>
using namespace std;
#define int long long
//x - next[]
//el - value in a
struct Node {
Node *l, *r;
int x, y;
int el;
int s;
Node(int x, int el) : x(x), y(rand()), l(0), r(0), s(el), el(el) {}
};
int get_s(Node *v)
{
return v == 0 ? 0 : v->s;
}
void upd(Node *v)
{
if (v == 0)
return;
v->s = get_s(v->l) + v->el + get_s(v->r);
}
Node *merge(Node *a, Node *b)
{
if (a == 0)
return b;
if (b == 0)
return a;
if (a->y < b->y) {
a->r = merge(a->r, b);
upd(a);
return a;
}
else {
b->l = merge(a, b->l);
upd(b);
return b;
}
}
pair<Node *, Node *> split(Node *v, int x)
{
if (v == 0)
return { 0, 0 };
if (v->x < x) {
auto t = split(v->r, x);
v->r = t.first;
upd(v);
return { v, t.second };
}
else {
auto t = split(v->l, x);
v->l = t.second;
upd(v);
return { t.first, v };
}
}
Node *insert(Node *v, int x, int el)
{
auto a = split(v, x);
auto b = split(a.second, x + 1);
if (b.first == 0)
return merge(merge(a.first, new Node(x, el)), b.second);
else {
b.first->el += el;
b.first->s += el;
return merge(a.first, merge(b.first, b.second));
}
}
Node *erase(Node *v, int x, int el)
{
auto a = split(v, x);
auto b = split(a.second, x + 1);
if (b.first->el == el)
return merge(a.first, b.second);
else {
b.first->el -= el;
b.first->s -= el;
return merge(a.first, merge(b.first, b.second));
}
}
int cnt_lager_k(Node *&v, int k)
{
auto t = split(v, k);
int ans;
ans = get_s(t.second);
v = merge(t.first, t.second);
return ans;
}
vector<int> nextv, a;
vector<Node *> t;
void build(int v, int l, int r)
{
t[v] = 0;
for (int i = l; i < r; i++)
t[v] = insert(t[v], nextv[i], a[i]);
if (r - l > 1) {
int m = (l + r) >> 1;
build(2 * v + 1, l, m);
build(2 * v + 2, m, r);
}
}
void update(int v, int l, int r, int pos, int lastx, int lastel) //v - l - r - pos - last_nextv[pos] - last_a[pos]
{
t[v] = erase(t[v], lastx, lastel);
t[v] = insert(t[v], nextv[pos], a[pos]);
if (r - l > 1) {
int m = (l + r) >> 1;
if (pos < m)
update(2 * v + 1, l, m, pos, lastx, lastel);
else
update(2 * v + 2, m, r, pos, lastx, lastel);
}
}
int get_sum(int v, int l, int r, int ql, int qr)
{
if (qr <= l || r <= ql)
return 0;
else if (ql <= l && r <= qr)
return cnt_lager_k(t[v], qr);
else {
int m = (l + r) >> 1;
return get_sum(2 * v + 1, l, m, ql, qr) + get_sum(2 * v + 2, m, r, ql, qr);
}
}
const int INF = 1e+6;
int n;
void querry(map<int, set<int>> &next)
{
char type;
cin >> type;
if (type == 'U') {
int pos, x;
cin >> pos >> x;
pos--;
int last = a[pos];
//del pointer into pos
next[last].erase(pos);
auto it = next[last].lower_bound(pos);
if (it != next[last].begin()) {
--it;
int posbef = *it;
int lastel = a[posbef];
int lastx = nextv[posbef];
nextv[posbef] = nextv[pos];
update(0, 0, n, posbef, lastx, lastel);
}
a[pos] = x;
//add pointer to pos
it = next[x].lower_bound(pos);
if (it != next[x].begin()) {
int posbef = *--it;
int lastel = a[posbef];
int lastx = nextv[posbef];
nextv[posbef] = pos;
update(0, 0, n, posbef, lastx, lastel);
}
//add pointer from pos
it = next[x].lower_bound(pos);
int lastx = nextv[pos];
if (it == next[x].end())
nextv[pos] = INF;
else
nextv[pos] = *it;
update(0, 0, n, pos, lastx, last);
next[x].insert(pos);
}
else {
int l, r;
cin >> l >> r;
l--;
cout << get_sum(0, 0, n, l, r) << '\n';
}
}
void init(map<int, set<int>> &next)
{
srand(time(0));
nextv.resize(n);
a.resize(n);
t.resize(4 * n);
for (int i = 0; i < n; i++) {
cin >> a[i];
next[a[i]].insert(i);
}
for (auto x : next) {
nextv[*x.second.rbegin()] = INF;
int last = *x.second.rbegin();
for (auto it = ++x.second.rbegin(); it != x.second.rend(); it++) {
nextv[*it] = last;
last = *it;
}
}
build(0, 0, n);
}
signed main()
{
ios_base::sync_with_stdio(0), cin.tie(0);
map<int, set<int>> next; //next[v] - vector<posisions of v>
cin >> n;
init(next);
int q;
cin >> q;
for (int i = 0; i < q; i++)
querry(next);
}



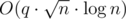 с помощью корневой оптимизации. Спасибо Holidin, который объяснил мне это решение.
с помощью корневой оптимизации. Спасибо Holidin, который объяснил мне это решение. изменений, если из стало
изменений, если из стало 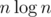 . Чтобы ответить на запрос суммы на отрезке, посчитаем ее с помощью первого ДО, затем пройдемся по всем накопленным изменениям и проверим, входят ли они в наш отрезок и как они меняют сумму с помощью второго ДО с map'ами. Ответ на запрос будет за
. Чтобы ответить на запрос суммы на отрезке, посчитаем ее с помощью первого ДО, затем пройдемся по всем накопленным изменениям и проверим, входят ли они в наш отрезок и как они меняют сумму с помощью второго ДО с map'ами. Ответ на запрос будет за 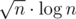 .
.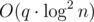 в онлайн.
в онлайн.






link
Могу предложить еще одну интересную задачу. Дан массив
aсостоящий изnнатуральных чисел, не превосходящихn. Ответить наqзапросов двух типов:set p v— выполнить присвоениеa[p] = vget l r— выдать сумму таких элементов на отрезке[l, r], которые встречаются чаще остальных.Ограничения: 2 секунды, 64 МБ, 1 ≤ n, q ≤ 2·105, 1 ≤ l ≤ r ≤ n, 1 ≤ p, v, a[i] ≤ n.
Пример:
Я переписал этот код на яву (точь в точь вплоть до имплементации) и получаю TL. На некоторых тестах код работает больше 10с. Этот код на плюсах вообще проходит? Потому что 10^5 запросов * log ДО * 4log ДД * 6 * немалую скрытую константу.