


Cool and geometry in the same sentence? You must be mad! Well, no. I think there are lots of interesting geometry problems, only the average geometry problems people know happen to be implementation-heavy (and frankly not that cool) problems from ICPC contests. Here is a list to show off some actually cool problems. I included some problems to have some variation in the different kinds of problems on the list. The stars indicate approximate difficulty (not coolness per se).
- ⭐⭐⭐⭐⭐NCPC 2023 Interwined For this problem there is unfortunately a solution with a complicated datastructure (decremental convex hulls). The coolness is from the fact that it can be solved with just normal convex hull algorithms. Can you figure it out?
- ⭐⭐⭐★★ CEOI 2020 1402B - Roads. I remember this problem fondly as CEOI was my first big onsite competition, and this was my first encounter with geometry problems (I couldn't solve it, but I eventually upsolved it). It uses some classical ideas, but it is still quite nice, and the implementation isn't bad.
- ⭐⭐⭐★★ Balkan OI 2011 Time Is Money It does not immediately look like geometry. But it features a cool idea.
- ⭐⭐⭐★★ IOI 2006 joining points and Bubblecup generalized version. 1045E - Ancient civilizations Although it is not required, you can try for a $$$O(n \log(n))$$$ solution.
- ⭐⭐⭐★★ NEERC Southern Subregional 1070M - Algoland and Berland One of my favourite problems.
- ⭐⭐★★★ BAPC 2016 Airport Logistics When you have seen this type of problem many times, maybe it becomes less cool. But still cool when seen for the first time. This is one of the problems on the list which unfortunately needs a bit more implementation.
- ⭐⭐⭐★★ Project Euler Convex Holes
- ⭐⭐⭐⭐★ Yokohama Regional 2019-2020 Fun Regions Definitely not easy to implement, but the idea is great.
- ⭐⭐⭐★★ Cameramakers This is actually two problems in one. You definitely need to make some observations to get a good time complexity. But for seasoned geometry enjoyers, it may be too straightforward.
- ⭐★★★★ OCPC Delft Contest Curly Palindromes These last three problems are all my own problems. I think they are cool, but that's for you to decide.
- ⭐⭐⭐⭐★ ICPC Asia West 2023 Disk Tree
- ⭐⭐⭐⭐⭐ OCPC Delft Contest Beer Circuits
Do you agree with this list? Do you have more interesting geometry problems, let me know!






 Left halve solution for $$$n=15$$$.
Left halve solution for $$$n=15$$$. Solution for middle toy and $$$n=15$$$.
Solution for middle toy and $$$n=15$$$. Full solution for right halve for $$$n=15$$$.
Full solution for right halve for $$$n=15$$$.

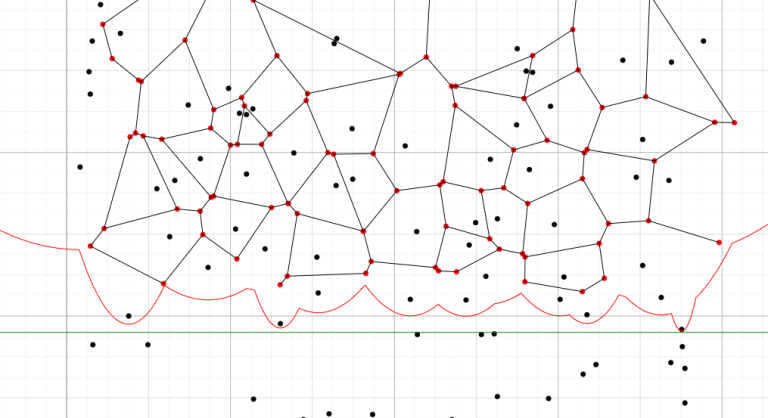 You can check it out here:
You can check it out here: 