


Editorial was created by Errichto, but he said that he has enough contribution, so I'm posting it for you. ;)
1 673A - Bear and Game
(invented by GlebsHP — thanks!)
You are supposed to implement what is described in the statement. When you read numbers ti, check if two consecutive numbers differ by more than 15 (i.e. ti - ti - 1 > 15). If yes then you should print ti - 1 + 15. You can assume that t0 = 0 and then you don't have to care about some corner case at the beginning. Also, you can assume that tn + 1 = 91 or tn + 1 = 90 (both should work — do you see why?). If your program haven't found two consecutive numbers different by more than 15 then print 90. If you still have problems to solve this problem then check codes of other participants.
2 673B - Problems for Round
(invented by Errichto)
Some prefix of problems must belong to one division, and the remaining suffix must belong to the other division. Thus, we can say that we should choose the place (between two numbers) where we split problems. Each pair ai, bi (let's say that ai < bi) means that the splitting place must be between ai and bi. In other words, it must be on the right from ai and on the left from bi.
For each pair if ai > bi then we swap these two numbers. Now, the splitting place must be on the right from a1, a2, ..., am, so it must be on the right from A = max(a1, a2, ..., am). In linear time you can calculate A, and similarly calculate B = min(b1, ..., bm). Then, the answer is B - A. It may turn out that A > B though but we don't want to print a negative answer. So, we should print max(0, B - A).
3 673C - Bear and Colors
(invented by Errichto)
We are going to iterate over all intervals. Let's first fix the left end of the interval and denote it by i. Now, we iterate over the right end j. When we go from j to j + 1 then we get one extra ball with color cj + 1. In one global array cnt[n] we can keep the number of occurrences of each color (we can clear the array for each new i). We should increase by one cnt[cj + 1] and then check whether cj + 1 becomes a new dominant color. But how to do it?
Additionally, let's keep one variable best with the current dominant color. When we go to j + 1 then we should whether cnt[cj + 1] > cnt[best] or (cnt[cj + 1] = = cnt[best] and cj + 1 < best). The second condition checks which color has smaller index (in case of a tie). And we must increase answer[best] by one then because we know that best is dominant for the current interval. At the end, print values answer[1], answer[2], ..., answer[n].
4 673D - Bear and Two Paths
(invented by Errichto)
There is no solution if n = 4 or k ≤ n. But for n ≥ 5 and k ≥ n + 1 you can construct the following graph:
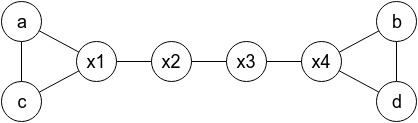
Here, cities (x1, x2, ..., xn - 4) denote other cities in any order you choose (cities different than a, b, c, d). You should print (a, c, x1, x2, ..., xn - 4, d, b) in the first line, and (c, a, x1, x2, ..., xn - 4, b, d) in the second line.
Two not very hard challenges for you. Are you able to prove that the answer doesn't exist for k = n? Can you solve the problem if the four given cities don't have to be distinct but it's guaranteed that a ≠ b and c ≠ d?
5 673E - Levels and Regions
(invented by Radewoosh)
When we repeat something and each time we have probability p to succeed then the expected number or tries is  , till we succeed. How to calculate the expected time for one region [low, high]? For each i in some moment we will try to beat this level and then there will be S = tlow + tlow + 1 + ... + ti tokens in the bag, including ti tokens allowing us to beat this new level. The probability to succeed is
, till we succeed. How to calculate the expected time for one region [low, high]? For each i in some moment we will try to beat this level and then there will be S = tlow + tlow + 1 + ... + ti tokens in the bag, including ti tokens allowing us to beat this new level. The probability to succeed is 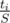 , so the expected time is
, so the expected time is 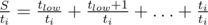 . So, in total we should sum up values
. So, in total we should sum up values 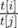 for i < j. Ok, we managed to understand the actual problem. You can now stop and try to find a slow solution in O(n2·k). Hint: use the dynamic programming.
for i < j. Ok, we managed to understand the actual problem. You can now stop and try to find a slow solution in O(n2·k). Hint: use the dynamic programming.
- Let dp[i][j] denote the optimal result for prefix of i levels, if we divide them into j regions.
- Let pre[i] denote the result for region containing levels 1, 2, ..., i (think how to calculate it easily with one loop).
- Let sum[i] denote the sum of tj for all 1 ≤ j ≤ i.
- Let rev[i] denote the sum of
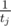 for all 1 ≤ j ≤ i.
for all 1 ≤ j ≤ i.
Now let's write formula for dp[i][j], as the minimum over l denoting the end of the previous region:
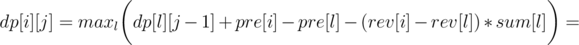
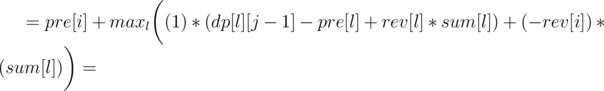
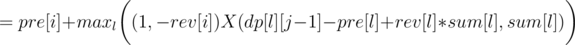
So we can use convex hull trick to calculate it in O(n·k). You should also get AC with a bit slower divide&conquer trick, if it's implemented carefully.
6 673F - Bearish Fanpages
(invented by Radewoosh)
Let's say that every company has one parent (a company it follows). Also, every copmany has some (maybe empty) set of children. It's crucial that sets of children are disjoint.
For each company let's keep (and always update) one value, equal to the sum of:
- the income from its own fanpage
- the income from its children's fanpages
It turns out that after each query only the above sum changes only for a few values. If a starts to follows b then you should care about a, b, par[a], par[b], par[par[a]]. And maybe par[par[b]] and par[par[par[a]]] if you want to be sure. You can stop reading now for a moment and analyze that indeed other companies will keep the same sum, described above.
Ok, but so far we don't count the income coming from parent's fanpage. But, for each company we can store all its children in one set. All children have the same "income from parent's fanpage" because they have the same parent. So, in set you can keep children sorted by the sum described above. Then, we should always puts the extreme elements from sets in one global set. In the global set you care about the total income, equal to the sum described above and this new "income from parent". Check codes for details. The complexity should be 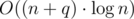 , with big constant factor.
, with big constant factor.
7 674E - Bear and Destroying Subtrees
(invented by Errichto)
Let dp[v][h] denote the probability that subtree v (if attacked now) would have height at most h. The first observation is that we don't care about big h because it's very unlikely that a path with e.g. 100 edges will survive. Let's later talk about choosing h and now let's say that it's enough to consider h up to 60.
When we should answer a query for subtree v then we should sum up h·(dp[v][h] - dp[v][h - 1]) to get the answer. The other query is harder.
Let's say that a new vertex is attached to vertex v. Then, among dp[v][0], dp[v][1], dp[v][2], ... only dp[v][0] changes (other values stay the same). Also, one value dp[par[v]][1] changes, and so does dp[par[par[v]]][2] and so on. You should iterate over MAX_H vertices (each time going to parent) and update the corresponding value. TODO — puts here come formula for updating value.
The complexity is O(q·MAX_H). You may think that MAX_H = 30 is enough because 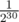 is small enough. Unfortunately, there exist malicious tests. Consider a tree with
is small enough. Unfortunately, there exist malicious tests. Consider a tree with 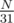 paths from root, each with length 31. Now, we talk about the probability of magnitude:
paths from root, each with length 31. Now, we talk about the probability of magnitude:
which is more than 10 - 6 for d = 30.
http://www.wolframalpha.com/input/?i=1+-+(1-(1%2F2)%5Ed)%5E(N%2Fd)+for+N+%3D+500000+and+d+%3D+30
8 674F - Bears and Juice
(invented by Radewoosh)
Let's start with O(q·p2) approach, with the dynamic programming. Let dp[days][beds] denote the maximum number of barrels to win if there are days days left and beds places to sleep left. Then:
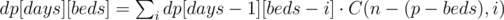
Here, i represents the number of bears who will go to sleep. If the same i bears drink from the same X barrels and this exact set of bears go to sleep then on the next day we only have X barrels to consider (wine is in one of them). And for X = dp[days - 1][beds - i] we will manage to find the wine then.
And how to compute the dp faster? Organizers have ugly solution with something similar to meet in the middle. We calculate dp for first q2 / 3 days and later we use multiply vectors by matrix, to get further answers faster. The complexity is equivalent to O(p·q) but only because roughly q = p3. We saw shortest codes though. How to do it guys?
You may wonder why there was 232 instead of 109 + 7. It was to fight with making the brute force faster. For 109 + 7 you could add sum + = dp[a][b]·dp[c][d] about 15 times (using unsigned long long's) and only then compute modulo. You would then get very fast solution.
9 674G - Choosing Ads
(invented by qwerty787788)
Let's first consider a solution processing query in O(n) time, but using O(1) extra memory. If p = 51%, it's a well known problem. We should store one element and some balance. When processing next element, if it's equal to our, we increase balance. If it's not equal, and balance is positive, we decrease it. If it is zero, we getting new element as stored, and setting balance to 1.
To generalize to case of elements, which are at least 100/k%, we will do next. Let's store k elements with balance for each. When getting a new element, if it's in set of our 5, we will add 1 to it's balance. If we have less, than 5 elements, just add new element with balance 1. Else, if there is element with balance 0, replace it by new element with balance one. Else, subtract 1 from each balance. The meaning of such balance becomes more mysterious, but it's not hard to check, that value is at least 100/k% of all elements, it's balance will be positive.
To generalize even more, we can join two of such balanced set. To do that, we sum balances of elements of all sets, than join sets to one, and then removing elements with smallest balance one, by one, untill there is k elements in set. To remove element, we should subtract it's balance from all other balances.
And now, we can merge this sets on segment, using segment tree. This solution will have complexity like n * log(n) * MERGE, where MERGE is time of merging two structures. Probably, when k is 5, k2 / 2 is fastest way. But the profit is we don't need complex structures to check which elements are really in top, so solution works much faster.

