


Hello!
ABBYY Cup 3.0 is finished! Many thanks to everyone: participants, people who created and prepared problems and etc! The post about ABBYY Open Day will be later but now let's consider finals' solutions:
Problem A
Claim: If the walk starts from tree i and ends at tree j, then we need to cut down all trees before i, all trees after j and all trees with negative esthetic appeal between i and j. In order to solve subproblem A1 we could use the claim for each pair of trees with equal aesthetic appeal and choose the maximum; the constraints allowed to do this either at O(n2) or O(n3). In order to solve subproblem A2 we could use the following claim: whichever is the number of trees with equal esthetic appeal, we are always better off if we consider only a pair of the leftmost and rightmost of such trees. Then the number of the pairs of trees considered is reduced from O(n2) to O(n). Then we may proceed with either taking partial sums or calculating a sum on the interval.
Problem B
In order to solve subproblem B1 we may emulate the behavior of Beavershave as it is described in the problem. In order to solve subproblem B2 it is sufficient to store a raised unity-flag for each terminal beaver, where terminal beaver is such beaver i who does not have a beaver i + 1 on his right (that is, if we make a query which includes beavers i and i + 1, then we would have to run Beavershave one more time). If we swap beavers i and j, then we have four possible positions at which the status of the flag may change: i - 1, i, j - 1, j. A response to a query is then the number of the terminal beavers in the interval which is a classical problem.
Problem C
In order to solve subproblem C1 we could either calculate dynamics or subtract the largest number using greedy algorithm. It is easy to prove that it is always better to subtract the largest number. In subproblem C2 it is sufficient to calculate dynamics for the first million, divide (in head) the number into two groups of digits — low orders and high orders — and make not one subtraction, but a series of subtractions in order to instantly minimize low orders. In order to solve subproblem C3 it is necessary to store in dynamics parameters not the number itself, but only the number of digits.
Problem D
Obviously, the Beaveractor moving along the arrows will either get out or go round a cycle. If the latter is the case, we need to find the length of the cycle l, and then we need to find the remainder of dividing the time by the length of the cycle. Thus, we have solved this case. In order to solve subproblem D1 it is sufficient to emulate the behavior of the Beaveractor saving at each step the time of the visit of the current point (this way we will know the length of the cycle the moment we come to the point in the cycle from which we started). In order to solve subproblems D2 and D3 we need to construct a graph of Beaveractor's movements and then process each of the multiple tests. In D2 we may construct the graph in a straightforward way and find an answer to each test by going through the graph. In D3 we are supposed to use logarithmic data structures. The idea of the solution is, thus, clear. The problem is interesting from the technical point of view.
Problem E
In order to solve subproblem E1 we may use the following claim: If the edge x → y has marks x and y in succession, then such edge may generate the path of interest. Call such edge "initiating". It is easy to understand that the path in both directions is constructed unambiguously from the initiating edge. Now, it is sufficient to consider only initiating edges. Indeed, consider required path in a graph. It has p nodes and p - 1 edges. By pigeonhole principle at least one edge has two or more marks. Let some edge x → y have marks a b, (a, b) ≠ (x, y). Then cut this path in two by the edge x → y and note that one of the two subpaths has more marks than it has edges. Proceeding in a similar fashion we may come to the conclusion that there is at least one edge x → y with marks x and y. If there are no initiating edges, then the path of interest does not exist. The path which is generated by the initiating edge is the shortest valid path for a given initiating edge. We may add to this path incoming and outgoing tails in such a way that the path becomes longer. The tails should not contain initiating edges, because initiating edges generate their own paths. Any valid path is a path consisting of three parts (incoming tail, path of the initiating edge, outgoing tail) which are connected by edges without marks. In order to solve subproblem E2 we may count all tails and paths generated by initiating edges beforehand and then count the number of paths with a fixed length by dynamics.







Over 100 lines of code became a single sentence :)
I don't understand the explanation for C[23] at all. Is it just me or is this explanation a bit too short? I'd also have a hard time understanding B just using this explanation, if I hadn't solved it by myself.
Yeah, it is. This editorial ignores the large gaps in ideas for different subtasks — it focuses on the first subtask and only briefly mentions the other ones.
For example, the "logarithmic data structures": what are we supposed to store in those? It says almost nothing at all.
At least, my solution for D is:
in D2, we form a directed graph, whose nodes are states of Beaveractor's movement (x,y coordinates and direction) and one other node corresponds to "outside the campus"; each node has outdegree of 1. This means the graph splits to components, where each component contains at most 1 cycle. We determine those components, for each cycle its length and for every node its distance from the cycle and the node which we get to from this one after passing through b edges — using a BFS. Now, for each query where we go around a cycle, we can in O(1) time jump to the first node on a cycle that we get to, then apply "modulo cycle length" on t (which skips all the traversals of the cycle except the last one), which gives us t <= b^2. Now, while t > b, we jump by b edges, and then by 1 edge, which gives time O(b) per query with O(b^2) pre-computation. This is enough if we have a 6s time limit.
in D3, we can't store the entire graph, so we only remember ends of arrows as nodes. That's enough, because from any point, Beaveractor goes straight ahead until it comes out of the campus or hits an arrow, in which case it'll go straight ahead again until it hits a node (end of an arrow). Using the fact that there's at most 1 turn between any 2 nodes (and we can find where it happens using the mentioned logarithmic structures — an interval tree for vertical arrows — an arrow is an interval of y-coordinates and we remember there, which x-coordinate it has — in which I traverse the path from root to the x-coordinate of the given node and try to find a lower bound on x-coordinates of the intervals I see there and similarly for horizontal intervals), we can easily determine the position between any 2 nodes; the edges are weighted and for every node, we remember the distance and the node we get to after passing 1,2,4,8...2^20 edges (as there some less than 10^6 nodes in the graph), so we can make the skips not in O(sqrt(graph size)), but in O(log(graph size)) time.
Thanks for the nice explanation :) Can somebody explain the idea for C3 as well?
Let me try. First of all, in C2 we can do what's written in the editorial: split the number in two parts(6 digits each), now while the first part is fixed, all we need to know about it is the biggest digit. So we calculate two arrays: cnt[dig][n] — how many operations we need to get to negative number if we can subtract maximum of dig and biggest digit of n, and decr[dig][n] — what is the first negative number we reach this way(here 0 ≤ dig < 10, 0 ≤ n < 106). After that, we can decrease first part by one in O(1) time and that's it.
C3's solution is almost the same, we calculate arrays cnt and decr again using memoization, but we split the number into the first digit and remainder.
Thanks, this was helpful :)
^ Will you please explain "decrease first part by one". I did not get that.
http://codeforces.com/contest/331/submission/4317755 thanks for mmaxio's useful comment . this is a nice problem ... since we are using gready to subtract ... we can use dp. dp state :
dp[i][j]represents that the maximum digit of the previous digits is i, the number is j , the meaning of the state is the minimum number of time needed to make j become a non positive integer. Suppose we've got a number "NOW",eg (NOW=285678, j=85678) we also need to know what is the negative number "decr" that j will become and then subtract the absolute value|decr|from200000. every time , now's highest digit will decrease by 1 ,and this is our state transitionHow do you prove that the greedy algorithm is correct?
I'm just curious and bad at proving. :(
Let f(n) be the minimum number of moves needed to reduce the number n to zero by repeated subtraction of one of its digits.
Let D(n) be the set of digits of a number n. We have the recurrence f(0) = 0,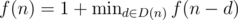 .
.
I will prove to you by induction that f(n) is monotonically increasing, which means that subtracting more is always better, which implies that the greedy approach is correct.
Claim: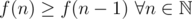
Base case: Obviously f(1) = 1 ≥ 0 = f(0), so the claim holds for n = 1
Inductive step: Let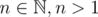 and
and 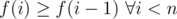 (so f is monotone on the set {0, ..., n - 1}). Let k be the largest digit of n. By a simple case analysis, we can see that n - 1 has a digit l ≥ k - 1. Using the monotonicity of f, we conclude
(so f is monotone on the set {0, ..., n - 1}). Let k be the largest digit of n. By a simple case analysis, we can see that n - 1 has a digit l ≥ k - 1. Using the monotonicity of f, we conclude
In addition, we know that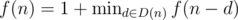 . Since k = max D(n) and because we assumed the monotonicity of f on the set {0, ..., n - 1}, we know that f(n) = 1 + f(n - k). Combined with the above inequality, this gives us f(n) ≥ f(n - 1).
. Since k = max D(n) and because we assumed the monotonicity of f on the set {0, ..., n - 1}, we know that f(n) = 1 + f(n - k). Combined with the above inequality, this gives us f(n) ≥ f(n - 1).
I hate this editorial, just like Meg.