


Thank you for waiting! I hope you've enjoyed the problems. Let me know what you think in the comments!
UPD: I almost forgot but here are some notes, as well as challenges for all problems. For a lot of them I don't have a solution and would be happy to hear your ideas.
Tutorial is loading...
Challenge (awful)
Tutorial is loading...
Challenge (?)
Notes
Tutorial is loading...
Challenge (probably doable)
Tutorial is loading...
Challenge (?)
Tutorial is loading...
Challenge (???)
Notes
Tutorial is loading...
Challenge (probably doable)
Tutorial is loading...
Challenge (?)
Notes
Tutorial is loading...
Challenge (running out of ideas)






In 1368A;C+= a=5, b=4,n=100 why the output is 7??
Video tutorial of A,B,C,D
Please give feedback on my video.
you are doing great job sir
The explanation is awesome. I don't know why so much negative review on it .
Can someone please explain the problem B solution ? I am not able to get from editorial.
For simplicity, consider 'abc' subsequences. An optimal string would look like aa...abb...bcc...c. The number of 'abc' subsequences in this string is = count('a') * count('b') * count('c').
We need to find these counts such that their product >= k while also minimizing the string length. This can be achieved if the counts are as equal as possible (this is just greedy, you can try out some examples). So we can initialize the counts to 0 and increment the counts by 1 in cyclic order until product becomes >= k.
For example, if k = 18, a possible solution could be 3, 3, 2 and the string would be 'aaabbbcc'.
https://codeforces.com/blog/entry/79027?#comment-645275
Try This video Solution: — https://youtu.be/xpFsAU4wTLg
Great contest! Though, I had a doubt regarding a different version of B, which I initially misunderstood the question for. What will we do when we will want exactly k subsequences? (Assuming that an O(N^(1/2)) solution is good enough) Can we simply keep on multiplying the count of a letter by the smallest prime factor of the remaining k(dividing k at each step) and then move on to the next letter(of the cycle) and keep on doing so until k=1?
I misunderstood the question during my first try. I thought that we have to find exactly K subsequences. So I calculate all the prime factors of the given number, multiplying the count of a character by the prime factor in a circular manner. I think this will be the optimal answer. You can check my wrong submission if you want to have a look.
Yes, but my question’s if your method is right for the question you miasassumed at first!
I think so but I am not sure.
Circular manner won't work. If the count of all the prime factors (multiset) is greater than 10 then we must keep multiplying the smallest two numbers and replace them with the product, untill the size of our multiset is exactly 10. And in case if the size was less than 10, then add the required number of 1s in it.
It makes much sense now thanks
Are you sure about this or we have to apply some sort of dp to calculate the minimum sum of number, multiplication of those lead to k?
I think so, this should work. Take an example:
k = 2*2*3*5*7 String = abc
So, we want 3 integers, such that their product is k and their sum is minimum possible.
Multiplying 2 and 2 gives us k = 3*4*5*7 Multiplying 3 and 4 gives us k = 5*7*12
Length of the string = (5+7+12) = 24. This is the best answer we can achieve.
In k = 2 * 2 * 3 * 5 * 7 we can multiply 5 * 2 = 10 and 3 * 2 = 6 so our final result is 6 * 7 * 10 = 23 is the minimum answer
Oh then my approach is wrong . We'll have to find another way to minimise the sum
I think the only way is now using dynamic programming. I will try to find the solution using dp.
O(N^(1/2)) solution does not exist let alone good enough. If I give you a prime number K > 1e9 then you would have no choice but to print exactly K of any letter in "codeforces". The only prime factor of K is itself. Other than that I think Akshay has a correct solution.
Right, thanks!
It is wrong. You have to take a min heap and multiply the two smallest element until the size of heap is greater than 10.
Btw, there is an extra challenge for problem B. (I wrote about it as my puzzle.)
As mentioned in the editorial, the approach may not work well for subsequence other than "ABCDE" and "CODEFORCES". Could you find such string?
Take str as “well” and k=3. “welll” should suffice here, but according the aforementioned algorithm, we have to use “wellll” which isn’t optimal
Yep, that will do (tho the original algorithm will have "wweell" instead).
Any idea if two adjacent letter must be different? :)
Take the string as "abcbc" and k=5. Now, according to the algorithm we have "aabbccbc". But, due to the repeated sequence of "bc", we can take the string as "abcbcbc"(which has just two characters extra). This will give us exactly 5 subsequences of "abcbc".
In your example,There are 5 subsequences instead of 6
You're right. I'll correct it at once. Taking k=5, the counter example still holds!
On the string "codeforces" the algorithm will work but what should be done if we had a same question with any string in general?
I made a video explaining problem D because I really liked the problem — https://www.youtube.com/watch?v=oHgcHjk2fIM
There are many people with these videos, so let me know if it's worth doing more, thanks!
(Well, I liked problem E too, but I didn't solve it during the contest!)
The 'smaller value of k' leads one to think, the question requires the minimum value of k in Problem C. Otherwise a good problem set!
Are the rating changes adjusted for the fact that this was open for both div. 1 and div. 2? Personally it felt a bit unfair as difference between d and e was huge and i saw many expert coders who got under 2000 but still had negative rating change. Doesn't it discourage div. 2 coders not to participate in combined rounds?
Cause they are very close to Div1((1880-1899) what I found in rate changes). They are in top 2000, but for them, it is not good enough.
"We divide them into three sets $$$V_0$$$, $$$V_1$$$, $$$V_2$$$."
How?
Look at tourist's solution : 84233462, if path[u] is 0, u is in V0, if path[u] is 1, u is in V1, if path[u] is 2(later -1, for generalizing max operation), it is in V2.
Among other things, he sorts the the vertex by label. Why? What is the meaning (in words) of path[]? More formally, what have the labels of the vertex to do with the solution? Or more common, what is the idea of this solution?
I completly do not get it.
He sorted the adjacency list g, but did not use it(he used gr instead). So, My guess would be that it was contained in his previous solution, and hence has no use. Also, note that he uses reversed graph to like relax every node on the basis of incoming paths(and not outgoing paths).
The idea part:
After relaxing every vertex u, path[u] can only contain one of {-1, 0, 1}(Already denoting three sets {V2, V0, V1} respectively).
Notice that he is using reversed graph(for incoming edges).
He is relaxing in topological order(from 0 to n-1) in gr(and not g).
For a vertex 'v' if all the vertices 'u', which have a an outgoing edge to 'v'(i.e 'u' ---> 'v'), are deleted(i.e they are in V2 or their path[u] is equal to -1). In this case, maximum incoming path length to 'v' is 0, hence it should be in V0.
For a vertex 'v' if it has an edge incoming from a vertex in V0 and no incoming edge from vertices V1, it means that the maximum length path to 'v' is 1, and hence should be in V1.
For a vertex 'v' if it has an incoming edge from any vertex from V1, then max path length upto 'v' is 2, and hence should be in V2(deleted).
You can traverse them in topological order and assign each vertex distance mod 3. let say dist[i] represents distance of ith vertex mod 3,
for all adjacent vertices j, dist[j] = max(dist[j],(dist[i] + 1)%3)
V2 is the set of vertices with dist[i] = 2,
My submission
https://codeforces.com/blog/entry/79027?#comment-645275
what is contribution in profiles?
Better editorial to problem D
https://codeforces.com/blog/entry/78987?#comment-644649
problem D was beautiful.And the part which i liked about the contest is you have to come up with a solution after that coding part is really easy and short.
In problem 5 what does "in topological order" means and in which set a vertex with no incoming edge belong to ?
Can Someone please explain E in a simpler fashion?
In E, we can make a directed graph with given nodes and edges. Here I will call a closed node as deactivated and an open node as activated.
So, a node 'x' will be activated if none of its activated parent nodes are having any activated parent , otherwise it will be deactivated. (Greedily)
Now suppose there are y activated nodes whose parents are also activated. No. of distinct parents they have must be greater than (y/2) (As each node has atmost 2 children).
Now no. of distinct child they can have is 2*y.
So for y + (y/2) = (3*y/2) activated nodes we can have at max 2*y (All childs) deactivated nodes.
So for total (3*y/2) + 2*y = (7*y/2) nodes we can have at max 2*y deactivated nodes. Hence For n nodes we can have at max 2*(2/7)*n = (4*n/7) deactivated nodes
Thanks a lot for the explanation!! It's much clearer now!
cool ! I love your explanation!
Thanks
Do check out our video editorials-
A: C+=
B: Codeforces Subsequences
C:Even Picture
D:AND,OR and Square Sum
Can someone help me understand the meaning of the line "At that point, all numbers should be submasks of each other." (question D). An implementation of the solution will also be appreciated. Thanks.
https://youtu.be/54lWTHW3DBE?sub_confirmation=1 Check it out
pls can anyone tell me whats wrong with my code?
You forgot to make the recursive call in the 2nd and 3rd if statements,you have simple returned (a,a+b,c+1,n) and not made the function call. :)
thank you very much
Happy to help :)
but still it is giving error
Your code is not working for the case where a=b, I have modified your code you can check it out here
in main function call ur function with c=0
i m calling the function with c=0;
ohh sorry ,my bad,didn't saw c=0
Just need a equal in the 3rd if and i got accepted with your code...
Your Edited accepted code
Great editorial for problem F, Thanks!
I need help in understanding, why my E approach does not work. I kinda proved it should work under constraints (If it does what I want it to do).
Algorithm as follows : First you check for all nodes without incoming edges ($$$V_0$$$). Then you make a set of nodes that these nodes touch ($$$V_1$$$). Then make ($$$V_2$$$) out of those accordingly. ($$$V_0$$$) Will never be spoiled, because no edges enter them. But ($$$V_1$$$) might point to another ($$$V_1$$$), making it ($$$V_2$$$) maybe.
So I keep track of votes for being ($$$V_2$$$). votes = how many edges from ($$$V_1$$$) enter this node. Nodes with nonzero votes are the ones we remove. Now go from top to bottom, and if we meet some node that used to be ($$$V_1$$$) but got voted by someone else, I put it in ($$$V_2$$$) and undo its votes, since it does not count as good any more. Since I do this from top to bottom, I only take necessary nodes in greedy way.
The answer should give different combinations of binary trees that are less than 3 in depth, and all of them have number of bad nodes $$$\leq$$$ $$$\frac{4}{7}$$$, and each node can be associated with one such binary tree, so the answer must be also less than constraint.
After the cycle, we remove $$$V_0$$$ $$$V_1$$$ and $$$V_2$$$, also changing incoming nodes from $$$V_2$$$ since they touch the rest of the graph and continue till we have $$$V_0$$$ empty
Sumbission : 84272118
How is making a pattern a CP question?
You have to find the pattern first
I had a doubt in Problem E. I tried solving it like this: Form the graph and remove only those vertices which have both incoming and outgoing edges. As I remove a vertex, I also update the graph accordingly. I tried to analyze the number of vertices that I will be required to remove in the worst case. For that, we can consider the whole graph as a binary tree and what my approach is doing is that it is removing all the vertices at even levels (considering 1 based indexing of levels). In this case, the maximum vertices that will be removed will be n/2 which is less than 4n/7. However, I am getting the wrong answer on Test Case 7. Can somebody give me a counter-example or tell me if I am making a mistake somewhere. Thank you. Here is my submission link: https://codeforces.com/contest/1368/submission/84306393
But the whole graph is not a binary tree.
The verdict of your submission is clear. You deleted 6 nodes in Case 137 of Test 7, while there are 10 nodes, so you can delete no more than 5.
Thanks for the reply. Yeah, that is the issue, I am not able to understand how come the answer is exceeding n/2. I think I will have to work out some test cases to check that. I have not been able to find any test case that fails until now. If you have a test case that you can suggest, it would really help.
1 — 5 1 — 6 2 — 7 2 — 8 3 — 10 3 — 9 5 — 11 6 — 11 7 — 11 8 — 11 9 — 11 10 — 11
i also tried the same thing ....but later understood that in this case no. of deleted nodes is
2*(n-1)/3 .. so it fails for n=10.
Thumps up for high quality descriptive editorial. By the way, in number c "The sample picture was a red herring". I stepped into that trap.
That feel when you AC C with an ugly solution...
I know that feel
You are not alone.
can any one explain the question part in D??? it says:
Beautiful solution for E.
Anyone know any algorithms for minimizing k, or interesting bounds on k for different constraints on the graph? Does this problem have an existing name in the literature?
"The same solution can be simply rephrased as: go from left to right, and remove current vertex if it is at the end of a two-edge path"I am writing an explanation vis-a-vis the correlation of the sets $$$V_0, V_1, V_2$$$ to the above algorithm,
Let, $$$V_2$$$ represent the set of all the removed vertices.
Now, the vertices that only have incoming edges from $$$V_2$$$ are the "roots" of a sub-graph that has been disconnected from the initial graph, let they be represented by the set $$$V_0$$$, the vertices in $$$V_0$$$ no longer have any incoming edges, therefore, they can't possibly be the endpoints of a path of length 2 or more, so according to the algorithm they don't have to be removed.
Similarly, all the "neighbours" of the vertices in $$$V_0$$$ need not be removed (they are the endpoints of paths of length 1), these "neighbours" form the set $$$V_1$$$.
P.S after reading this you can refer to the editorial for the upper-bound on the number of elements in set $$$V_2$$$, it's exactly $$$4n/7$$$.
Now, the vertices that only have incoming edges from V2 are the "roots" of a sub-graph that has been disconnected from the initial graph, let they be represented by the set V0, the vertices in V0 no longer have any incoming edges, therefore, they can't possibly be the endpoints of a path of length 2 or more, so according to the algorithm they don't have to be removed.How can you guarantee that the vertices in V0 do not have tracks to each other?
An Interesting Problem:
In problem B Consider
exactly kinstead ofat least k. I think it would be problem of finding number of factors <= 10 such that their sum is minimum. Prime value ofkwould be nightmare.i'm a little confused about E, is it saying to just remove the node if it looks like this?
0 — 0 — 0
then remove middle to
0 — X — 0
cuz i think a lot of solutions failed that when trying to greedy like that
Hello. I need help in problem E. My submissions: this close more than 4/7 n vertices and this may leave tracks with a length of 2 or more . I found counter test where this submissions don't work. Is this possible in this task? Why my solutions work? This test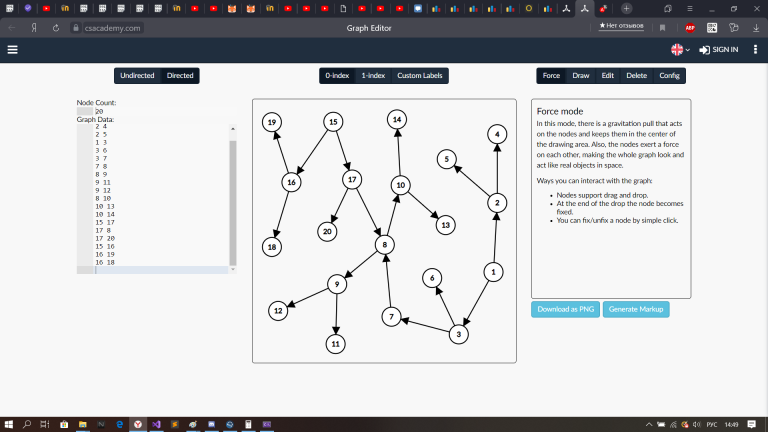 20 19
20 19
1 2
2 4
2 5
1 3
3 6
3 7
7 8
8 9
9 11
9 12
8 10
10 13
10 14
15 17
17 8
17 20
15 16
16 19
16 18
For all edges x->y the statement says that x<y is true.
A simpler solution for E problem:
Let's invert all edges in the graph, then for each vertex in graph no more than two incoming edges. Also for each edge u -> v, u > v. We will iterate over the vertexes in ascending order and for each vertex we will check whether there is a path of length 2 from it through not deleted vertexes, if there is then we will delete this vertex.
Note that for each deleted vertex there is an edge to not deleted vertex, from which also exists edge to not deleted vertex. Since after we inverted the graph, each vertex contains no more than two incoming edges. Then each not deleted vertex contains a maximum two incoming edges from the deleted vertices, but at the same time for such vertex with incoming edges from deleted vertices there is an edge to not deleted vertex, which means that the number of deleted vertices <= 1/2(for 2 deleted vertices which have an edge to same not deleted vertex, exists 2 not deleted vertices)
Here is the counterexample to your upper_bound = 1/2n.
Your algorithm removes 4 vertices = 4*n/7.
In problem E: sample test case 1: if we close both 3 & 4 ,how will we reach 4 from 2 since 4 is closed so there should be no incoming edge on 4? Kindly explain sample test cases of Problem E ?
In E question : Can someone please explain how paths and tracks are different from each other and if suppose this is our graph:
1 2
1 3
2 4
does it mean that 1, 2 ,3, 4 are on the same line?
https://codeforces.com/contest/1368/submission/84323789 can anyone tell me why is TLE coming in testcase 2
I had the same issue, you are initializing an array of size = 1e5, for every testcase, which is not necessary. Try using atmost linear space.
ok thx will try that
Can anyone explain me the solution of Problem D elaborately. what's happening there ? I am unable to visualize it .
I can try
For D we have to play with bits, That is when you and a ,b and simultaneously or a,b Total bits of a and b are preserved in the ored number that is a|b Thus when we have an array of numbers Out first priority is to set all the bits in some number because consecutive sum of squares of (2^n-1)^2+(2^n)^2. << (2^(n+1)-1)^2 By this observation I tried to accumulate available bits in only some of the numbers Not distribute it in all the numbers
So we will accumulate the bits in only some numbers . rest all numbers can be 0 . Lets say we have 4 bits of 0th place , 4 bits at 1st place and 2 bits at 3rd place then in total we will try making 4 different numbers which are 11 11 3 3.
And then finally we will find the square of these values. Carefully observe that by oring the bits and its frequencies are preserved. and by and the bits which are 1 in both the numbers stay preserved
I appreciate your efforts but still i can't understand it ..
Are you able to understand each of the following observations?
If so, try to think about maximizing the sum of squares while maintaining the invariant from #3
Why in E removing middle vertex in 2-edge path will not work?
All of the middle vertices could have tracks to the same end vertices.
Say you have this input
Removing the middle vertices would remove 4, 5, 6, 7, 8, and 9. This would be 6/10 vertices removed, and 6/10 > 4/7.
Worst case on that strategy approaches 2/3 with more nodes (need 1 first node for 2 middle nodes, only need 1 final node total)
In problem 5, Ski Accidents, What would the answer for this test case: 3 3
1 2
1 3
3 2
According to me, (4*3)/7 = 1, and by deleting any one node would satisfy conditions. That is, the answer should be 1 1, 1 2, or 1 3. But in most of the accepted solutions, it is showing 0 as the output answer. Am I right?
Even my accepted solution is also printing 0 as the answer.
Sorry, my bad, x < y in every test case but test case I have given has x > y
I spent two hours trying to solve B, for exactly k subsequences, before i realized i miss read the problem. Anybody has an idea on how to solve this variation of the problem ?
My Doubt is for Problem C. Can Anyone Explain the Meaning of this line in Problem Statement of C:
"There are exactly n gray cells with all gray neighbours. The number of other gray cells can be arbitrary (but reasonable, so that they can all be listed)."
What i Understood with this line is :
if n=1 then a grid of four cells Can be the Answer(because it is satisfying all three conditions)
I Know i am wrong somewhere,Can Anybody Point out the Catch i am losing!
No, if $$$N = 1$$$, then the grid looks something like this:
011
111
110
where 1 represents gray cells. Here, only the middlemost cell $$$(2,2)$$$ [1-based indexing] has all gray neighbours. And notice all other gray cells have even neighbours. For extending to any arbitrary $$$N$$$, you can follow the pattern of editorial.
According to your example ,
The (1,1)Gray cell [1-Based indexing] is also surrounded by all gray neighbours and the number of neighbours are even too.Right?
No, notice that grid is actually infinite, so a gray cell needs to be surrounded by gray cells in all 4 directions (sharing an edge).
Oh! But According to this line in the problem statement,
"assume that the sheet is provided with a Cartesian coordinate system such that one of the cells is chosen to be the origin (0,0), axes 0x and 0y are orthogonal and parallel to grid lines, and a unit step along any axis in any direction takes you to a neighbouring cell."
I thought first cell would start from (0,0).
This is a bit conflicting right? blitzitout
Actually that thought never crossed my mind. The author mentioned that fact only when outputting the gray cells. But yes, you can clarify with the authors during the contest.
Sure Brother, Thank You So Much for the genuine explaination blitzitout
Thanks for making this grid for N=1, this observation made me change what was wrong in my approach, and then it got accepted.
For the solution to D, it's written that x^y+xANDy=x+y. But when you set x = 3 and y = 5 for example, the equation becomes 6+1=8 which is incorrect. Can someone help me understand this claim? Thanks.
The operations are OR and AND, not XOR and AND.
Though, I could clearly form an idea on C, I chose not to implement it. I hate those kind of problems.
Hi all, 1368D — AND, OR and square sum
Why?
2d(d+y−x), which is positive when d>0.
Thank you very much.
Auto comment: topic has been updated by Endagorion (previous revision, new revision, compare).
For the solution to F, I think $$$x + k + \dfrac{x + k}{k - 1} \leq n$$$ transforms into $$$x \leq n - k - \dfrac{n}{k}$$$, not $$$x \leq n - k - \dfrac{n}{k} + 1$$$?
Endagorion Could you please answer this?
Yeah, you're right, I was off by one. The answer still stays the same since $$$x \leq n - k - \frac{n}{k}$$$ is applied immediately before $$$x$$$ can be increased, so it can be one larger in the very end.
Can anyone explain the side note for the editorial of problem D?
Side note: an easier (?) way to spot the same thing is to remember that f(x)=x2 is convex, thus moving two points on the parabola away from each other by the same amount increases the sum of values.
Where is the "Contest materials" in the contest page? There must be something wrong.
One optimization for problem B could be initializing every occurrence of the letters in "codeforces" to n^(0.1). The resulting numbers (Nc*No*Nd*..)will always be greater than or equal to n^(0.1) you can realise it better if you know AM(arithmetic mean)>Geometric mean principle.