


Dear all, ABBYY Cup 3.0 online-part is over!
Thank you for participating! We are sorry for inconveniences with testings. MikeMirzayanov has informed us about plans to buy new testing machins. So we hope that there won't be such cases in the future.
Solutions are the following:
It was one of the easiest problems in the contest. A solution consists of considering several cases. The initial answer equals one. Firstly, let’s note that if there is a "?" in a string, so the number of every possible codes increases in 10 times. With the exception when "?" is at the beginning if a string so the number of every possible codes increases in 9 times. Next let’s consider the case when the letters are found in the strings. There are two cases here:
It is no need to realize long arithmetic here. As all the operations (with the exception of multiplying be 10 because of the "?" can be done by standard arithmetic. For multiplying by 10 you can simply output the number of required zeros.
To begin with the term “order of balls” conforms to commutation. And the constraint to number of kicking a ball conforms to the number of transpositions. The problem is to calculate the number of “suitable” commutations. The commutation is “suitable” means the following: if to divide the commutation into the loops then every loop will consist of no more than two elements with the maximum number of inversions equals 1. So you can solve the problem with the help on dynamic programming. For this purpose the function f(a, b) should be calculated, where a — is the digit 1 and b — is the digit 2 used in the problem. f(a, b) is the number of “suitable” commutations. One should note here that f(a, b) can be calculated using the following formula: 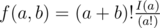 , where I(n) = I(n - 1) + (n - 1) * I(n - 2) You can prove it yourselves.
, where I(n) = I(n - 1) + (n - 1) * I(n - 2) You can prove it yourselves.
This problem has different solutions. Let’s consider one of them. Denote the initial image as T. There are two operations for T: erosion and delation. Erosion is an operation of substitution of all the pixels which refer to image and are contiguous with pixels of background for the pixels of background. Dilation is an operation which is similar to inverse erosion: we substitute the pixels of background which are contiguous with pixels of image for the pixels of image. For determination neighbouring pixels you can use 4-connected neighborhood. The beams will vanish and the sun will stay as only a circle after applying erosion operation to T for several times. Then we should apply dilation operation for several times. Note that number of applied dilation operation should be more than number of applied erosion operation. Denote the obtained image as P. Then let’s consider initial image T and sort out connected components corresponding to the suns. After that you should sort out parts corresponding to the beams. How do it? The pixels which are in the image T and which are not P are corresponding to the beams.
Firstly one should sort out the chains in the waiting line. The chain is a sequence of the beavers which stay one after another. After that the length of all the chains and the chain in which are Smart Beaver are known. Secondly one can simply apply methods of dynamic programming for further calculation.
Let’s move from initial matrix to the bipartite graph. The matrix elements (i, j) for which i + j are even should be place to one part, the matrix elements (i, j) for which i + j are uneven should be place to another part. The edges are corresponding to squares which are situated side by side. After that let’s weigh the edges. The edges which connect equal elements of matrix have weights 0, for unequal elements – weight 1. After that the problem is reduced to finding of the maximum independent edge set with minimal weight. Substantiation of above-stated is following: an answer to the problem represents a partitioning of initial matrix for pairs. Note that for any partitioning minimal number of changing matrix elements corresponds to the number of pairs on unequal elements. So in the optimal partitioning the number of pairs of equal elements is maximum. For solving minimum-cost flow problem is needed to use some effective algorithm. For example, Dijkstra algorithm with heap adding conversion of edges weights from Johnson's algorithm.
To solve this problem one should use segment tree. Let’s consider line segment [l;r] on this tree. For this purpose let’s introduce S(x), where x is integer. S(x) = F0 + xAl + F1 + xAl + 1 + … + Fr - l + xAr, where Fi – i-th Fibonacci number, Ai – the array which consists of even numbers. One should note that S(x) with x = 0, 1, 2… are similar to Fibonacci numbers. Id est S(x) = S(x - 1) + S(x - 2) for x ≥ 2. This means that for every line segment [l;r] one should memorize S(0) and S(1). To calculate S(x) for x ≤ 2 one could use the formula: S(x) = S(0)Fx - 2 + S(1)Fx - 1. So solving 2-type query is reduced to calculation no more than 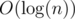 values if S(x) for different segment lines. The 1-type modification can be done by walking down the tree. For 3-type query one should use additional information in the tree and partial sums of Fibonacci number.
values if S(x) for different segment lines. The 1-type modification can be done by walking down the tree. For 3-type query one should use additional information in the tree and partial sums of Fibonacci number.
For a start one needs to learn to compare quickly any two substrings, which could be taken from the source string or from one of the strings, which corresponds to the rules. It can be done, for example, with the help of suffix array, that contains every possible input strings. After construction of such an array and calculation of LCP (longest common prefix) values the problem of comparison of two substrings reduces to computation the number of identical characters and comparison the characters, that come after identical blocks. Computation the numbers of identical characters are equivalent to a problem of calculation of minimum on the interval of an array of LCP values. Because the LCP array does not change, efficient resolution of such requests can be earned with help of RMQ algorithms. Thus, in time O(1) we can compare any two substrings. Note, that time of precomputing depends on algorithms used for suffix array building and construction of RMQ.
Further we need to find the number of entries of a certain substring from the source string into the string of one of the rules. It can be done with help of binary search of string of rule in suffix array. Note, that we are able to compare two substrings in time O(1). Therefore complexity of search of the number of entries of a substring into a string will be 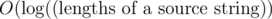 .
.
Now let’s consider a certain suffix of a source string. We know its LCP with the previous suffix. This is the lower limit for the number of the characters, which we are considering in this suffix. Note, that the number of entries of a certain prefix of considered suffix monotonously depends on length of this prefix. Therefore for each rule one can define by binary search what minimum and maximum length of a prefix can be, to fit this prefix for the rule. After, it is essential to cross all received intervals. It is likely that using another structures of data on strings can get a simpler solution. Technical realization of considered solution is fairly laborious.







The problems were interesting enough! Thank you!
First, consider the case that all people can only throw one time. Let's define the number of this cases of n people is I(n). The nth people have two possible ways to make loop.
(1) He himself is a group. The number of this case equals I(n-1), because he has nothing to do with other people.
(2) He and another one form a group. There are n-1 ways to choose another people, then these two person have nothing to do with others, so the number of this case (n-1) * I(n-2) So, I(n) = I(n-1) + (n-1) * I(n-2)
Now Consider the case that there're some people can throw twice, there's no limitation to these people, so they can insert to any loop's any position. If a loop has n people, then there're n positions can be inserted. So the number of all positions is the number of people. And an addition is he doesn't insert to any loop but to form a new loop.
Assume there're n people can throw only once, m people can throw twice, so the answer is (n + 1) * (n + 1 + 1) ... *(n + m — 1 + 1) * I(n) = I(n) * (n + m)! / n!
What does "loop" mean here?
Assume there're 5 people ,consider the permutation [2, 1, 4, 5, 3].
The first people's ball go to the second people.
The second people's ball go to the first people .
The third people's ball go to the fifth people.
...
We can use a directed graph to describe the case: (please forgive my baoman style)
And there're two loops in this permutation —— [1,2] [5,3,4]
To insert a people to a loop, just break one edge and add two new edges.
The limitation is only that a loop contains at most two people that can throw ball once, so the people who can throw twice can be inserted to any position.
AWESOME EXPLANATION! Thank you.
But How could the insert operation work?
please, upload these images to photohosting and give our the links only.
It's really huge :)
I completely know I(n) through your excellent explanation.But if you can explain the proof of l(n)*(n+m)!/n! in detail,I would be very grateful.
It seems that S(x) = F0 + xAl + F1 + xAl + 1 + … + Fr - l + xAr must be S(x) = F0 + x × Al + F1 + x × Al + 1 + ... + Fr - l + x × Ar in the solution of "Summer Homework". And there are more typos because it uses Fx + 1 instead of Fx + 1.
any hints on why S(x) = S(0)Fx-2 + S(1)Fx-1?
This formula holds for all fibonacci-formed sequence a0, a1, a2, ..., an. We can prove this by induction.
The inconvenience caused with the testing part was really frustrating. There was a time when I accidentally submitted a C solution while I had selected python, and I got to know after half an hour the mistake. Caused me a lot of rank loss. Anyways, nice problems and fast editorials.
Your graph is smooth...
my submission no. 3872882 was judged correct during the contest but after the contest it was judged as skipped can u check into the matter . i am losing 30 points because of that.
Probably, because of cheating with source code. If you write code on your own — contact administration and ask them to solve this issue.
good job Kenny
Because of that:3871903, 3872882
It's always funny to see how cheaters complain.
I am wondering how you found these two submissions.
He has wrote his submission number, and another i've found here: http://codeforces.com/contest/316/status , using filter.
good job
Suffix Automation is a good way to solve Prblem "Good substrings".It is very easy to implement and the code is short!
Hi,
Somebody could explain for me the "Tidying up" problem? :) I read this editorial and check some of solutions (e.g. 3873637 it is nice clean solution), but I don't see why this flow problem is equivalent with the original problem. Thank you..
Well, let's notice an obvious fact that if we want to put a pair of shoes into two adjacent squares, it's never efficient to remove both old shoes and replace them with two new ones. So, we build a bipartite graph, in which we need to find a perfect matching (an edge taken into matching means that we've put a pair of shoes into this pair of adjacent squares). So, 0-weighted edges mean that we just leave both shoes on their original place, and 1-weighted edges mean that we remove one shoe (and replace it with another).
Thank you for your answer! Why this is obvious fact? What is the mathematical explanation?
Why do you make me think instead of you? :)
Let's consider some facts.
Let's prove statement 4. Let's consider edges from matching as pairs (a[i], a[i + 1]). Since we have exactly two shoes of each type, these pairs can be split into cycles of the following form: (a[1], a[2]), (a[2], a[3]), ..., (a[n — 1], a[n]), (a[n], a[1]). So, you can fix either the first element of each pair, or the second one, and move the remaining element. So, for each edge from matching that connects shoes of different types, we need to move exactly one shoe. Q.E.D.
Can anybody plz explain why my solution gets RTE when i used long long int but gets AC when i used int data type...? i submitted same solution in different versions of C++ language... it's not the first time i faced this kind of problem... my solution link--> https://codeforces.com/contest/316/my