


SnackDown 2018 elimination round starts in ~8 minutes. Top 300 get T-shirts
Let's discuss the problems after the contest!
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3880 |
| 2 | jiangly | 3669 |
| 3 | ecnerwala | 3654 |
| 4 | Benq | 3627 |
| 5 | orzdevinwang | 3612 |
| 6 | Geothermal | 3569 |
| 6 | cnnfls_csy | 3569 |
| 8 | jqdai0815 | 3532 |
| 9 | Radewoosh | 3522 |
| 10 | gyh20 | 3447 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | awoo | 161 |
| 2 | maomao90 | 160 |
| 3 | adamant | 156 |
| 4 | maroonrk | 153 |
| 5 | -is-this-fft- | 148 |
| 5 | atcoder_official | 148 |
| 5 | SecondThread | 148 |
| 8 | Petr | 147 |
| 9 | nor | 144 |
| 9 | TheScrasse | 144 |
SnackDown 2018 elimination round starts in ~8 minutes. Top 300 get T-shirts
Let's discuss the problems after the contest!






Is it possible to move SRM?
How to solve ADIMAT, XORTABLE and EBAIT?
http://oeis.org/A241956
And how to use it?
I think it doesn't help much. Just use "Burnside's lemma" and min(n, m) ≤ 23 to enumerate all cases in one dimension then do DP in other.
for XORTABLE, we find connected components for each vertex and if we know value of this vertex then we can find all value for the component.
For each vertex, we can break down segment [L, R] to multiple segments and try endpoints of theses segment to find the one that fit.
How are you breaking down the segments exactly?
suppose you have L < prefix*** < R you can use segment [prefix000, prefix111] to find union with adj vertexes. Those prefixes can be found by prefix of L or R with at most 1 different bit.
Any ideas what we may have missed in EBAIT? We even wrote stress test...
If you used the Stern-Brocot Tree, there are cases in which the Tree may be very deep, as well as cases in which it is not optimal to take the LCA in the Stern-Brocot Tree.
I take care of tree being deep. idk about lca, I go down through Farey sequence
How to solve all the questions?
Is this what happens when you are out of touch for months or were the contest problems really difficult?
That's a part of 1st place team's AC submission to problem "Election Bait". As far as I understand, phrase "For each bus except the last bus from the last convoy, after the people from this bus cast their votes, party A must have strictly more votes than party B." means exactly what is written in commented lines. Can someone explain this?
Sigh. Rereading my questions about its original statement and the clarifications I received, I noticed that clarification was also unclear and could have been interpreted in either commented or uncommented way. I should have caught that.
Turns out that description was overly specific, but in the exact wrong way..
Not overly. It needed to be specified. (And in one of many wrong ways.)
Looks like the data (or statement) for EBAIT is incorrect. In the statement it says for all bus except the last one in last convoy, A has more votes than B; however most solutions understand it as for all buses not in the last convoy, A has more votes than B. We stuck on this problem for more than 3 hrs.
Same here, I stuck on this problem for 2 hours...
Yes, accepted solutions output
1 1for the following test case:Spent two hours due to this as well... luckily it was our only remaining problem during the last hour, but for other teams it might have been crucial.
Also I guess it's Radewoosh's time to joke about "notorious coincidence".
XD
SFXPAL may be solved in linear time using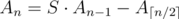 . Did anyone use it? Can anyone prove it? :)
. Did anyone use it? Can anyone prove it? :)
My team used it.
Our solution, also linear: https://www.codechef.com/viewsolution/21809749
https://oeis.org/A252700
How to solve it in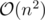 ?
?
You can use inclusion-exclusion with dp[i] = ways that last [i, n] is that first suffix is a palindrome
Does someone have a really rigorous proof of the above statement?
Call a string bad if it has a palindromic suffix of length > 1 and call an the number of bad strings of length n.
Now we can take a bad string of length n - 1 and put a character in front of it: gives us san - 1 bad strings of length n.
We can also make the whole string a palindrome: s⌈ n / 2⌉ strings.
However, the bad palindromes that have a smaller palindromic suffix were already counted in 1. So we subtract a⌈ n / 2⌉ such palindromes.
So an = san - 1 + s⌈ n / 2⌉ - a⌈ n / 2⌉ (the operation is ceiling if it ain't clear).
Why is the number of palindromes in 3. a⌈ n / 2⌉?
In 3. we're counting the number of palindromes of length n which have a palindromic suffix of length ≤ n - 1.
a⌈ n / 2⌉ is the number of palindromes with a palindromic suffix of length ≤ ⌈ n / 2⌉, so we also need to prove that if a palindrome has a palindromic suffix, then it has a palindromic suffix of length ≤ ⌈ n / 2⌉ (*).
If that's left out as obvious, then we don't need bad strings:
I think adamant and Vijaykrishna were asking for a proof of (*). It's not hard: if is a palindrome and has a palindromic suffix of length k where k > ⌈ n / 2⌉ then for i ≤ 2k - n
is a palindrome and has a palindromic suffix of length k where k > ⌈ n / 2⌉ then for i ≤ 2k - n
and the suffix of length 2k - n is also a palindrome and shorter
Yes, I figured this proof out later by myself, but thank you anyways for the elaborate explanation.
I just made a brute force, searched for the solutions on oeis and found this:
http://oeis.org/search?q=Number+of+strings+of+length+n+over+a&sort=&language=english&go=Search
The straightforward dp is
I guess yours dp can be simply proven using dp above.
This is directed towards Codechef organizers: I am going to explain why team azneyes (with ksun48) and moofest (with me) have basically the same code on ADIMAT.
We were both on MIT ACM last year, and did GP of Poland. We both recognized that the problem was the same as there, so we both copy and pasted our AC code from there. That's why the code is the same.
Can you give link of this GP of Poland's question ?
Problem I
Is there any judge where we can submit solutions to the problems of this GP of Poland ?
Here is the opencup contest, no idea if the problems are uploaded somewhere else.
Problems from OEIS, from e-maxx, from recent contest — well done Codechef, it was one of the worst contests ever.
Is the Codechef coordinator green or cyan?
Worst contest ever? I agree that repeated problem from opencup sucks and wrong testdata in Elections sucks even more, but many problems were quite original and interesting. I surely enjoyed this contest (maybe my impression would be different if I would have been solving elections not as my last problem)
Opencup isn't really "open" so not many people have access to the contests, how would they know that it is repeated?
I agree, problem from Opencup was a notorious coincidence, but still, there are two OEIS problems and one problem from e-maxx, and T-shirts were decided on them.
Yeah I agree with others. BTW, which problem is from e-maxx?
A problem about tree.
There is no exact code, but it is explained how this problem is solved. So this problem is just "write standard algorithm, without any changes".
Was there an OEIS problem? I solved all, but couldn't find it.
People in Discord say that palindromes and binary matrix can be found on OEIS.
Tbh, during my competitive career I have found some sequences on OEIS, but never managed to get a solution from there. Usually there are just 30 first elements with no useful info on how to compute it in the fastest way, but a lots of useless info about shitty generating functions or whatever.
So is something going to be done with Election Bait? In a situation when the statement is inconsitent with the test data, accepting all solutions that solve the problem correctly in at least one of the sensible settings seems like a fair thing to do.
Accepting all solutions that solve the problem according to the in-contest version of the problem statement (and changing either the statement or test data, whichever is more practical) seems like the best course of action, yes.
UPD: Should I take downvotes to mean nothing should be done? ( ͡° ͜ʖ ͡°)
Sorry, but this looks like wrong understanding. The way proposed by Endagorion was to accept solutions to both versions of the problem, not to pick one of them. So that the accepted solutions stay accepted, but additionally, the currently rejected solutions get rejudged with jury answers being answers to the other version of the problem. It requires some work on the organizers' side.
The misunderstanding is on your part. I said accepting all solutions that X, not "and rejecting all solutions that not X".
There will be a rejudge accepting both versions.
Sorry again, I just don't see how changing the statement helps rejudging with the other statement.
But anyway, looks like there's really no misunderstanding on your part, alright then :) .
Changing the statement is just for the future. Problems are available for practice after all.
Thanks! When can we expect the rejudge to be done?
It gets even worse because some of the translations may be entirely different kinds of wrong. For instance, the Russian statement misses any kind of formal explanation of the process (it just basically says "the party A should be winning until the very last moment", sic).
It shows that there should be no translations for important international rounds, unless organizers can really ensure the quality.
Translations are sometimes made using early versions of statements (before I completely rewrite them). Long Challenge started yesterday, so I had 22 problems to work on and only edited EBAIT today. Still, translations are there just for convenience and if someone gets something wrong because of not reading the main problem statement, that's just too bad.
In the preelimination contest earlier this year there was a bug in russian statement. The numeration of sides of the triangle is clearly different
https://www.codechef.com/SNCKPE19/problems/ANGLE
I prefer not to read translated statements since then :)
What's the point of making them if you have to read english statement anyway?
Agree. These creepy translations should be deleted. Some things are just too bad to exist.
You have to read the English statement if you want to be 100% sure what's going on. It might be simpler for people to speedread statements in their native languages. But idk, I don't decide that.
Since you brought up the long contest, in this month's challenge problem, the English statement does not explain how the input is generated but the Russian and Hindi translations do.
It seems that to be 100% sure you understand a CodeChef problem, you have to read the English statement and the translations.
The input in the challenge problem is generated in a secret way. Thanks for telling me, it should be removed from the translations — it can lead you to optimising your program's performance on wrong test data without realising it. (Go ahead and give me an implementation of connect().)
That's interesting, I heard the contest admin said the exact opposite: that the pseudocode will be added to the English statement as well, and to look at the translations in the meanwhile.
Glad this came up now when there's still plenty of time left in the contest to clarify things.
Of course, when I say something will be done, that's just what I think will/should be done. The translations are updated now.
If you think about this generator description, there isn't any area where it clearly tells you something. It doesn't let you reproduce tests with an identical distribution, since connect() is secret. It doesn't exclude any types of tests because the baseline is a random DAG and connect() is secret. OTOH, how tests are formed clearly affects the solution somehow (or it wouldn't be secret), which is something people might miss. It's better to avoid saying something misleading about test data.
The main problem with keeping translations accurate, especially when a small correction is made in a statement, is resources: time and people. Think about it, who will check the translations? Are translators supposed to monitor everything and triple-check for differences? I don't know any TL languages except Russian, so that's out. Problemsets are made late since there aren't enough setters, which means testing is often rushed, things change shortly before the contest, and sometimes something gets missed. Translations are the last part of the expected process "initial statement -> changes during testing -> final statement -> translations", and of course, when you parallelise, it's much easier to miss something. Plus consider that people who do everything have their own lives, for example I have a full-time job and usually fix statements in evenings when I have free time. If I'm on a trip somewhere with no net, you might get crap statements; this ties up to the "not enough time" problem.
In the end, the situation can't improve unless more good problems are proposed — that would push the whole workflow ahead. There are small improvements like more people checking everything, or not so many shitty non-statements where I have to divine what the setter wanted to write, but they don't affect so much.
In most serious competitions I've seen translations are treated as formal documents with equal power as official statements. If that is not the case, there probably should be a notice of that (e.g. "there's no guarantee our translations have anything to do with actual problems, idk lol").
In Chinese statement for SFXPAL we're told to modulo the answer with 1e9+7 instead of M. Luckily I guess most participants have noticed the extra number M in the input.
Problems were very interesting, enjoyed it quite a bit, even thought they were very difficult for me. If someone could elaborate on Adi and the Matrix it could be nice ^^
You have to use burnside lemma. THe group acting on the set of all binary matrices is (P, Q), where P and Q are permutations of length m and n respectively. Say the cycle lengths in the permutations are (l1, l2, ..., lk) and (L1, L2, ... Lr) respectively.
Now we have to find the number of binary matrices unaffected by the pair (P, Q). We will choose some Xa, b and rest will be set through equality conditions. For example, say we choose some index a from a cycle of length li and index b from cycle of length Lj. Then setting Xa, b will set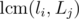 values. So overall, we have to set
values. So overall, we have to set 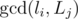 values to set all values for indices from the cartesian product of two cycles. Hence there are
values to set all values for indices from the cartesian product of two cycles. Hence there are 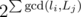 binary matrices fixed by the permutation pair.
binary matrices fixed by the permutation pair.
Now, assume n < m and for each partition of n, do a dp on the other dimension. The overall complexity is O(m2p(n)) or O(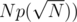 where N is the constraint on nm and p(n) is the partition function. Link to solution
where N is the constraint on nm and p(n) is the partition function. Link to solution
How to solve ADITREE ?
Choose any root. Observation: We have to take an edge from
vto its parentpin our optimal connection iff the number of light-on houses in subtree rooted atvis odd.So you can keep in
val[v]parity of light-on houses underv.When you switch light in
vyou have to doval[w] ^= 1for each vertex on the path fromvtoroot.The answer to the query is sum of
val[v]for all vertices.You can implement those operations efficient using HLD/centroid decomposition.
How to solve it using Centroid Decomposition?
I figured out that when we switch the values of vertexes a and b, we need to flip the state of every edge on the simple path from a to b either from needing it in our pair connecting to not needing it and vice versa and just count the number of edges we need after every flip. This can be done with heavy light decomposition.
Link to my solution:
https://www.codechef.com/viewsolution/21809280
OK, so here's my turn to ask something about EBAIT. Not adressing issues connected to this problem, how did you manage to solve it? I see that many teams solved it, however it still seems to me like a really hard problem. I tried to solve it using pretty complicated black box that tells me number of lattice points in first quadrant below line with equation Ax+By=C. This black box is rally tough, but fortunately we had it prewritten, but I still didnt manage to fully solve the problem since I got lost in ocean of formulas. mnbvmar used some algorithm from Wikipedia about continued fractions, but this seems really weird to me and Errichto used some freaky Python function that solved it for him, both of these approaches look nothing at all how I would approach such problem (maybe that's why I didn't solve it?)
well, continued fractions seems to be reasonable directions to start from because they give you best approximations of things (with small denominators) and you want to get a good approximation to the start of interval(which is less then end of an interval)
A way how I see this problem:
You basically have the following inequalities:
After some hard math I managed to get this:
So you need to find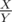 between
between 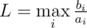 and
and 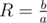 . I used Stern–Brocot tree to find the closest to the root fraction that lies between L and R. You can also use this.
. I used Stern–Brocot tree to find the closest to the root fraction that lies between L and R. You can also use this.
It's called Stern-Brocot tree. If you google "Stern-Brocot tree site:codeforces.com", you can hopefully find this post where you can simply copypaste.
How about this: Try all denominators up to min(C2, 10000), compute the minimum numerator for each. If you didn't find a solution, try 1000 random denominators. If you still didn't find a solution, declare that none exist. AC in 0.05s.
So, there's no testcases where there's a single denominator which fits and is quite big (~1e9)? Sounds like bad test suite to me.
Can they be made? How about an extended version with trying numerators up to 10000 too?
Well, I'm not sure, but something like this should work:
Let's get some fraction p/q, approximate it with all the denominators from 1 to c2 from the top and from the bottom. Get closest from both sides and set them as two borders.
Of course, you'll also need to construct testcase itself (didn't think whether it's trivial)
a b c dshould give a range (b / a, (b + d) / (a + c)), so at least any range with max-fraction having the bigger numerator and denominator is doable. When we account for irreducible fractions, that gives even more.When the range of allowed fractions is very tight, I'm thinking of some solution that discards ranges of numerators/denominators that clearly have no solution within the given range...
yep, so if you have p/q and r/s and p,q,r,s <= 5e8, you can always make s > q by multiplying both r and s with some constant. It will mean that r > p automatically.
Well, test suite was very weak for sure. For example naive solution with Farey sequence worked despite TLing on very small test like
There's a way to compute the number of points in integer coordinates inside the triangle (0, 0), (n, 0), (n, (a/b) * n) in O(log(A + B)) with a modified Euclidean algorithm. This is the same as computing the number of points in integer coordinates under the line y * b — x * a <= 0 for 0 <= x <= n. I used this to do binary search to find the first point between the two half-planes.
When will t-shirts be sent?
Will t-shirts be sent according to address on codechef profile ... or email queries on the address?