


In the first online round of Yandex.Algorithm competition 609 participants submitted at least one solution and 396 submitted at least one correct solution. Problems Non-Squares and Kingdom Division were fairly easy, both resulted in approximately 300 correct submissions. Problem Stacks of Coins was moderately easy and was solved by 145 participants. The three other problems proved to be more difficult. Stickers could be a very challenging string problem, but small input size allowed for dynamic programming solution, which 22 contestants got right. Assistants was solved by 13 participants; it required binary search, greedy, and some basic data structures to get it under time limit.During the contest, nobody was able to solve State Roads, which was a neat graph-theoretical problem with a simple to code, but a quite tricky solution.
Congratulations to Kenny_HORROR who was the only one to solve five problems, and to Petr, tourist, and eatmore who solved four problems and with negative penalty times also advanced to the final round.
The problem set of this round was brought to you by the Polish team: Tomasz Idziaszek ( Kingdom Division ), Jakub Łącki ( State Roads ), Marcin Pilipczuk ( Assistants ), and Jakub Radoszewski ( Non-Squares, Stacks of Coins ). Special thanks goes to Professor Costas Iliopoulos for suggesting the idea of the problem Stickers.
Solutions, test data and analysis were prepared by marek.cygan, monsoon, and jakubr.
Problem A (Assistants)
In this problem we need to find the minimum number of days in which n research tasks can be completed. The i-th task can be executed by the professor using pi consecutive days or can be delegated to an assistant who will execute it using ai consecutive days. Every engaged assistant can execute only one task, and the professor needs one day to find such an assistant.
First we show how to check whether the project can be completed in k days. Then it is only matter of using binary search to obtain the answer.
It is easy to see that there exists an optimal schedule in which the professor first searches for assistants, and then he executes unassigned tasks. Moreover, it means that we do not have to worry whether the professor executes his tasks during consecutive days. Formally speaking, if there is an optimal schedule in which the professor assigns tasks 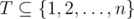 to assistants and he executes the remaining tasks (but not necessarily in consecutive days), then there exists an optimal schedule in which the professor delegates the tasks from T during the first #T days, and later he executes the remaining tasks (each task in consecutive days). Therefore, if the professor delegates the tasks from T, then he will finish the remaining tasks before the deadline if and only if
to assistants and he executes the remaining tasks (but not necessarily in consecutive days), then there exists an optimal schedule in which the professor delegates the tasks from T during the first #T days, and later he executes the remaining tasks (each task in consecutive days). Therefore, if the professor delegates the tasks from T, then he will finish the remaining tasks before the deadline if and only if 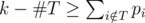 .
.
Now we show an algorithm which will check whether such T exists. We consider days d = k, k - 1, ..., 1, and during some days we will be delegating tasks to assistants. Assume that we are in day d and we already delegated tasks 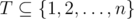 during days after d. Let
during days after d. Let 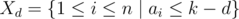 be the set of tasks which can be assigned in day d such that an assistant will complete them before the deadline. The main observation is as follows: if
be the set of tasks which can be assigned in day d such that an assistant will complete them before the deadline. The main observation is as follows: if 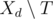 is not empty, then we can in day d greedily assign task
is not empty, then we can in day d greedily assign task 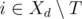 which maximizes the value of pi.
which maximizes the value of pi.
Now we prove it. Suppose that there exists a schedule S, which in the days after d is the same as our plan. If the schedule S assigns task i in day d, then we are done. Otherwise in the schedule S in day d the professor assigns task j ≠ i or executes task j himself (in this case possibly j = i).
In the first case, the professor assigns task j ≠ i. Then 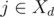 (since assistant will finish before the deadline) and
(since assistant will finish before the deadline) and 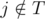 (we assume that S is the same as our plan in the following days). From our greedy choice we have that pi ≥ pj. If in S the professor assigns task i in day d', then d' ≤ d (since
(we assume that S is the same as our plan in the following days). From our greedy choice we have that pi ≥ pj. If in S the professor assigns task i in day d', then d' ≤ d (since 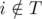 , and S is the same as our plan in the following days) and we can swap in S the days in which we assign tasks i and j. Otherwise, if in S the professor executes task i himself, then we can alter S as follows: we delegate task i in day d, and execute task j during these days in which the professor have executed task i (we can do that since pi ≥ pj).
, and S is the same as our plan in the following days) and we can swap in S the days in which we assign tasks i and j. Otherwise, if in S the professor executes task i himself, then we can alter S as follows: we delegate task i in day d, and execute task j during these days in which the professor have executed task i (we can do that since pi ≥ pj).
In the second case, the professor executes task j in day d. If j = i, then we can also delegate this task in day d (since 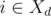 ). Otherwise, if j ≠ i, we can delegate task i in day d, and reclaim the missing day to execute task j in the moment in which the professor was working on task i (delegating or executing it) in the schedule S.
). Otherwise, if j ≠ i, we can delegate task i in day d, and reclaim the missing day to execute task j in the moment in which the professor was working on task i (delegating or executing it) in the schedule S.
In all the cases we get a correct optimal schedule in which the professor delegates task i in day d, therefore the key observation is proved.
How fast can we implement the above algorithm? Choosing maximum from the set can be implemented using a binary heap ordered by pi. When moving from day d + 1 to day d we add the elements from 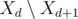 to the heap (i.e. tasks with ai = k - d; we need to sort the tasks by ai to do this), and we remove the maximal element (and we add it to T).
to the heap (i.e. tasks with ai = k - d; we need to sort the tasks by ai to do this), and we remove the maximal element (and we add it to T).
Observe, that we do not have to iterate over all days, but we can start from the day d = min(k, n), since there is no need to assign tasks after the n-th day. Thus the whole solution (with the fixed k) works in time  .
.
We can improve it by iterating not over the days, but over the tasks sorted non-increasingly by pi. Every time we try to assign task i in the latest day from {1, 2, ..., di} where di = min(k - ai, n) in which no task is yet assigned. It is not hard to see that the set T we get will be the same as in the previous algorithm. This assignment can be performed in almost-linear time, using the structure for disjoint sets. Each set contains the free day d and all the days after it in which some task are assigned. Now assigning the task boils down to finding the set which contains di, obtaining the minimal element d' in this set, assigning task i during day d', and joining the set with the set containing element d' - 1.
We can now estimate the final time complexity. Since assigning all the tasks to assistants is a valid solution, thus the answer will always be smaller than n + A, where 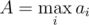 . Adding binary search, we get the solution which works in time
. Adding binary search, we get the solution which works in time 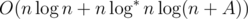 .
.
Problem B (Kingdom Division)
In this problem we are to divide an n × m grid into the maximum number of parts of distinct sizes formed by connected sets of unit squares. We need to present an example of such a division using characters from  to denote the resulting parts. A solution to this problem can be obtained in three natural steps.
to denote the resulting parts. A solution to this problem can be obtained in three natural steps.
In the first step we forget for a moment about the requirement of connectivity and ask what sizes of parts would imply the maximum result. The answer is simple, the sizes should be equal to 1, 2, 3, ... If the last part is smaller than required, we join it with the next-to-last part.
In the second step we note that the division proposed in the previous step is actually possible to obtain. We can cover the whole grid with a snake-like pattern and then cut the snake at appropriate positions to form the respective parts which will certainly be connected sets, see the figure to the left.
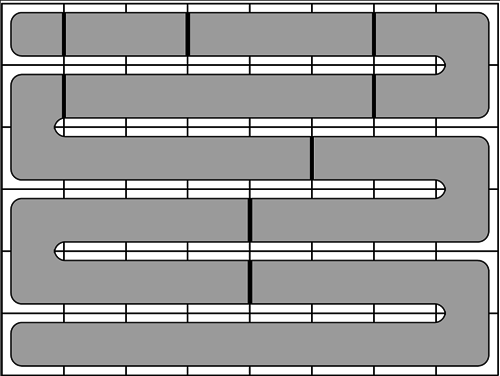 | 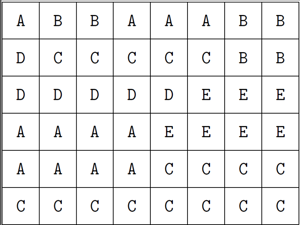 |
The third step is to label parts with the letters from so that no two adjacent parts receive the same label. A tempting idea would be to label them  in the order they appear in the snake. However, such a labeling does not work in some cases.
in the order they appear in the snake. However, such a labeling does not work in some cases.
One possible correct solution is to label each part with the smallest letter that does not occur among its neighbours (and perform the labeling in the snake-order). Another idea is to label the parts in the first row using the letters A and B, in the second row use the letters C and D, in the third row use the letters E and F, in the fourth row again A and B and so on (see the figure to the right). Starting from the point when each part covers at least one row, we can stick to just two letters, A and B. In the latter labeling we use only 6 distinct letters.
An interesting question is to find what is the minimum number of letters sufficient to solve every test case.
Of course the above algorithm can be easily implemented in O(nm) time.
Problem C (Non-Squares)
In this problem we need to check if a given positive integer n can be represented as a product of k positive integers all of which are not integer squares. Let us call such a representation a non-square representation.
A generic approach could be dynamic programming over the set of divisors of n. All divisors of n can be found in  time. Let D(n) be the number of divisors of n. It turns out that for n ≤ 109 we have D(n) ≤ 1344.
time. Let D(n) be the number of divisors of n. It turns out that for n ≤ 109 we have D(n) ≤ 1344.
We compute a 2-dimensional Boolean array 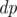 , where
, where 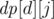 is true if and only if the divisor d can be represented as a product of j non-squares. The computation uses the following Boolean formula that works for j ≥ 1 and
is true if and only if the divisor d can be represented as a product of j non-squares. The computation uses the following Boolean formula that works for j ≥ 1 and 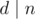 :
:
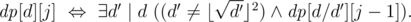
The time complexity of this solution is 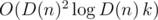 due to a map-like data structure required to keep track of the divisors of n. The memory complexity is O(D(n)k).
due to a map-like data structure required to keep track of the divisors of n. The memory complexity is O(D(n)k).
One could also improve the running time of this solution by noting that the parameter k is actually bounded by 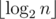 , which in our case is 29. Indeed, for
, which in our case is 29. Indeed, for 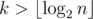 the answer is always “NO” (an argument for this can be inferred from the next solution).
the answer is always “NO” (an argument for this can be inferred from the next solution).
There is also a far simpler solution that examines the decomposition of n into prime factors. Let n = p1α1p2α2... pmαm where pi are distinct prime numbers. Then the solution is the following:
- If α1 + α2 + ... + αm < k then output “NO”.
- Otherwise, if m > 1 then output “YES”.
- Otherwise we have m = 1. If k - α1 is even, then output “YES”, otherwise output “NO”.
Let us provide some justification for this solution. Point (1) follows from the fact that any non-square divisor must have a prime factor. For m = 1, we simply need to check if α1 can be represented as a sum of k odd integers, which is possible if and only if the parity of k and α1 are the same. This yields point (3) of the algorithm.
Finally, consider point (2). We need to show that if α1 + α2 + ... + αm ≥ k and m > 1 then there exists a non-square representation of n. Let us take as the first k - 1 non-square divisors the prime divisors of n: first α1 times the divisor p1, then α2 times the divisor p2 and so on. As the last divisor, d, we take the product of all the remaining prime factors. If d is not an integer square, we have the requested representation. Otherwise we change the last divisor to d / pm and the first divisor to p1 pm, thus obtaining the representation.
This solution only requires to find the prime decomposition of n and works in time.
Problem D (Stacks of Coins)
In this problem m gold and silver coins are arranged into n stacks of different heights. We are to rearrange the coins so that there is a maximum number of unicolor stacks (a unicolor stack has only gold or only silver coins). We are allowed to perform any number of operations of swapping two coins that are located at the same height of different stacks.
Let k denote the result, that is, the maximum number of unicolor stacks that can be formed. Let us do a binary search for k. From now on we are left with a decision problem: given k, check if it is valid. Clearly it is optimal to try to make k smallest of the stacks unicolor.
Since the number of operations is not bounded, our problem can be reformulated as follows. Let h be the height of the k-th smallest stack. For each height level 1, ..., h we know the total number of gold and silver coins at this level. We need to check if these numbers are sufficient to create k unicolor stacks. This task will reduce to computing an intersection of O(h) intervals.
First we consider each height level separately. Assume there are gi gold and si silver coins available at this level and the k smallest stacks contain in total ti coins at this level. Using these numbers, we can compute an interval [ai, bi] such that 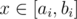 if and only if one can take x gold coins and ti - x silver coins to form the i-th level of the selected stacks. Note that such an interval implies the interval [ti - bi, ti - ai] for the number of silver coins.
if and only if one can take x gold coins and ti - x silver coins to form the i-th level of the selected stacks. Note that such an interval implies the interval [ti - bi, ti - ai] for the number of silver coins.
Finally we need to make sure that the intervals for different levels allow to find a valid solution. We iterate from the bottommost to the topmost level. For a given level i, we need to intersect the interval [ai, bi] with [ai - 1, bi - 1] and similarly the intervals for the silver coins. Thus we obtain a single updated interval [ai, bi] which we then use to update the intervals for higher levels.
The whole solution works in 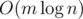 time.
time.
This problem has also a linear-time solution. Let gi be the total number of gold coins which are located on the i-th level above the ground. Let g'i be the maximum number of stacks which can be formed such that they have all gold coins on the i-th level and below. It can be easily computed using the following recurrence:
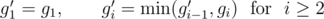
Similarly, we define si and s'i for silver coins.
Let hi be the height of the i-th stack, and suppose that stacks are sorted non-increasingly by heights, i.e. h1 ≥ h2 ≥ ... ≥ hn. We iterate over stacks and “color” them (making them unicolor) when possible. Suppose we consider stack i and we already colored stacks numbered 1, 2, ..., i - 1 in such a way that we got G gold stacks and S silver stacks.
The i-th stack can be colored gold if and only if g'hi > G. In such case we show that there is an optimal solution in which this stack is colored gold and stacks 1, 2, ..., i - 1 are colored the same as in our solution. Consider any optimal solution in which stacks 1, 2, ..., i - 1 are colored the same as in our solution. Let j ≥ i be the highest gold stack in this optimal solution (it must exist, otherwise we can add stack i and get a better solution). Now we can swap all the coins from the stack j to the stack i and, since g'hj + 1 ≥ g'hi > G, we also have sufficiently many gold coins to swap into the stack i above level hj.
Similarly, if we cannot color the i-th stack gold, but we can color it silver (i.e. s'hi > S), there is an optimal solution in which we can do this.
Otherwise we have g'hi + s'hi ≤ G + S, which means that we cannot color more than G + S stacks of heights not less that hi.
Since we can sort the heights of the stacks using counting sort, the above algorithm runs in O(n + m) time.
Problem E (State Roads)
In this problem we are given a graph in a dynamic setting. The set of nodes V is fixed, but the edges of the graph are added and deleted over time. We are to answer queries of the following type: given a set of nodes 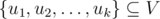 and a moment of time, check whether these nodes form one or more whole connected components of the graph in this moment of time.
and a moment of time, check whether these nodes form one or more whole connected components of the graph in this moment of time.
We present a randomized solution to this task, which is very simple to code, but also quite tricky. For each edge that is added to the graph we pick at random an integer weight. For each node 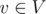 we store in
we store in 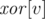 the
the 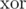 -product of weights of all edges that are adjacent to this node. Note that such values can be updated in O(1) time upon insertion and deletion of edges.
-product of weights of all edges that are adjacent to this node. Note that such values can be updated in O(1) time upon insertion and deletion of edges.
Now the crucial observation is that {u1, u2, ..., uk} forms a number of whole connected components if and only if each edge in the graph is adjacent to exactly zero or two of the nodes ui. Hence, to answer a query, we compute:
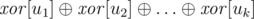
where  denotes the -operation. If the above value is non-zero, we know that the answer is “NO”. Otherwise with high probability the answer is “YES”. The probability of an incorrect positive answer is
denotes the -operation. If the above value is non-zero, we know that the answer is “NO”. Otherwise with high probability the answer is “YES”. The probability of an incorrect positive answer is 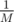 where M is the maximum weight of an edge. This probability turns out sufficiently small for M = 232 or M = 264.
where M is the maximum weight of an edge. This probability turns out sufficiently small for M = 232 or M = 264.
The whole solution works in linear time with respect to the size of the input.
Problem F (Stickers)
In this problem we are given n kinds of stickers s1, ..., sn, where each si is a word of length d. We are asked what is the minimum number of stickers needed to paste a given word t of length m.
We present a simple dynamic programming solution to this problem. Denote by dp[i] the minimum number of stickers needed to paste exactly the suffix t[i..m] and by  the same number, but when we allow stickers to overflow and cover positions from t[i - d..i - 1] (but not necessarily with correct letters). The answer to the problem is dp[1].
the same number, but when we allow stickers to overflow and cover positions from t[i - d..i - 1] (but not necessarily with correct letters). The answer to the problem is dp[1].
Let us see how to compute dp[i]. The i-th position of t must be at some point covered by a sticker pasted in this position. Since all the stickers have the same length, we can restrict ourselves to pasting this sticker as the last one or as the first one. This gives us two cases:
- For some j we have sj = t[i..i + d - 1]. Thus we can paste the suffix t[i + d..m] possibly covering letters from t[i..i + d - 1] and after that paste sj at position i. In this case we use
 stickers.
stickers. - We have sj[1..d'] = t[i..i + d' - 1] for some j and some d' ≤ d. Thus we can paste sj at position i and then paste t[i + d'..m] with restriction that we cannot modify the letters before position i + d'. In this case we use 1 + dp[i + d'] stickers.
If for every position i we know the maximum l[i] such that t[i..i + l[i] - 1] is a prefix of some sticker, then the case (1) is possible if d = l[i], and the outcome from the case (2) is equal to min1 ≤ j ≤ l[i](1 + dp[i + j]).
We compute similarly, but now instead of the set of all stickers we consider the set of all the suffixes of stickers. Thus we compute l[i] as the maximum number such that t[i..i + l[i] - 1] is an infix of some sticker.
The above solution can be implemented in the time complexity of O(mnd2). Surprisingly, this problem can be solved in linear time with respect to the size of the input, even with stickers of different lengths, but such solution is a lot more complicated.






