


I want to discuss a type of data structure that I (personally) haven't really seen get any attention. It doesn't really do anything special, but I still find it interesting enough that it should be at least noticed.
It is an alternative to Fenwick trees (aka binary indexed trees), in the sense that it solves the same class of problems, in a memory-efficient way (unlike segment trees or binary search trees). Although the implementation has a couple extra lines of code, (in my subjective opinion at least,) it is easier to visualize and understand conceptually when compared to Fenwick trees. In fact, my motivation for writing this is that personally I've had a hard time learning BITs and understanding them (beyond memorizing the code) and for a long time I've avoided them in favor of segment trees or (when time/memory restrictions were tight), a structure similar to the one I'll be describing.
With that out of the way, the sample problem we are trying to solve is the following: given an sequence of N numbers, execute two kinds of queries: update (increase the value at some index by some value) and query (print the sum of all numbers up to some position).
We are going to build a binary tree in which node #i holds the sum of numbers in some range centered in i. How would we build this kind of tree (conceptually) from a given sequence of numbers?
- we want to build a tree which covers the indexes in interval
[l,r)-- initially,[0,N) - recursively build the tree which covers
[l,mid)and set it as this node's left son - recursively build the tree which covers
[mid+1,r)and set it as this node's right son - the value in this node is the sum of the values in its children plus
sequence[mid]
Here's a visualization of what this tree looks like for the sequence (of length 6) {1, 10, 100, 1000, 10000, 100000}:
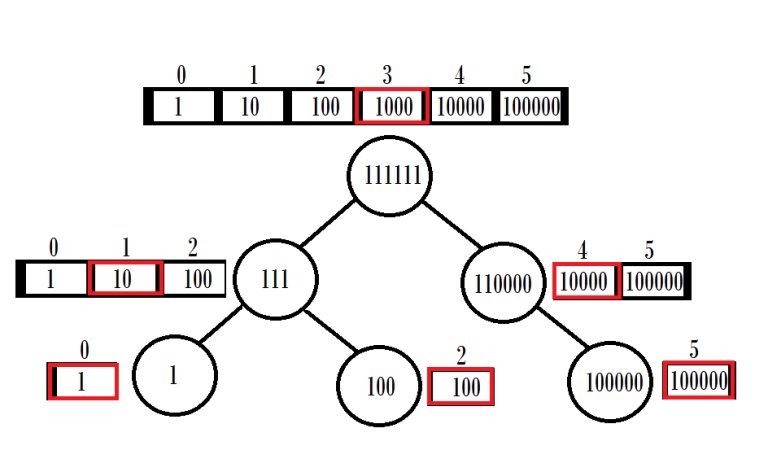
It is easy to see that such a tree has exactly N nodes and a height of ceil(log2(N)). The nice thing about this construction is that we can always represent it as an array of numbers of length N, in which the ith element corresponds to the value inside the node which holds a range centered in i. We also don't need to keep any pointers to the left and right nodes, since we can compute them on the fly.
Now let's get to solving the problem at hand.
How do you perform an update operation (i.e. increasing the value at some index by some value)? We start at the top node (which contains the entire array). When we get to a node, add the update value to this node's value. Then, if the update index is smaller than this node's index, we need to go to the left subtree. If the update index is greater, go to the right subtree. Otherwise, (if the indexes are equal), we can stop. Keep in mind that "this node's index" is given by the average of the left and right of the node's range. Sample code for this operation:
void update(int pos, int x) {
for (int l = 0, r = N; l < r;) {
int mid = (l + r) / 2;
tree[mid] += x;
if (mid == pos) return;
if (pos < mid) r = mid;
else l = mid + 1;
}
}
What about querying (i.e. asking "what is the sum up to a given position")? Again, start from the top. If the queried position is less than the current node's index, move the query to the left subtree. Otherwise, move to the right subtree, but we have to add all of the elements to the left and inside the current node. In other words, if current node is represented by range [l,r), when we make the leap to node [mid+1,r) (the right subtree), we have to add all elements inside range [l,mid]. We don't have this value explicitly (left node holds interval [l,mid), not [l,mid]), but we can obtain it by noticing that the sum [l,mid] is the sum [l,r) minus the sum [mid+1,r]. In other words, it is the value inside the current node minus the value inside the right subtree. Sample code for this operation:
int query(int pos) {
int ans = 0;
for (int l = 0, r = N; l < r;) {
int mid = (l + r) / 2;
if (pos < mid) r = mid;
else {
ans += tree[mid];
l = mid + 1;
if (l < r) ans -= tree[(l + r) / 2];
}
}
return ans;
}
You can make various modifications to this structure. For example, you can implement single-pass range queries (currently, if you want to know the sum from an interval, you have to take the difference of two queries), which in offers better performance (even when compared to Fenwick trees, in my experience). You can also easily implement range updates with lazy propagation (the same way you would do it for a segment tree).
For sample problems, any problem which uses Fenwick trees will work, really. This is an educational problem for learning Fenwick trees. The memory limit is low to prevent segment tree solutions. The page is in Romanian but google translate works wonders.







Probably nobody explained you Fenwick trees properly, or you just tried to learn them from the wrong source. I had hard time too when I tried to learn 0-indexed Fenwick tree from e-maxx. I'll instead explain 1-indexed Fenwick tree (it is important!) in just 8 lines:
This is already enough, but here is a little bit more:
Number of elements in the sum is always 2^(number of trailing zeroes). To increase a single element do
i += i & -iin the cycle, to find sum doi -= i & -i.For example, if you increase element 5, then the sequence
i += i & -igoes through elements 5, 6, 8, 16, 32, ... and so on. If you need to get sum up to 13, the sequencei -= i & -igoes through 13, 12, 8, and stops on 0.As an exercise: write a function "the smallest index with sum up to this index >= s" in O(logN).
I know these things now. In fact, the educational problem I linked has that kind of query included.
I still mentain my point that this binary tree structure is easier to visualize and understand (though an article on topcoder does provide a nice vizualisation of Fenwick trees).
Anyway, the point of the post wasn't to undermine Fenwick trees or claim that they are a nightmare to undestand (they are not). It was just to provide an alternative.
P.S. by "understanding", I don't just mean understanding the code and being able to reproduce it, but rather possessing a deep undestanding of the strcture such that it feels "natural". For example, one thing that didn't feel natural to me was why
x & (-x)referenced the least set bit. I could see why it worked, I could even prove it, but it still didn't feel natural. Also, "deep understanding" means being able to naturally write extensions (such as lazy propagagion for example).In my mind at least, there's a difference between solving a problem and understanding a problem. Though one can then argue if understanding is actually relevant (see debates about computer-assisted mathematical proofs).
I had almost forgot the logic of fenwick trees, thanks dalex for reminding it again. ;)
This is just a static balanced binary search tree, not a specialized range-query data structure. Omitting the pointers, which you can efficiently compute on the fly, doesn’t really make something new.
Though, I agree with you that this should get more attention, at least for educational purposes:
Implicit key BST is pretty much the basis for this, yes, though I would argue it's not as much a "binary search tree", as just "binary tree". Search trees by definition have certain properties, which this tree does not care about.
Please note that this tree is much less poeerful than a standard BST. It is pre-built with a given number of elements and does not support inserting or removing.
I remember when talking with friends about this, I called it "a half-breed between segment trees and implicit key treaps", which I think fits quite well but is definitely an overkill for the kind of simple operations it performs.
Well, surely you can’t modify the shape of the tree. That’s why I called it static.
So does this static version:
Range queries rely on these properties.
While these properties do hold true for this particular implementation, they don't necessarily have to. The indexing can be done any number of ways. For example, instead of picking the "representative" of a range as the middle index, you can pick it as the first index and split the remaining range in the middle.
For the example above, you would get a tree that looks like this:
For this kind of indexing, it is no longer true that "all keys in the left subtree are lower" (maybe if you redefine the concept of "key"), but it does not matter. The updates/queries still work the same way. Hence why I say that this binary tree doesn't "care" about the BST properties (at the very least I would definitely say it does not rely on them).
P.S. : you can do the indexing in other ways, these are just some examples.
Well, yes. I was talking about (and praising) straight indexing only.