


Hello Codeforces,
Manthan, Codefest'18 will take place on Sep/02/2018 17:35 (Moscow time) with a duration of 2 hours (tentative). The round is rated for both Div1 and Div2 participants and will consist of 8 problems.
The Department of Computer Science and Engineering, IIT (BHU) is conducting Codefest from 31st August-2nd September. Manthan (मंथन in Hindi, meaning Brainstorming), the algorithmic programming contest under the banner of Codefest, is being held as a special Codeforces round. The round follows regular Codeforces rules.
The round has been prepared by hitman623, karansiwach360, GT_18, Ezio07, Enigma27, csgocsgo and me (dhirajfx3). Special thanks to TooDumbToWin and DeshiBasara for their contribution in the preparation of the round.
We express our heartiest thanks to KAN, vintage_Vlad_Makeev, 300iq, isaf27 and cdkrot for their help in preparing the contest and MikeMirzayanov for the awesome Codeforces and Polygon platforms!

Prizes
Overall 1st place: INR 25000, Overall 2nd place: INR 18000, Overall 3rd place: INR 12000
1st place in India: INR 10,000
1st place in IIT(BHU) Varanasi: INR 4,000 1st place in freshman/sophomore year, IIT(BHU) Varanasi: INR 1,000
About Codefest: Codefest is the annual coding festival of the Department of Computer Science and Engineering, IIT (BHU) Varanasi, which is held online and is open to participation by all! Register on the Codefest website now! Total prizes worth ₹500,000/- up for grabs with events covering domains from Math, Machine Learning, Natural Language Processing and Capture The Flag style competitions. Go to the Codefest website to find out more!
As usual, the scoring distribution will be announced just before the round.
UPD1: Scoring 500-750-1000-1500-2250-3000-3500-4000
UPD2: Following are the winners of the contest
1. tourist
2. DearMargaret
3. LHiC
Best in India
Good luck and have fun!
UPD3: Link to editorial






The best part of Codefest <3...
I hope it will be easier than last year
Last year problem B was a DP :((
so it was your 5th contest last year.
Yeah, it's relatively easy than last time.
Last year problems were harder than problems of the year before last year :)
Dude i don't know how, but you got to div1 in only 1 year. Last year's B was very hard for me too back then. I read it now and solved it instantly. I am sure it will be the same way for you. It's actually just playing with prefixes and sufixes.
Just solved B from last year, DP was definetely overkill.
I hope for better problems and better statements than the last year's contest.
People remember an year old event -- the scar must have been real.
Here it comes 2-SAT on splay trees of 3D persistent segment trees of dynamic convex hulls tasks.
National day of vietnam <3
Is there a place in the CodeForces website, showing your division? I know division boundaries don't change frequently, but it would be nice to see.
Email says that duration is 2.5 hours but here I see 2
lol, mail says 7 problems, here it's written 8 problems!!
Just confirming: there are 8 problems to be solved in 2 hours.
I hope for more problems that can be solved by the amazing SSE/AVX algorithm.
then a matrix multiplication will suffice
Manthan in hindi is " मन + थन " which means " mind + boobs ".
So, I guess it means boobs on my mind :P
Is it rated for division 3?
div 1 + div 2 = for everyone
So is it 2 or 2.5 hours finally?
2 hours
( expected more time for 8 problems
It's my first Manthan,hope to become blue!
Don't worry, you're already blue :)
Can anyone tell what मंथन (manthan) actually means in Hindi? My Hindi is too bad...
It actually means Brainstorming, but if you're looking for something funny, then the words can be broken to get an another, very interesting meaning. Click
lol, this can't have been accidental...
Hope the problem statement will be too much interesting and funny. :)
I didn't see 4000 problem before this round.
.
It probably pertains to when the height of tree is at least 4, such that there is an erroneous nesting while doing the traversal. For e.g.
INPUT:
EXPECTED OUTPUT:
YesFor Problem D, what should be the output for following input:-
4
1 2
1 3
2 4
4 2 1 3
Should it be "Yes" because as stated in announcement, a[1] is not necessarily 1?
Announcement states that a[1] is not guranteed to be 1 in tests.
I missed that :(
According to the first step in BFS algorithm, vertex 1 is always chosen as root for the algorithm, but a1 is not guaranteed to be 1.
In this case, answer is "NO".
Oh Thanks. Reading the announcement carefully, I too think that the answer should be "No". But why did they explicitly announce that? I was initially checking a1 to be 1, and then removed that part of code after the announcement. :(
They have probably seen the downvote storm in round 505 because of many FST (failed system test) and learnt the lesson from there =))
Oh
Don't compare us with tourist he is Legendary <3
He is Messi of programming.
No, Messi is tourist of soccer
actually messi and tourist are same person.
Hack for D?
My hacks were:
(TLE)
(WA)
How to solve E?
Let's first consider slow solution. Let deg[v] be the current degree of vertex v. Add (deg[v], v) into set, delete minumum degree vertex while it's degree < k and update degrees of vertices. Answer will be this set's size. Now to support queries, we can just do everything from backwards, instead of adding you will delete edge, and now it is easy to implement in O(n*log(n)).
Does your solution still work if the graph consisted of 2 disconnected components?
How fast does this update have to be? Because if I understood right, each node is deleted only once, but you have to get to all node's "neighbours" to decrease their degrees before deleting. Wouldn't it be something like O(n^2logn) or O(nmlogn) in total? I know how to optimise it, but can this program pass without any optimisation?
"Naive" implementation is fine.
The number of neighbour accesses is bounded above by the total number of edges (ie. m), so it comes out to something like O(n*logn + m)
Hint: Reverse the process (instead of adding edges from 1 to m, erase edges from m to 1).
Would be grateful, if you could help with why this code gives Runtime Error on CF compiler.
Works fine on Local Compiler as well as Ideone.
https://ideone.com/B8dFH9
You shouldn't erase while iterating:
See this.
Yup! Thanks a lot mate!
After all this time, you still keep learning something new :)
We can answer the queries backwards.
We build a graph based on the relation, and maintain the degree of each vertices in a set.
When we answer a query, we remove the vertices with degree < k, and remove their corresponding edges recursively. Then, all vertices has atleast k neighbours. The answer is the number of remaining vertices. After computing the m-th query, we need to remove the m-th edges given in the input.
Pretest 4 for D ?
I got caught there too, I think you have to check (when iterating over guys with depth d-1 as parents) to skip over leaves.
I think something like traversing nodes in level i in some order but their children in level i+1 are traversed in a different order (node k appeared before node l in level i but children of node l appeared before children of node k).
Just looking at the levels will not be enough. For example if 4 is the child of 3, and 5 is the child of 2, then 1 3 2 5 4 also comes out to be correct whereas the correct order should be 1 3 2 4 5.
Basically what this is saying is, if parent(a) is visited before parent(b) then a must be visited before b.
Am I right ?
Yep, exactly
I guess that test might be checking for naive solutions which only check all nodes in one level, which is not sufficient. It is important to check nodes in each depth in groups based on the node on depth — 1. Compare these two cases:
ANS: No , because 3 and 4 have to be next to each other in the traversal path, whereas
the answer to this test is Yes. Unfortunately, I didn't finish my solution in time...
Can someone please tell me what is wrong with this solution: 42389932
Problem D
I'm trying to submit now, but it redirects me to this blog. Why?
You'll have to wait until system testing is done. Only then the problem will be added for practice.
https://pastebin.com/71wMF7nP Could someone help me figure out what's wrong> failing pretest 4.
7
1 2
1 3
2 4
2 5
3 6
3 7
1 2 3 4 6 5 7
Your code says "yes" to this, while it should be "no". Children of a node in BFS would be printed together. So, correct order is 4 5 6 7. or 6 7 4 5. Depending on 2 3 or 3 2.
Can anyone help why does this code give R.E on CF? For Problem E.
Works fine on Local Compiler as well as Ideone.
https://ideone.com/B8dFH9
[Resolved]. I was iterating and deleting the set simultaneously.
Great problem statements! No fluff and extreme clarity.
How to solve F?
The problem is equivalent to counting for every vi = 1 + i * (k - 1) the sum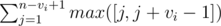 .
.
Assume that with two equal numbers, the one with higher index is larger.
To solve this, find for every i the values prev[i] and next[i], where prev[i] is the minimum index i such that maximum value in [prev[i], i] = val[i], and next[i] the maximum index such that the maximum value in [i, next[i]] = val[i]. Now:
Let cou[i] = the number of intervals [a, b] such that len([a, b]) = vj for some j and prev[i] ≤ a ≤ i ≤ b ≤ next[i]. We can calculate this with inclusion-exclusion: let count(len) be the number of intervals [a, b] such that len([a, b]) = vj for some j, and 1 ≤ a ≤ b ≤ len. Now cou[i] = count(next[i] - prev[i] + 1) - count(i - prev[i]) - count(next[i] - i).
The answer is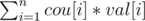 .
.
Oh, how can I not figure out how to do the last step.... it is so neat a solution...
same with me.I don't know why i didnt think of inclusion exclusion after doing the hard part.
Chic Explanation!
Also, mango_lassi, your named look quite cool, with yellow/orange :P Now red seems to go a bit awkward. Nevertheless, Congrats on becoming a GrandMaster.
You have to run this for each i and for each j, right? Then if the sequence is strictly decreasing and k = 2. Wouldn't this TLE? Or do you combine calculation for all j's together?
Cheater alert
http://codeforces.com/contest/1037/submission/42393185
http://codeforces.com/contest/1037/submission/42385717
Yeah

how can you find the 2 submissions?
While I was trying to hack, I noticed that those 2 submissions were too similar.
So both were in same room. Such probability. Wow!
I tried to hack someone but I got "generator crashed". Can someone tell me what that means?
Probably, your hack generating code had a runtime error.
Thanks!
my D will fail because I forgot about that a[0] condition :(
Well I explicitly removed the a[0] condition because I misunderstood the announcement, smh
What's intended solution for H? My O(n log2 n) solution got TLE on test 10. :(
Could you please share your idea with me? I tried to solve it with Suffix Automaton and Link-cut Trees but didn't manage to finish debugging in time.
I can suggest the following solution:
Build suffix automaton for string s. Append symbols to s one by one and answer queries whenever we reach their right border r. To answer the query with string x: feed symbols of x to automaton one by one and iterate over the next (bigger than current in x) symbol. Now we need to check is last occurrence so far of suffix of particular length of current state of automaton ≥ l. It could be done in the following way: consider the tree of suffix links of automaton, call it T. Then you append new symbol to s, update biggest right border for the state corresponding to the current prefix of s (we must also update right borders for all suffix links of that state, but lets don't do that and ask queries for maximum in subtree of T instead).
This is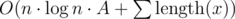 in a way I implemented it during the contest (and had wa2 due to some typos). I think it should pass (you will make much less queries than n·A).
in a way I implemented it during the contest (and had wa2 due to some typos). I think it should pass (you will make much less queries than n·A).
UPD: it passed in 405 ms 42402008
Thanks.
In fact my idea is very similar to yours, but I used Link-cut Trees to maintain maximum value in a sub-tree.
Due to the slow data structure, my solution is .
.
Username russianpig get hacked 6 times in a duration of 13 minutes, which sound suspicious to me.
How to solve... A?
solution =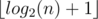
No, it is not. Your solution would fail if n = 2. log2(2) = 1, while answer = 2.
real solution = (int)(log2(n)) + 1
Edited. The wierdest part is that I actually solved the task :P
Hope it also passes the system tests.
I think the tricky part is not solving the problem but interpreting how you solved it :D
Same. I solved B and C, wasn't able to solve A. I feel like an idiot as everyone got the logic within 5 minutes.
Every number has a primary representation. And never does it happen that you use some power of 2 twice. Thus get all powers of 2 lower than this number! That is (int)log2(n)+1.
So, again, does this problem actually has something to do with prime numbers? I was dancing around those bastards, and almost got an idea, but it seems that it's just powers of two, right?
Why tho? Some link from that "acquisition" (Aha!) effect is missing and I don't understand which exactly.
I really don't get the intuition behind using powers of 2. Why powers of 2 only, Why not other numbers ?
Because every number can be written as sum of powers of 2.
But it can be written as powers of 3 too.
No. Try writing 6 as sum of powers of three using each power of three only once.
Oops! Many thanks! I got it. That really helped.
Welcome :)
Because you have 2 options for each packet, either use it or not.
Edit:
The idea can be generalized. For example, Say, the question was to find the number of packets required to represent every number upto n, and each packet with value x had 3 optional values (we could only use one option for each packet) -
1) 0,
2) x,
3) 2x.
Then, we would require ⌈ log3(n)⌉ packets to denote every number < n.
Hmm that makes sense. Maybe that's why we can't use powers of 3 right ? Where exactly would using powers of 3 or some other would fail ? I can't seem to imagine.
if you want base 3 you need 2 pack each size to get 3 choices. so it would be larger no. of packets.
Yes! I've got the logic. Thank you!
I edited my comment for a general case, where using powers of 3 would be applicable.
Finally understood your update. Misunderstood it at first.
Now that i got it. It refreshed my number systems knowledge with a different view.
int(Log2(n))+1. By induction, a packet of 1 gives you 1. and for packets 1, 2, 4, ..., n, you know that this combination gives you from 1 to 2n-1. So adding 2n will give you 2n itself, and 2n+1, .... all the way to 2n+2n-1 = 4n-1 = 2(2n)-1
How do we know that this combination guarantees minimum number of packets. What's so special about powers of 2 ?
Every number can be represented as its Binary equivalent, so think of 13 as 1101 in Binary, ie one packet each of 1,4,8. Splitting in powers of 2 ensures that every number can be made using at most one occurrence of each power.
The question was: can you prove optimality for this construction? What if for some n there is a better split than binary?
The only other way I could think of splitting (in such a way that every number below x could be produced by using at most one occurrence of each packet) is by splitting into multiple packets of 1. I guess these are the only two ways which satisfy the conditions, and among them binary one would use less packets.
Well, no, seems like there can be many other optimal answers: for example, 5 units can be split into (1,1,3), and (4,3,1,1) make 9. I hope for someone to publish a formal proof.
Yeah you're right, there could be multiple ways
yes we can prove that it is optimaly to use powers of 2 as a base to generate 1 to x, consider you have n buckets of number(1,2,4,..2^(n-1)) those numbers can generate 2^n ****different numbers**** and all this numbers are between 0 and 2^n-1 so if we get the binary representation of x and let d is the highest significant bit so let x=1000010101 if we want to generate all number less than x and the highest significant bit is less than d we want n-1 number and these number generate 2^(n-1) different numbers and finaly to get x we only need one another number wish is 2^d and like this you get all number between 0 and x with least size of bucket
How do we know that this combination guarantees minimum number of packets. What's so special about powers of 2 ?
In Java, it's one liner:
out.println(32 - Integer.numberOfLeadingZeros(n));Can you explain please ? How's that working? Seems like some play without counting the bits.
The answer is basically minimum number of bits to represent n (which is also sufficient to represent any value smaller than n). Integer is 32-bit and you count the number of zeroes in the beginning of the binary representation of n, 32 minus that count gives you the number of bits needed.
2^3=8 now if u want to make any value which is <=8. Than you will need only 2^0,2^1,2^2,2^3. You need each of those 4 value at most 1 time for making each value which is <=8. For example 7 can be made by 2^2+2^1+2^0. We can use this property to solve problem A. Sorry for bad explanation.I can't explain well but I tried my best.
Got it. Thank you!
also, out.println((Integer.toBinaryString(n)).length());
Here is my intuition. At each step we can generate everything from 0 to x. We start with 0 as we can always generate. The next packet we should add is x+1. Now using all these packets we can generate everything from 0 to 2x+1. If we can't add x+1 as it exceeds n, just add the rest and it will be the last packet.
((Sorry for my bad english ㅠ~ㅠ I'm not englisher)) I have two question. 1. I didn't lock during Round. than I can't hack?
What is ?? at page [Standing]? ( http://codeforces.com/contest/1037/standings )
i solve A and B during Round and failed C. than what is in [problems]? ( http://codeforces.com/contest/1037 ) I am now A red-B none-C red
Just wait a little (15 mins), all the colors will settle and everything will be much clear,
Thankyou Everyone. I get know about my question!
I was wondering why I did well this contest, and then I realized that most of the really good people are at IOI right now.
whats wrong with my solution for problem D? I check distances from vertex 1 to a[i] it gives wa4. Who can help? Thanks in advance.
Check this:
Input:
Output:
Output for the second case
1 2 3 6 7 4 5 , should be "No"
yes, you are right, maybe second can be : 1 3 2 6 7 45
thanks for your help
In problem D, can the answer be YES if a[1] is not 1 ?
No. It is told "valid BFS traversal of the given tree starting from vertex 1".
can you please tell me what mistake i am making http://codeforces.com/contest/1037/submission/42395202 i am getting WA on test 11.
For problem D is it sufficient to check if for the given order, the levels are increasing and the parent indices are increasing?
Parent indices aren't bound to increase:
I'm sorry if there's any other definition of parent indices, but according to what I mean, the parent indices are increasing in this case because 3's parent's index is 1 and 2's parent's index is 2. I am referring to the index of the parent in the given traversal.
Then you seem to be right, plus you'll have to check if
a[1] == 1.They need to be level wise, as well as in same order as their parents. So, for input like-
5
1 2
1 3
2 4
3 5
"1 2 3 5 4" is wrong, as 2 came before 3, so children of 2 should also come before children of 3.
Aside from D's pretests, this year's problemset is much better compared to the last year.
Easy solution for D: for each vertex sort the neighbour list by the order they appear in the given sequence.
Then perform a standard BFS from node 1 on the tree and check if your BFS sequence is equal to the sequence in the input.
Used the same approach keeping priority_queue as adjacent list but got hacked. Can you please explain this case, 2 1 2 2 1
why this should give "No"? mine gives "Yes"
It is told "valid BFS traversal of the given tree starting from vertex 1". In your example BFS is starting from vertex 2.
I was using binary search without sorting the vectors in D...corrected the bug in last 10 seconds,,,couldn't submit it...The world doesn't want to see me purple :(
std::set<>
Many a times I have realised that set is a better alternative but my bad :(
There should be auto refresh of problem statement whenever it is updated.
First time I managed to solve 4 problems, feels amazing :D
Today I encountered an extremely strange behavior of std::stack. I managed to fail today's F problem because of the vector of stacks (42392892). What is strange: I've got an MLE verdict. After the contest I changed the vector of stacks to the vector of vectors and got AC with 20 MB (42402332). Does anyone know what's wrong. Don't I know something about std::stack? Why does it consume so much memory. Or maybe it's just stupid me and I don't know how to use it?
Cppreference on deque (stack uses deque as underlying container)
Hope that helps
Wow, at least I've got a valuable experience. Thanks!
Well...
"The standard container classes vector, deque and list fulfill these requirements. By default, if no container class is specified for a particular stack class instantiation, the standard container deque is used."
Why tho?
Any hint for my solution 42402189 of problem D ? I got Wrong Answer on testcase 11 .UPD: Accepted
Your code gives "No" on following input-
4
1 2
1 3
3 4
1 2 3 4
Who is DearMargaret? LGM in 8 contests. Seems like a fake account, but I wonder whose.
There's no fake account when it comes to being LGM :)
it was a good contest,i could have become candidate master today if i had solved D more fastly
Seems like there are three groups of problems in this contest. [A-D], [E,F], and [G,H]
1 2 1 5 2 3 2 4 5 6 1 5 2 3 4 6
How is this not a BFS Traversal of the given tree?
You start at 1, visit the neighbors 5 and 2 and put them in the queue. Then you are at node 5, visit the neighbor 6 and put it in the queue -> Error
Following the BFS,
5 22 6I solved D by comparing the precedence of parents of ai and ai + 1.
Got TLE in F because cin ( even with sync_with_stdio ) I'll never use cin again in my life.
You didn't add
cin.tie(0), cout.tie(0);, with which your code ACs in 1653 ms. ClickHis code would have got AC if he used >= C++14, probably because of the compiler version.
I always used cin.tie(0); but I used to think that it made difference only when reading/writing alternately. Omitting it seems to hurt his solution's performance by no more than 100ms on >= C++14, but it hurts just enough on C++11.
You are right. In C++14 it passed with 1500 ms
By the way, nice idea of iterating through the smallest side to avoid the math work :)
Problem D. a [1] must be equal to 1. I missed it( I'm crying (
D problem : Don't know why it is giving wrong answer on 11th test case. My idea is I will keep on matching parent of an array element with front element and when all children of front element get finished I will pop first element of queue and start the whole process with new first element. Someone please look into it. My submission : http://codeforces.com/contest/1037/submission/42406584
got it!
How two learn trees and graph implementation and algorithms for competitive programming ? Any help would be highly appreciated !
Click
You can find related topics on left side.
Thanks :)
Can someone tell me why i am getting this error in my code it is working fine in my compiler 42407188
please help me i am not getting what is wrong
Didn't test or really check the code but i can see right away that your MAX is wrong, it should be twice as that, and since you got an overflow error that might be the cause
why this testcase for D should be NO? Can someone explain?
6
1 2
1 5
2 3
2 4
5 6
1 5 2 3 4 6
You visited 5 first, so you should visit 5's children first.
Can somebody tell me what is wrong with my code (42403836) for 4th problem.Actually I am getting WA on test case no.11 which is a large test case that is why I am not able to debug it.
Your code gives "No" on following input-
4
1 2
2 3
3 4
1 2 3 4
Yes, you are right
You overwrite k and that's why check correctness only on even levels. I'd rewrite your code with a simpler single counter loop, sets are an overkill. Here's another hack:
HI,shrubb i improve my code now i am not overwriting k,now your test case is also working fine but still getting WA on test case no. 11 , 42416659
In problem E Trips , If we had to find the largest group of friends which could go for a walk, Given the condition that at most 1 group can go for walk. (Extra condition added to the question is that all people going on walk should be connected by some links (possibly greater than one link) , the at least k friends of each person condition also remains there).
Then how can we solve this question?
You said that at most one group can go for a walk but think about it. If you had 2 groups that matched the criteria and you combine them, isn't the new group still correct? :) And about how to solve it. Think of the problem as reversed. If you know the group after all the m edges (friendships) are made then you can substract one edge at every step and calculate the new group. If you want the detailed solution you can look at the editorial but I suggest trying it yourself before.
It is not necessary that we can combine two groups. The intersection of the two groups can be a null set. And they both independently would be satisfying these conditions.
You can always combine 2 groups.
The rule is that if someone is in a group he has to have at least k friends in the same group.
Now if we have 2 valid groups and we combine them, every person will still have at least k friends because he already had those k friends in the small group.
Yaa right but if the question was to find the largest connected friends group. (The largest among all small group) then how can we find it?
We cannot combine 2 groups if they dont have any common person.
But Is It Rated?
we can do D in O(n) https://codeforces.com/contest/1037/submission/63933368