


Hello Codeforces Community, I am glad to share HackerRank World Codesprint 8 starting on 17th December 2016. The contest duration is 24 * 2 =48 hours.
The winners of the contest will win up to 2000USD cash prizes. Also, there are opportunities to win T-shirts and Amazon Gift cards.
The contest will be rated. If two person gets the same score, the person who reached the score first will be ranked higher.
There will be 7 normal algorithmic challenges and 1 approximate challenge in this contest. I highly recommend you to read all the problems. Most of the problems contain cool figures :).
The problems are prepared by svanidz1, malcolm, darkshadows, kevinsogo, robinyu, torquecode and me.
I would like to give special thanks to Wild_Hamster who worked really hard to finalize the problems and testing the data. Also thanks to wanbo as always for testing.
Update: Score of the problems are 10-20-30-50-60-75-85-100. The last problem will have binary scoring.
Update: The contest has ended, editorials are now available. Congrats to the winners!
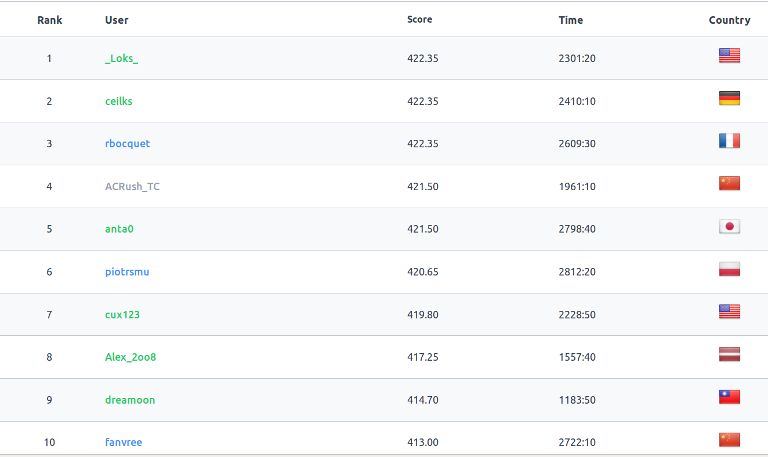
Ratings will be updated soon. Don't forget to give your feedback!
Happy Coding!







Just curious, did you guys hire Wild_Hamster for testing after reading his blog (http://codeforces.com/blog/entry/48380) on how to pass inadequate solutions in hr?
Smart move, isn't it? ;)
I wouldn't use the word 'hire', but he is a nice guy who is willing to help us to improve. I hope no one will be able to hack solutions this time.
One more thing, why don't you guys change the design of the tshirt? i'm bored of getting the same tshirt with "world champion" written in front of it again and again. i hope the tshirt i will get for this codesprint will be different and unique.
Well, you always can send them to mee_)
Is the "approximate challenge" for the purpose of tie-break? It seems that "approximate challenge" of HackerRank is usually too weak to tie-break.
Yes.
Usually hackerRank contests don't have approximate challenges, we had an approximate challenge in the last university codesprint after a really long time and yes that challenge wasn't quite strong enough to break tie. I believe this time the approximate challenge is harder and better and will be good enough to break tie.
We will know after the contest ends :).
I can't connect to hackerrank with Chrome, it gives the following error: NET::ERR_CERTIFICATE_TRANSPARENCY_REQUIRED.
It says that hackerrank uses HSTS (whatever that is).
It works fine on Firefox though.
Is it just me or others are having the same problem?
Are codesprints going to contain an approximate challenge from now on?
We will try to.
There's easier to code but much harder to prove and understand
Unable to parse markup [type=CF_TEX]
solution for Tree Coordinates problem.Let's root the tree at some vertex and compute the depth of each vertex. We will be interested in the deepest point, i.e. with maximal value of
Unable to parse markup [type=CF_TEX]
. Suppose its index is h.Distance between two vertices (not points) xi and xj equals to
Unable to parse markup [type=CF_TEX]
. I proved that if points i and j are the furthest, thenUnable to parse markup [type=CF_TEX]
lies on the path fromUnable to parse markup [type=CF_TEX]
to the root (similarly for y's). Let's denoteUnable to parse markup [type=CF_TEX]
,Unable to parse markup [type=CF_TEX]
. Then, there are two cases:Unable to parse markup [type=CF_TEX]
is an ancestor ofUnable to parse markup [type=CF_TEX]
andUnable to parse markup [type=CF_TEX]
is an ancestor ofUnable to parse markup [type=CF_TEX]
(remember they all lie on a path fromUnable to parse markup [type=CF_TEX]
orUnable to parse markup [type=CF_TEX]
to the root).This leads to the following solution.
Unable to parse markup [type=CF_TEX]
andUnable to parse markup [type=CF_TEX]
.Unable to parse markup [type=CF_TEX]
to the root.Unable to parse markup [type=CF_TEX]
and, in case of a tie, in increasing value ofUnable to parse markup [type=CF_TEX]
.Basically, I process points as the
Unable to parse markup [type=CF_TEX]
goes up the path fromUnable to parse markup [type=CF_TEX]
to the root, and I proved that I only need to check those points processed before that haveUnable to parse markup [type=CF_TEX]
aboveUnable to parse markup [type=CF_TEX]
. Point processing consists of just 3 operations:Unable to parse markup [type=CF_TEX]
, to account for the first case.Unable to parse markup [type=CF_TEX]
(right border included).Unable to parse markup [type=CF_TEX]
withUnable to parse markup [type=CF_TEX]
.My code (not the cleanest): https://www.hackerrank.com/contests/world-codesprint-8/challenges/tree-coordinates/submissions/code/8180255
From article, this problem becomes to "exercise 2.3". Embed tree metric into
Unable to parse markup [type=CF_TEX]
.And the solution to this exercise is discussed in this paper (see Theorem 3.3, page 5 of the pdf).
P.S.: Al.Cash's code seems to be inaccessible, even for people who have solved the problem (at least I can't see it).
Edit: Thanks, Shafaet =)
Try again, you can access now.
My solution :
Unable to parse markup [type=CF_TEX]
.Unable to parse markup [type=CF_TEX]
;I could not prove or disprove this solution. My code.
I tried to cut off many random solutions, such as: taking 200-1000 points with max(depthx+depthy), min(depthx+depthy), max(depthx), max(depthy), min(depthx), min(depthy), trying to reroot tree 200-1000 times, doing O(1) LCA. And still a couple of random solutions passed.
Can somebody prove his random solution?
There was also a slower, simpler (at least for me) solution with sqrt-decomposition in
Unable to parse markup [type=CF_TEX]
.Root the tree and for each subtree S calculate the answer using only points i with xi in S.
When merging two subtrees, for each point with an x-value in the smaller (fewer points with x-values in it, not fewer vertices) subtree we compare it all the points having an x-value in the larger subtree S2.
If there are more than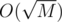 such points, we first precalculate for each vertex v the distance of the furthest point with
such points, we first precalculate for each vertex v the distance of the furthest point with
Unable to parse markup [type=CF_TEX]
toUnable to parse markup [type=CF_TEX]
. This can be done in O(N) by some dfs. For each point i withUnable to parse markup [type=CF_TEX]
the distance to the furthest point j withUnable to parse markup [type=CF_TEX]
is the precalculated value for yj +Unable to parse markup [type=CF_TEX]
.At each merge there are at most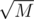 points and maybe a single precalculated value to check each point with. Each points gets merged at most
points and maybe a single precalculated value to check each point with. Each points gets merged at most
Unable to parse markup [type=CF_TEX]
times. There are at mostUnable to parse markup [type=CF_TEX]
time. From this the above time bound follows.Can somebody describe his 90+% solution on approx problem? I wasted pretty much time on 84%(71.4 points)
How do we approach approximation problems? I always find it more difficult to get to these. I tried using A-star search, greedy, etc. I know with practice I will improve, but are there some resources I should be looking at the start.
It seems to me the model solution for Tree Coordinates presented in the editorial is wrong.
Here is a simple case where it gives the result
0instead of the correct answer4:The idea is that after having divided in the x-direction, we cannot just go ahead and start dividing the current subtree B in the y-direction, because the y-coordinates may all lie outside of B. Note that dividing first by y and then by x doesn't work in this case either.
The closest "correct" solution to the presented one would be to start from the whole tree T again for the second divide-and-conquer, but this should lead to a runtime of at least Ω(n2).
It might be possible to fix this by alternating between dividing in x- and y-direction and pruning when there are no points left in the current region (which feels quite similar to working with a quadtree), but I couldn't quite get that to work during the contest.
I guess, it's just bug in tester's solution. Main author's solution is here
Honestly I don't understand editorial solution, so I can't judge it.
Edit: wanbo's code also gives 4 for your testcase.
Yeah, I didn't entirely understand the explanation either, so my comment above mostly refers to my understanding of that explanation based on the provided code.
I'm gonna have a look at the author's solution then, perhaps that will clear things up for me.
Given that you're part of the organizers, do you think it is possible to post the other solution in the editorial so as to not confuse other readers?
I have removed the buggy code for now and added author's code. That code was written by editorialist, not tester or author.