This is the second part of Hunger Games Editorial, hope you'll enjoy it :) And again, thanks for stuff for awesome contest, congratz for survivors too!
UPD: Problems B, D, E, Q, T, W are now available, more soon :)
Editorial Hall of Fame:
Radewoosh .I. Chameleon2460 sepiosky adamant xuanquang1999 rnsiehemt Fcdkbear JoeyWheeler
Problem A: Good Numbers.
Tutorial by: xuanquang1999
Call LCM(i, j) the lowest common multiple of i and j.
First, we should analyse that if x is divisible by LCM(p^i, q^j), then x is divisible by p^i and q^j at the same time.
Call set s(i, j) the set of number x in range [l, r] that x is divisible by LCM(p^i, q^j). Call |s(i, j)| the size of s(i, j). We can find out that:
|s(i, j)| = |s(1, j)| - |s(1, i-1)| = r/LCM(p^i, q^j) - (l-1)/LCM(p^i, q^j)
Call set d(i, j) the set of number x in range [l, r] that x is divisible by LCM(p^i, q^j) and doesn't belong to any set d(ii, jj) (i <= ii, j <= jj, i != ii or j != jj and LCM(p^ii, q^jj) <= r). Call |d(i, j)| the size of d(i, j).
Our answer is sum of |d(i, j)| with i > j and LCM(p^i, q^j) <= r.
We also find out that |d(i, j)| = |s(i, j)| — sum of |d(ii, jj)| (i <= ii, j <= jj, i != ii or j != jj and LCM(p^ii, q^jj) <= r). So we can use recursion with memorize to this.
Our biggest problem is now checking for overflow (since LCM(p^i, q^j) can exceed int64). I found a pretty easy way to do this in Pascal:
function CheckOverflow(m, n: int64): boolean;
const e = 0.000001;
oo = round(1e18)+1;
var tmp, tmpm, tmpn, tmpu, tmpr: double;
begin
tmpm:=m; tmpn:=n; tmpu:=GCD(m, n);
tmp:=tmpm/tmpu*tmpn;
tmpr:=oo;
exit(tmp-e < tmpr);
end;
I wonder if there is a way to do this in C++ (without bignum)
kpw29's update: Let's check if p*q = ret gives overflow. We can check if ret divides q and ret / q = p.
Complexity of whole solution: O((log l)^2 * (log r)^2 * (log l + log r))
Code; http://ideone.com/R1AgnQ
Problem B: Hamro and array
Tutorial by : xuanquang1999
We first calculate array d with d[i] = a[1] - a[2] + a[3] - a[4] + ... + a[i - 1] * ( - 1)(i + 1) in O(n) (if i is odd, d[i] = d[i - 1] + a[i], else d[i] = d[i - 1] - a[i]). Then, for each query, if l is odd then ans = d[r] - d[l - 1], else ans = -(d[r] - d[l - 1]).
Complexity: O(n + q).
His code: http://ideone.com/kMalCH
Problem C:
Problem D: Hamro and Tools
Tutorial by : xuanquang1999
We can solve this problem by using Disjoint — Set Union (DSU). Beside the array pset[i] = current toolset of i, we'll need another array contain with contain[i] = the toolset that is put in box i. If no toolset is in box i, contain[i] = 0. For each query that come, if box t is empty, then we'll put the toolset from box s to box t (contain[t] = contain[s] and contain[s] = 0). Otherwise, we'll "unionSet" the toolset in box s with the toolset in box t (unionSet(contain[s], contain[t]) and contain[s] = 0).
Finally, we can find where each tool is by the help of another array box, with box[i] = current box of toolset i. Finding array box is easy with help from array contain. The answer for each tool i is box[findSet(i)].
Complexity: O(n).
Code: http://ideone.com/Te3wS9
Problem E: LCM Query
Tutorial by: Fcdkbear
Our solution consists of 2 parts: preprocessing and answering the queries in O(1) time.
So, in preprocessing part we are calculating the answers for all possible inputs.
How to do that? Let's iterate through all possible left borders of the segments. Note, that moving the right border of the segment do not decrease the LCM (LCM increases or stays the same). How many times will LCM increase in case our left border is fixed? Not many. Theoretically, every power of prime, that is less than or equal to 60 may increase our LCM, and that's it.
So for each left border let's precalculate the nearest occurrence of each power of each prime number. After that we'll have an information in the following form: if the left border of the segment is i, and the right border is between j and k, inclusive, LCM is equal to value. So, for each segment with length between j - i + 1 and k - i + 1 answer is not bigger than value. We may handle such types of requests using segment tree with range modification. In a node we will keep two numbers — double value of the LCM (actually, it's logarithm: note that log(a * b) = log(a) + log(b), so instead of multiplying we may just add the logarithms of our powers of primes) and the corresponding value modulo 1000000007.
After performing all the queries to segment tree we may run something like DFS on the segment tree and collect the answers for all possible inputs.
The overall complexity is O(n * log(n) * M), where M is a number of prime powers that are less than or equal to 60
Code: http://pastebin.com/7zcYTced
Problem F: Forfeit
Tutorial by: sepiosky
First we make an array F[] for each edge , for an edge like e if after deleting it we have two components C1 and C2 , then f[e] = |C1| * |C2| , It's easy to undrestand that if we increase weight of edge e by 1 the total sum of distances will increase by F[e].
Now we consider Sum as minimum total sum of distances , from where Min(Sum) = (N - 1)2 We can be sure that for 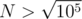 answer is 0 .
answer is 0 .
Now we can solve the problem with DP Where DP[E][S]=number of ways we can weight tree with sum S using first E edges.Note that first we subtract Sum from K and we use dp for collecting K - Sum
DP[E][S] = DP[E - 1][S - (L[E] * F[E])] + DP[E - 1][S - ((L[E] + 1) * F[E])] + ... + DP[E - 1][S - (R[E] * F[E]]
This DP is O(K * N2) but we can reduce it to O(K * N) (where N < 400 )
Source code: http://ideone.com/WOZfbg
Problem G: Hamro and Izocup
Tutorial by: sepiosky
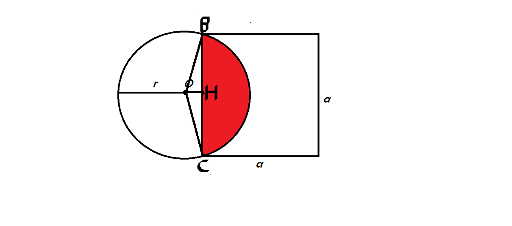
let S1 be the area of SECTOR BOC and S2 be area of TRIANGLE BOC  Answer = S1 - S2
Answer = S1 - S2
We can calculate OH using pythagorean theorem and length's of OB & HB( = α / 2) . so we can calculate area of triangle BOC .
for calculating the area of sector BOC first we should find 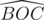 . We name as
. We name as 
in triangle BOH according to Law of sines : 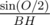 =
= 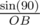 sin(O / 2) =
sin(O / 2) = 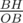 = 2 *
= 2 * 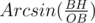
So area of sector BOC = 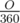 * π R2
* π R2
Now we have S1 & S2 So we have answer !
Source code: http://ideone.com/Zkvh6p
Problem H: Hamro and circles
This problem is basically the same as G. First, imagine that second circle is a square and solve G. Then, swap the circles, solve G again and add results.
Source code: http://pastebin.com/ZvJJcAKP
Problem I:
Problem J:
Problem K: Pepsi Cola <3
There are at least 2 different solutions for this problem, I'll try to explain them.
Chameleon2460's solution:
Let's define A as log of the biggest value in sequence T. By the problem constraints, A ≤ 17. I'll describe an O(3^A) solution, which will pass if implemented without additional log factor.
We'll try to find for all possible values of OR how many subsequences have that OR. (Taking the result is pretty easy then).
Define X contains Y iff (XORY = X). Notice, that OR X might be created only from values, which X contain.
We'll write subset DP in a quite standard way. For all values of X, we'll first assign dp[X] = 2L, where L is number of values, which X contain. (L can be computed the same time we write DP, just for all subsets of active bits in X, we'll add L[x] += L[subset]). Then, we will just subtract all values, because not all the subsets have OR equal to X. But we'll have this computed before entering X, so we can remove them without any additional effort.
Source code: http://pastebin.com/R6B2a41u
My old code, which is O(3^A * A), and gets TLE, but it's quite easier to understand: http://pastebin.com/7GNLJQ7E
JoeyWheeler's solution:
We consider a number to be the sum of some powers of two. (X = 2i + 2j + 2k + ...).
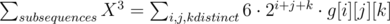 + similar terms for 22 * i + j and 23 * i.
+ similar terms for 22 * i + j and 23 * i.
Where g[i][j][k] = the number of subsequences with bits i, j and k set. We can use the Mobius DP similar to that described in this solution: http://www.usaco.org/current/data/sol_skyscraper.html to calculate f[i] = # of elements in the input array which are "supersets" of i in O(nlgn). Then, to calculate g[i][j][k], we can calculate how many elements of the array contain bit i but not j,k or bit i,k but not j etc (call these types of requirements classes) through inclusion exclusion with f[] in O(3 * 23 * 23). Then by iterating over subsets of the classes to be included in our subsequence and doing some simple math we can determine g[i][j][k] in O(223 * 23 * 23). The overall complexity is thus O($n lg n + log^3 n) See code for details.
Source code: http://pastebin.com/Hphc3k2y
Problem L:
Problem M: Guni!
Tutorial by: sepiosky
We can solve this problem using 2 segment trees. In first tree we keep array a and after processing each query of type 1 on it we add score of gi to second tree and for queries of type 2 we process this query on second tree and add result to it.
In first tree we keep negative of array a and for queries of type 1 we apply RMQ on it for finding minimum element in the gi's interval , its obvious that absolute value of minimum element in that interval is maximum element in gi , cuz we kepp negative of ai's . also only information needed from gi's are their maximum element( their score ) , so after getting answer of queries of type 1 from first tree we only add max element of gi( that is negative also ) to the second tree .
for queries of type 2 we use RMQ again this time on second tree and now we have answer for query . answer of this query is needed information for this Guni!(gi) so we add this number to second tree again .
In the end the answer is sum of all elements in second tree (scores of Gunis).
Code: http://ideone.com/n00BPJ
Problem N:
Problem O:
Problem P:
Problem Q: Mina :X
We can preprocess answers for each set size with the following DP: dp[0] = dp[1] = 0
dp[i] = min(max(dp[j] + 1, dp[i — j] + 2) for each 1 ≤ j < i.
Also, we should find what j gives optimal answer, we'll need it later.
Therefore, when we'll get a set S of size i, we'll already know what is correct answer for it.
When we know which j gives optimal answer, we can just query first j elements from our set and query them.
If the answer is "Yes", we should take those elements (and extract every other from S). Else, we should extract those j elements.
Solution: http://pastebin.com/cQ9vFkPc
According to sepiosky this may be done with Fibonacci search. His code: http://ideone.com/3dTmfO
Problem R:
Problem S:
Problem T: The ranking
rnsiehemt's explanation:
Consider the simplified case where we know that, for some interval, every competitor is either before the interval (say there are S of these competitors), after the interval, or somewhere inside the interval with uniform probability over the whole interval (say there are K of these). Then if this arrangement happens, each of the K competitors then has a chance to come each of S + 1th, S + 2th, ..., S + Kth.
Note also that if we consider all endpoints together and then take the intervals between consecutive endpoints: then for each interval, every competitor will either not cover that interval at all, or will completely cover that interval (and thus if they are in it, they will have a uniform probability of being anywhere in that interval). Also, there are O(N) of these intervals.
This gives us the simple algorithm: for each interval (O(N)), for each competitor i, (O(N)), calculate dp[S][K] = the probability of S other competitors appearing before this interval and K other competitors appearing inside this interval (which we can do in O(N3) with DP). However, this is overall O(N5) which is too slow. So we need to try and calculate "dp[S][K] for all competitors except i", for every i. One idea is to calculate dp[S][K] for all competitors, and then "subtract" each competitor with some maths. Overall this would be O(N4). Theoretically this is possible but in practice it is too inaccurate.
Instead we can calculate this with divide and conquer (overall O({N4}lgN), or buckets . For example, for divide and conquer we can calculate f(l, r) = the dp[S][K] for all competitors outside of the range [l, r), and then recurse on f(l, mid) and f(mid, r).
Problem U:
Problem V:
Problem W: Palindrome query
Consider strings S and S', to make implementation easier. We'll use hashing to comparing their substrings. We'll store their values in a Fenwick or Segment Tree. Suppose we change position x. (Do not forget to remove previous value!) Then, instead of p1[x] * pot[x] we'll have p2[x] * pot[x] at this place. We add this value to our data structure, and we're done.
For each query we'll use binary search to answer it, as when there's palindrome of length K, we're sure there are palindromes of length K-2, K-4, ....
Source code: http://pastebin.com/gn4wNe6a
Source code by adamant : http://ideone.com/8kLke7
Problem X:
I'll try to write all solutions as soon as possible :)













{kind=link}