На этот раз я решил попробовать писать разбор в спойлерах, как уже делал кое-кто из авторов. Буду рад вашим комментариям о том, стало ли лучше.
Задача A. Сдвиги
Темы: динамическое программирование.
Общий комментарий: это первая среди "сложных" задач контеста. В ней можно помочь хорошее знакомство со стандартными задачами на ДП, но довести решение до финального правильного вида все равно непросто.
Решение: пускай мы можем сдвигать не только вправо, но и влево.
Как решать такую задачу?Прежде всего заметим, что сделать сдвиг -- это то же самое, что переместить какой-то символ в другое место. Ясно, что никакой символ не надо двигать больше одного раза, поскольку вместо этого можно сразу поставить его на финальное место и не тратить действия. Кроме того, очевидно, что сдвиги не меняют количество вхождений каждого символа в строку, поэтому в обеих строках посимвольные вхождения должны совпадать.
Посмотрим теперь на символы исходной строки, которые не затронуты ни одним действием, а также на те позиции, где они в итоге окажутся в финальной строке.
Эти два множества ничего не напоминают?Относительный порядок символов должен совпадать в обоих множествах, поскольку мы не переставляем эти символы. Поэтому множества должны соответствовать общей подпоследовательности исходной и финальной строк. Если какое-то решение сделало k операций, то наша общая подпоследовательность будет иметь длину n - k.
По любому X можно построить решение...Более того, любую общую подпоследовательность длины k можно превратить в решение, которое совершает ровно n - k действий, просто переставив все нестационарные символы на их окончательные позиции.
А задача о нахождении оптимального X...Мы можем видеть, что минимальное количество действий равно в точности n - k, где k -- длина наибольшей общей подпоследовательности
Если это не очевидно...... стоит подумать о том, в каких случаях ответ может быть больше или меньше этого количества, и попытаться прийти к противоречию, обращаясь к предыдущим спойлерам.
По ссылке выше можно прочитать про алгоритм решения задачи НОП за время O(n2) при помощи ДП.
Нельзя же вообще все объяснить в спойлерах? Что меняется, если сдвигать можно только вправо?В целом, картина похожая...Ясно, что количество вхождений каждого символа все еще должно быть одним и тем же в обеих строках. Кроме того, никакой символ не имеет смысл трогать больше одного раза, а неподвижные символы все еще образуют общую подпоследовательность. Тем не менее, из второго примера ясно, что теперь ответ может быть больше, чем n - LCS(s, t) (здесь LCS(s, t) -- длина наибольшей общей подпоследовательности s и t).
Попробуем найти дополнительные условия...Посмотрим на неподвижный символ si и его финальное положение tj во второй строке. Относительно si мы можем только перемещать символы из правой части s в левую.
Из этого следует необходимое условие на пары символов...Выберем букву x и посчитаем количество ее вхождений справа от si и tj, обозначим эти количества A и B. Из рассуждения выше ясно, что должно выполняться A ≥ B. Если мы собираемся сопоставлять в общей подпоследовательности si и tj, то это условие должно выполняться для всех типов букв.
Достаточно ли этих условий?..Довольно логично попробовать написать решение с такой же динамикой, как для нахождения НОП, но с дополнительной проверкой на то, что пары соответствующих символов удовлетворяют условию выше. Однако, возникает вопрос: достаточно ли этих условий, чтобы оставить в рассмотрении только корректные решения (а именно, множества неподвижных символов, по которым можно построить подходящую последовательность операций)?
Сходу доказать или опровергнуть это может быть непросто. Это нормальная ситуация, в том числе для опытных участников.
Как бы поступил опытный участник?Пускай у вас есть правдоподобная идея, которую вы хотите проверить, но не можете доказать или опровергнуть теоретически. В такой ситуации хороший метод -- запустить стресс-тест: написать тупое медленное решение, в котором сложно ошибиться, и проверить, согласуются ли его ответы с гипотезой на большом количество случайных тестов. Если это так, то гипотеза с большой вероятностью верна, а если нет, то у вас на руках есть контрпример, а с ним бывает понятнее, что делать дальше.
Ну ладно, а можно ли доказать все-таки?Да!
Нам надо показать, что из общей подпоследовательности неподвижных символов длины k, удовлетворяющей дополнительным ограничениям (см. выше), можно получить ответ (корректную последовательность действий) длины n - k. Покажем для этого, что все остальные символы можно поставить на места. Очевидно, если неподвижных символов нет, то всех можно переставить как угодно, значит, все хорошо.
Посмотрим на неподвижный символ si и соответствующий символ tj второй строки, а также наборы символов A и B, которые стоят справа от si и tj соответственно. Из необходимого условия следует, что  в том смысле, что никакая буква не встречается в B чаще, чем в A. Поэтому мы можем получить B в финальной конфигурации, выбрав среди A нужные символы и расставив их в правильном порядке справа от si.
в том смысле, что никакая буква не встречается в B чаще, чем в A. Поэтому мы можем получить B в финальной конфигурации, выбрав среди A нужные символы и расставив их в правильном порядке справа от si.
Что делать с остальными буквами A' = A\ B? Мы должны переместить каждую из них на финальную позицию за один шаг. Вмес того, чтобы решать этот вопрос сейчас, мы можем притвориться, что буквы si больше нет, и присоединить все буквы из A' к группе слева от si в надежде, что за оставшиеся шаги алгоритм разберется, что делать с этими буквами. Этот процесс можно продолжать, пока группы не кончатся.
Challenge (трудный/научная проблема):Решите задачу принципиально быстрее, чем O(n2), либо объясните, почему это, скорее всего, невозможно.
ПодсказкаЗадача тесно связана с задачей нахождения НОП. Что известно науке о сложности НОП? Как показать, что наша задача не проще, чем НОП?
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Задача B. Число в подарок
Темы: жадность.
Общий комментарий: задача на аккуратность. Требуется учесть много мелких деталей, но в остальном задача вполне решаемая.
Решение: Раз мы максимизируем число, важнее всего понять, насколько большую цифру можно поставить на первое место. Обозначим d первую цифру n.
Есть несколько случаев... - d > y
- d = y
- x < d < y
- d = x
- d < x
В некоторых из них легко получить сразу весь ответ...В случае 1 на место первой цифры можно поставить y, в случае 3 можно поставить x, а в случае 5 приходится сделать число короче на одну цифру (что в сущности то же самое, что поставить на первое место 0). Во всех этих случаях при поциферном сравнении ответ сразу становится меньше n, поэтому остальную часть можно просто максимизировать безо всяких ограничений, т.е., заполнить ее цифрами y.
А в остальных надо разбираться подробнее...Если d = x или d = y, то у нас есть шанс сделать первую цифру такой же, как в n. Тем не менее, нельзя сразу сказать, можно ли достроить ответ до числа, не превосходящего n, смотри, например, случай n = 20, x = 1, y = 2.
Что делать?Будем идти по цифрам n, пока не встретим цифру d', отличную от x и y, либо конец числа. Во втором случае ответ просто равен n.
В первом случае применим правило еще раз...Если d' > x, то мы можем продолжить число до конца (можно применить такое же правило, что и для постановки первой цифры). Если d' < x, то число достроить нельзя, значит, мы должны вернуться назад и уменьшить какие-то из более ранних цифр.
Какие именно?Мы можем только уменьшать y до x, поэтому надо найти самый правый y, сделать его x-ом, а потом максимизировать остаток числа (потому что к этому моменту мы уже поставили меньшую цифру, чем на том же месте в n).
Что, если не получается?Это значит, что n начинается с нескольких цифр x, а потом идет цифра меньше x. Получается, что ответа такой же длины не существует, поэтому надо искать среди чисел меньшей длины.
И какой тогда ответ?Это уже несложно самому понять (или посмотреть в спойлерах выше). Ну серьезно.
Итоговая сложность...Видно, что такое решение работает за O(n), потому что оно совершает не больше двух проходов вперед и одного прохода назад.
Все еще WA?Рекомендуется проверить следующее:
- Не может ли ваш ответ начинаться с нуля?
- Не может ли ваш ответ быть нулем?
- Корректно ли обрабатывается случай n = 10100 000?
- Тогда не знаю. Надо постресстестить!
Challenge (легкий):Сколько (по модулю 109 + 7) существует положительных чисел, состоящих из x и y и не превосходящих n? Решите за время O(n).
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Задача C. Рекуррентный генератор
Темы: хэширование/строковые алгоритмы.
Общий комментарий: задача несложная, но некоторые решения удачнее других в плане времени работы, памяти и простоты реализации, поэтому продуманный выбор решения мог сэкономить много времени на остальные задачи.
Решение: Для начала поймем, почему последовательность Фибоначчи, определенная в условии, не является 1-рекуррентной.
Предположим обратное...Тогда найдется функция f(x1), такая что f(ai) = ai + 1 для всех индексов i < n. Но для такой функции одновременно должно выполняться f(1) = 1 и f(1) = 2, противоречие!
Можно ли сделать из этого критерий для k = 1?Предположим, что после каждого вхождения числа x всегда идет одно и то же число y (либо конец последовательности). Это означает, что функция, заданная соотношениями f(ai) = ai + 1, определена непротиворечиво, значит, последовательность является 1-рекуррентной.
Можно ли обобщить этот критерий для любого k?Мы видимо, что k-рекуррентность связана с тем, есть ли противоречия в том, какие числа следуют за участками последовательности длины k: если можно найти два одинаковых участка длины k, после которых идут разные числа, то последовательность не является k-рекуррентной. В противном случае, мы можем определить непротиворечивую функцию f(ai - 1, ..., ai - k) = ai.
Как проверить, есть ли противоречивые участки длины k?Можно просто выписать все участки длины k вместе со следующими элементами и поискать конфликты. Это займет O(n3) времени, если делать просто попарные сравнения,
либо... времени, если отсортировать все участки и делать проверки только для соседних,
времени, если отсортировать все участки и делать проверки только для соседних,
Наконец...Осталось сделать бинарный поиск по k, итоговая сложность 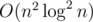 или
или  .
.
Challenge (легкий/упражнение):Решите задачу:
- за время при помощи простых строковых алгоритмов (без хэшей!)
- за время O(n2) при помощи простых строковых алгоритмов (без хэшей!)
- за время
 при помощи строковых алгоритмов посложнее (все еще без хэшей!)
при помощи строковых алгоритмов посложнее (все еще без хэшей!)
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Задача D. Торговля
Темы: жадность, сортировка, реализация.
Общий комментарий: идея решения сама по себе не является очевидной, но кроме этого требуется большая аккуратность, чтобы избежать проблем с точностью, количеством запросов и всем таким.
Решение:
Можем ли мы решить задачу, если нам сразу известны стоимости d с точки зрения продавца?Пускай мы хотим заплатить сколько-то товаров таким образом, чтобы с точки зрения продавца они стоили какое-то маленькое число ε.
Как это сделать оптимально?Пускай мы хотим тратить только i-ый товар, тогда нам надо заплатить ε / di единиц, так что с нашей точки зрения стоимость будет равна ε·ci / di. Поэтому лучше всего тратить товар с наименьшим значением ci / di.
Как же выглядит решение?Разобьем x на маленькие кусочки размера ε и будем выкупать их по очереди. Согласно предыдущему рассуждению, в оптимальном решении мы должны постепенно тратить товары по мере возрастания их значения ci / di до тех пор, пока продавцу не хватит. Товары с одинаковым ci / di можно тратить в любом порядке.
Что делать, если значения d неизвестны?Мы видели, что важнее всего знать порядок сортировки товаров по возрастанию ci / di.
Что мы должны уметь, чтобы сортировать объекты?Важно заметить, что нам не надо знать конкретные значения ci / di, если мы научимся их корректно сравнивать для разных товаров. Останется всего лишь применить любимый алгоритм сортировки.
Как это сделать?Возможности наши запросов довольно ограничены: ответ -- это просто "да" или "нет", и нам надо научиться сравнивать отношения при помощи таких запросов. Делать это можно так: сперва найдем конфигурацию чисел ai, при которой с хорошей точностью достигается равенство 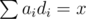 , после чего будем делать небольшие изменения относительно этой конфигурации таким образом, чтобы равновесие зависело от результатов сравнения ci / di.
, после чего будем делать небольшие изменения относительно этой конфигурации таким образом, чтобы равновесие зависело от результатов сравнения ci / di.
Как найти равновесие?Будем считать все ai равными, и запустим бинарный поиск по их общему значению. После 40-50 итераций мы получим равновесное значение практически на пределе точности типа double (ниже чуть подробнее про проблемы с точностью).
Как делать сравнения?Выберем маленькое положительное число Δ. Чтобы сравнить отношения для i-го и j-го товара, сделаем следующие изменения относительно равновесной конфигурации: ai -= Δ·cj, aj += Δ·ci. Значение суммы 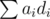 изменится на величину
изменится на величину 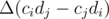 , которая имеет такой же знак, что и разность ci / di - cj / dj. Теперь для сравнения надо сделать всего один запрос (если только мы не стремимся корректно находить равные отношения, ниже чуть подробнее про это).
, которая имеет такой же знак, что и разность ci / di - cj / dj. Теперь для сравнения надо сделать всего один запрос (если только мы не стремимся корректно находить равные отношения, ниже чуть подробнее про это).
Отсортировали товары, что дальше?Мы знаем порядок, в котором надо тратить товары. Теперь сделаем бинпоиск по тому, какой суммарный объем товаров мы заплатим. Из жадных соображений следует, что любой объем надо тратить, начиная с товаров с маленьким ci / di.
Это решение делает порядка 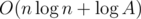 запросов, при данных ограничениях на практике получается около 450.
запросов, при данных ограничениях на практике получается около 450.
На этом описание решения по большому счету заканчивается.
Однако, остаются мелкие детали...Как выбрать Δ?Единственная проблема с выбором Δ в том, что если выбрать слишком большое значение, при сравнении отношений измененные значения ai могут выходить за допустимые границы [0, 1]. Мы знаем, что в равновесной конфигурации значение всех ai будет как минимум на 0.1 отстоять от границ. Чтобы изменения не могли вывести нас за границы, достаточно потребовать неравенство Δ max(ci) ≤ 0.1, поэтому подойдет Δ ≤ 10 - 5.
Отметим, что при сравнении неравных отношений значение будет изменяться как минимум на 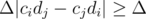 от x, поэтому в таких случаях проблемы с точностью нам не страшны.
от x, поэтому в таких случаях проблемы с точностью нам не страшны.
Мое решение опирается на корректное сравнение равных отношений, что мне делать?Печальная ситуация. Такое требование может возникать, например, если сортировать отношения при помощи std::sort с кастомным компаратором, который сам делает необходимые запросы по ходу дела. std::sort делает дополнительные запросы к компаратору, чтобы проверить его корректность, например, транзитивность. Это не только тратит запросы, но и может привести к ошибке выполнения, если компаратор плохо сравнивает равные объекты: на равных объектах компаратор всегда должен возвращать false.
Наше сравнение для равных дробей работает плохо. Дело в следующем: в теории при сравнении значение 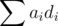 не должно поменяться совсем, а на самом деле из-за погрешностей вещественных чисел оно меняется на очень маленькую величину. В результате, значение может непредсказуемо плясать вокруг x, и сравнения будут возвращать случайные результаты (напомним, что в запросе
не должно поменяться совсем, а на самом деле из-за погрешностей вещественных чисел оно меняется на очень маленькую величину. В результате, значение может непредсказуемо плясать вокруг x, и сравнения будут возвращать случайные результаты (напомним, что в запросе ? никакие погрешности не учитываются!).
Одно из возможых решений: сделать значение чуть-чуть больше, чем x, чтобы не пострадать от случайных микроошибок.
Также отметим, что многим алгоритмам сортировки (например, слиянием или вставками) вообще не важно, как сравнивать равные элементы, поэтому там такой проблемы нет.
Challenge (средний):Можете ли вы решить задачу, сделав 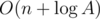 запросов, где A -- максимальное значение ci, di?
запросов, где A -- максимальное значение ci, di?
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Задача E. Прогулка по Манхэттену
Темы: математика, кратчайшие пути в графе.
Общий комментарий: даже если не получается придумать простого математического решения, всегда можно воспользоваться стандартными графовыми алгоритмами. Изи.
Решение:
Это же стандартная задача?Построим граф, в котором вершины соответствуют состояниям (x, y, d), где (x, y) -- текущая точка, а d -- направление последнего шага (на самом деле, достаточно помнить, был ли последний шаг по горизонтали или вертикали). Если предположить, что не надо выходить за пределы квадрата с координатами не больше 100 по модулю, в нашем графе < 200 000 вершин и < 400 000 ребер, поэтому теперь можно просто найти кратчайший путь при помощи обхода в ширину.
Это слишком муторно, можно ли проще?Обозначим модули разностей по координатам x и y за Δx и Δy соответственно.
Ответ равен...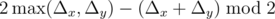 .
.
Почему??Без ограничения общности предположим, что Δx ≥ Δy. Сперва заметим, что нам обязательно надо сделать не меньше шагов. Действительно, горизонтальных шагов надо сделать не меньше Δx. Поскольку шаги чередуются, то вертикальных шагов придется сделать не меньше Δx - 1. Наконец, заметим, что четность точки (цвет точки в шахматной раскраске) меняется после каждого шага, поэтому нижнее ограничение на количество вертикальных шагов равно Δx - 1, если начало и конец пути имеют разную четность (т.е. тогда и только тогда, когда Δx + Δy нечетно), и Δx, если одинаковую. В сумме получаем ровно искомую оценку.
Наконец заметим, что такого количество шагов достаточно. Для этого сперва придем в точку (Δy, Δy) за 2Δy шагов, повторяя последовательность шагов RU (вправо-вверх), а затем будем повторять последовательность RURD (вправо-вверх-вправо-вниз), пока не придем на финиш. Можно проверить, что мы придем к цели ровно за заявленное число шагов.
Challenge (вроде несложно):Пускай мы ходим по k-мерному Манхэттену, то есть, наше положение задается k целыми координатами, мы можем менять одну из координат на 1 за один шаг, а также не можем два раза подряд менять одну и ту же координату. Найти длину кратчайшего пути из одной точки в другую за время 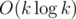 .
.
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Задача F. Игра на дереве
Темы: игры, графы, математика.
Общий комментарий: сперва эта задача казалась мне простой, и я ожидал по ней больше правильных решений. Каждая идея по отдельности достаточно несложная, и кода в итоге совсем чуть-чуть. Оказалось, что распутать задачу целиком под силу немногим. Какие у вас впечатления от задачи? =)
Решение:
Шаг 1Для Красного игрока выполняется равенство kR = vR - eR, где vR -- количество красных вершин, а eR -- количество ребер, у которых оба конца красные.
Шаг 2Красный хочет максимизировать kR - kB, что равняется (vR - eR) - (vB - eB) = (vR - vB) - (eR - eB). Заметим, что vR и vB не зависят от действий игроков, и 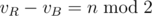 . Это означает, что для оптимальной игры можно с тем же успехом минимизировать eR - eB.
. Это означает, что для оптимальной игры можно с тем же успехом минимизировать eR - eB.
Шаг 3Пусть на каждом ребре у нас есть счетчик. Когда Красный ходит в вершину, увеличим значения всех счетчиков ребер, исходящих из вершины, на 1. Когда ходит Синий, уменьшим все соседние счетчики на 1.
Чему равна сумма значений всех счетчиков в конце игры?С одной стороны, ясно, что это равно (сумма степеней красных вершин) — (сумма степеней синих вершин).
С другой стороны, на красном ребре (у которого оба конца красные) написано +2, а на синем -2. На нейтральном ребре написано 0. Поэтому сумма счетчиков равна 2(eR - eB).
Финиш?Из этого рассуждения следует, что ход в вершину степени d фактически уменьшает наши очки на d / 2.
Теперь ясно, что оптимальная стратегия такая: всегда ходить в вершину наименьшей степени, независимо от хода игры.
Это легко записать в виде решения, которое работает за O(n).
Challenge (ну такое):Как играть в эту игру на унициклическом графе (связном графе с n вершинами и n ребрами)? Что можно сказать про сложность этой задачи для произвольного графа?
Решение?Решения к челленджам появятся позже, пока что удачи в самостоятельном решении. =)
Буду рад услышать любые ваши мнения в комментариях. Спасибо за участие!





