


Hello Codeforces!
On Jul/14/2018 17:35 (Moscow time) Educational Codeforces Round 47 will start.
Series of Educational Rounds continue being held as Harbour.Space University initiative! You can read the details about the cooperation between Harbour.Space University and Codeforces in the blog post.
This round will be rated for the participants with rating lower than 2100. It will be held on extented ACM ICPC rules. After the end of the contest you will have 12 hours to hack any solution you want. You will have access to copy any solution and test it locally.
You will be given 7 problems and 2 hours to solve them.
The problems were invented and prepared by Ivan BledDest Androsov, Vladimir vovuh Petrov, Maksim Neon Mescheryakov, Aslan Timurovich Tamaev and me.
Good luck to all participants!
I also have a message from our partner, Harbour.Space University:
Hi Codeforces!
We want to remind everyone that the Hello Barcelona Programming Bootcamp is right around the corner, and we’d love to see you there!
Our boot camp will once again feature the all-time greats Mike MikeMirzayanov Mirzayanov, Andrey andrewzta Stankevich, Michael Endagorion Tikhomirov, Gleb GlebsHP Evstropov, Artem VArtem Vasilyev, Ivan ifsmirnov Smirnov and other world renowned Russian coaches to train the participants.
We would also like to extend a welcome to some of the newest teams to join us from Colorado School of Mines, University of British Columbia and Reykjavík University.
Be sure to register before August 1st so everyone has time to get visas if needed, and of course for the Early Bird Discount of 15% or the Loyalty Discount* of 20% off registration for the boot camp!
*The loyalty discount is offered to universities and individual participants that took part in Hello Barcelona Bootcamps and Moscow Workshops ICPC.
Learn more about Barcelona ICPC Bootcamp
You can ask any questions by email: [email protected]
Congratulations to the winners:
| Rank | Competitor | Problems Solved | Penalty |
|---|---|---|---|
| 1 | tribute_to_Ukraine_2022 | 7 | 159 |
| 2 | hohomu | 7 | 274 |
| 3 | guille | 7 | 338 |
| 4 | radoslav11 | 7 | 580 |
| 5 | waynetuinfor | 6 | 148 |
Congratulations to the best hackers:
| Rank | Competitor | Hack Count |
|---|---|---|
| 1 | halyavin | 689:-132 |
| 2 | 2014CAIS01 | 91:-13 |
| 3 | Al-Merreikh | 20:-1 |
| 4 | Ali_Pi | 16:-3 |
| 5 | gsparken | 15:-3 |
And finally people who were the first to solve each problem:
| Problem | Competitor | Penalty |
|---|---|---|
| A | Harpae | 0:01 |
| B | eddy1021 | 0:05 |
| C | tribute_to_Ukraine_2022 | 0:09 |
| D | BARPITF | 0:09 |
| E | Roundgod | 0:19 |
| F | radoslav11 | 0:15 |
| G | chemthan | 0:28 |






Would you consider making the hacking time 6 hours instead of 12 hours as it has been discussed before.
No weak pretest plz.
Can the contest be rescheduled as it clashes with the FIFA WC 3rd Place match tomorrow? Probably delay it by 1 or 1.5 hours?
Will provide a nice breathing space after the AtCoder Grand Contest that ends 5 minutes before this contest too
Ya Plz
How to solve div 2a?
We got a guy from future here, peeps.
It is not so easy, that we can solve it without a statement
sorry, I thought I was writing in the previous contest :(
however you got +30 upvotes :D
just do whatever you want. you can use some convex hull tricks, or persistent data structures, just do it :)
... dp+convexHull+persistent seg tree = dexHustent tree :)
The penalty for WA is 20 or 10?
Should be 20. I believe, this change will only affect Div.3 rounds.
UPD: I'm wrong, check later comments.
What about this comment?
Okay, sorry for misleading information then, I wasn't notified of it. Then it's 10 minutes.
I can watch Hataraku Saibou right after this contest! It's great!
My hero academia too
Now I can enjoy it.
Educational WorldCupForces Round!
?detaR ti sI
?detaR tI sI
Minimize hacking phase to 6 hours
awoo What will be the penalty in this round, 10 or 20 ?
It is 10,read this comments.
its reated? lol OALollolol xDXDxD :)))))))))))))))))))
btw :: How to solve div2 D,E?
in this contest yes .
Not sure if this comment meant to gain upvote like before or to gain more downvote so he could be on the last page of contribution rank.
Edit : he's already on the last page !
Maybe he is trying to be on the last place.
Why Codeforces (Contest writer) doesn't mention directly that this Educational Round will be rated for Div 3 participants also? As they mention "Rated for Div 2" directly.
¯\_(ツ)_/¯
div3 is a subset of div2 maybe that's why who knows
IMHO whether the round is rated and for which divisions should be an attribute of the contest like "Writers", "Start" and "Length", and not be part of the "Name" of the contest.
Using the same logic, Why he didn't mention that it is unrated for Div. 1 participants also? Maybe because they are smart enough to know the contest is unrated for them.
Penalty Time??
10
When you want to take part badly but your laptop's display broke 3 hours before the contest :(
problem E is too poisonous,i mod 10^9+7 instead of 998244353.
Well, it's even somewhat bold in the statement. And also repeated a couple of times. Should be noticeable.
But why though? Why did you choose this mod?
Well, there are two reasons.
The first is that nowadays problemsetters tend to choose this modulo for all problems (not only ones requiring modular FFT) so that people don't see this modulo and instantly react like "Ok, we need a convolution here".
And the second reason is that, when I started preparing this problem, I didn't understand that there is a simple math solution, and tried to solve it with online modular FFT instead xD
Makes sense now. Thanks =D
Hey why wouldn't you use mod 10^9+7 for fft as well?
OEIS is your friend for Problem E : link
Edit: this sequence gives the number of occurences of each element in reverse order (last one occurs 1, second to last 3 times etc.)
aah shit
But 40343744 ??? I think that problem E require another sequence 40349064
UPD: sorry, my wrong, I just forgot about modulo
Not sure why this is being downvoted, I found the exact same sequence online during the contest.
A fairly common problem solving technique: 1) write naive solution 2) find pattern (possibly look online) 3) hard code in formula
What is the 5th test case for problem C?
and someone also give me some hard test case for this problem.
It's a greedy problem.
This one is for B.
Sorry, Updated!!
In your code, "sum" overflows for very large N.
JovanB
now i have also tried by long long int instead of double.but i am getting WA at 5th test case :(
N should be long long, because even if sum is
long long, (N*(N+1))/2 isint, and can go up to 10^10, which is bigger than the limit forintMake n also long long int. You have
ll sum = (n*(n+1))/2but n is an int — the overflow will happen first so sum will end up with a weird value for large enough n.Small datatypes may overflow, so long double should fix the problem.
For problem C, Why my solution failed? http://codeforces.com/contest/1009/submission/40348123
Edit: Failed on pretest 5
n is an int up to 10^5 and you are doing n*(n+1) when you calculate beech
One obvious reason is overflow. You have
beech = n*(n-1), but n is an int. See what happens when n = 100000 or n = 99999.I've been really enjoying this series of contests, but out of curiosity, wouldn't it be better advertising to create Div 1 rounds? I'd love to go to the camp, but considering how far away I am from making ACM worlds, it's hard to justify the expense.
I think Div 1 participants are more likely to take the plunge and spend 1000+$ and a week away from school.
A very good contest with a very smooth difficulty curve, not an easy thing to make. Good job to the writers
When can we submit?
Taking strong tests to another level :P
There are actually 130 tests in this problem.
It was originally used in Saratov SU trainings a few days ago, and there was a man who managed to receive RE 130.
How can one get RE at 131 if there are only 130 test cases? Am I missing something?
Successful hacks are added to the testcases for systests, so there are 130 pretests + any successful hacks.
Oh so thats why. I didn't knew that before. Thank you
Yeah, strong tests in tree problem without test "1-2-3-...-N". This is Educational round.
Can somebody explain why my code for E got TLE in Test Case 9 (though I think it's O(n)) and for C got WA in test 5 ?
For C: check overflow. You're multiplying two ints and storing the result in a long long. Overflow happens before the storing does.
Thanks for finding the error in both the codes :)
For E: You're reading 10^6 numbers using cin. Speed it up with
ios::sync_with_stdio(0)andcin.tie(0)or use printf/scanf.Could someone please explain why this code doesn't work for problem D? http://codeforces.com/contest/1009/submission/40345268
Here's the approach I used —
Since the graph has to be connected, the M has to be >= N-1 otherwise impossible. I then proceeded to take the sum of all phi(n) from 1 to N (phi(n) being the Euler Totient Function). If this sum >= M, I then use sieve to create the graph.
I started matching 1 to all nodes from 2 to N, thus making the graph connected. This meant I had M — N + 1 edges left to add. I used sieve to find relatively prime numbers and as soon as the count of edges hit 0, I returned 0 and proceeded to print the graph.
I would really appreciate a counter-test so that I know where I was going wrong. Thank you!
I tried 20 45 and the last edge you print is 4 10. GCD( 4 , 10 ) = 2. Hope this helps
Looks like you're just counting multiples of a number as non-coprime with it, which is only true for primes — not composite numbers. Try
6 11. You print4 6.For every x, sieve will only delete every multiple of x (not relatively prime of x). So your sieve will delete every multiple of x, add every y where y is not multiple of x, and readd every multiple of x
Got it, thank you Diegogrc, IceKnight1093 and Firastic! I'll upsolve this now.
Educational.....
I don't know why I was getting TLE on test case 6 on problem C here. The time complexity looks linear to me. Maybe the logic for the problem I am using is wrong. But stil I shouldn't get TLE as I guess the complexity of the code I am using is O(n). Can someone explain both the logic and the problem with my code?
I'm not sure but i think your arrays are too small (10000 instead of 100000).
Damn! I also figured that out like a minute ago and yeah the array size is small. I just missed it literally by a '0'. It's frustrating. But the contest was really good. Hats off to problem writers!.
So if there is a segmentation fault then TLE is given as error on codeforces right?
It means it failed to meet the segmentation fault. Instead, it probably got into an infinite loop by changing the value of nearby variables (i.e., 'i' or 'm'), therefore getting TLE from it.
Great difficulty balance of the problems, shoutout to the writers!
Oh.... I fall a trap in Problem B and got confused a lot on that problem
How to solve B?
1011201120112 is 0111111120202
greedy doesn't work? I am getting the same soln but still dreaded test case 4 fails
It works perfectly. my submission : http://codeforces.com/contest/1009/submission/40342688
Greedy doesn't mean that you put all small values before bigger ones, we have to do so but under some constraints.
Explanation of my solution: Maintain a reverse_ans string, initially null.
Start from last, if there is a '0' or a '1' increase the counter for '0' or '1. If there is a '2', we know that we can't shift any '0' beyond this point, so first put all found zeroes to reverse_ans and reset its counter and now put '2' in reverse_ans.
Important step (greedy but different to what is done above)
At the iteration is over, first put all '1' to reverse_ans and then all zeroes.
reverse the reverse_ans and print it.
what I thought was get all 21 and convert to 12 and 10 to 01. The only exception to this rule was 201 which becomes 120. run this till I have no 201, 21 or 10 in my string. this soln fails and I want to know why or what test case am I missing.
2121111111111111111111111111111(up to 10^5 length)
If you look for all occurrences of "12" or "21", you should get a TLE.
For WA, 0000212000001 Answer : 0000112200000
Put all '1' s just before first "2". 012012 becomes 011202 , whereas your code gives 012012
so, count '2' and '0' from first '2' and put them back of the string with same order. fill the rest of numbers 1
count 1 in string then count 0 before any 2 comes then print 0 as per count then print all 1, then just print 0/2 as they come in string. for eg. 101201120 becomes 011112020
Maintain the order of 0's ans 2's. Take all 1's and put them just before 1st occurence of 2.
1:59:59 :D
Amazing
But what's more Amazing is that you just submit the first 3 problems in 3 minutes
Cool problems, thanks to round authors.
why is this recurrence wrong for E?
where dp[0] = 0 and a[i] is the prefix sum. I can use fenwick tree for prefix sum but why logic error? I am choosing the rightmost stop and then I calculate difficulty for remaining sub problem.
This recurrence is wrong because it doesn't take probabilities into account.
For example, suppose you are analyzing 4-th kilometer and trying to find a closest rest stop before it. The probability that it will be on position 3 is 0.5, the probability that it is on coordinate 2 is 0.25, and so on. So we can't just sum all these dp values up, we need some coefficients.
How to solve E ?
Note: I didn't actually solve E but I got the problem right after contest ended...
The answer is: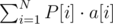
where
P[i] = 2N - i - 1·(N - i + 2) for i = 1...N-1
P[N] = 1 (technically same as above but 2 - 1 is fractional)
mod MOD at each step of course
I used brute force to find array for first 10 numbers and entered the list into OEIS
edit: off by 1
Why this got MLE 40349306 and this didn't 40349677? Very strange, how much memory deque uses...
stl deque many times proves inefficient for many problems in time n memory usage
I think .clear() doesn't free memory. Could you try delete operation?
NEVEEER USE DEQUE If you don't like to get MLE :(
SAAAME
I use them. Never experienced ML till now because of them.
problem B was very good!
With a greedy taste.
Huh. For problem E if you use cin, you get TLE on test case 7, but if you use scanf you get AC :O
try using
ios::sync_with_stdio(false);cin.tie(NULL);. It can boost up speed of cin/cout to that of scanf/printf. See 40351502oh i used scanf during contest
In D problem even the custom invocation is showing possible but the test case 18 is giving Impossibe for my code Please check out this solution http://codeforces.com/contest/1009/submission/40348587
Same Code gets submitted after ccontest http://codeforces.com/contest/1009/submission/40350442
OOps figured out n*(n-1) crossed int limit
Looks like your solutions just overflows in m>(n*(n-1)/2).
The problem with the first one was overflow: you were comparing m with (n*(n-1))/2 where n was an integer. If n is large enough the product will overflow and become negative. Second submission doesn't have that comparison so it passed.
For C i used double instead of long double to store (double)total_sum / n. Can it cause wrong ans in main test due to precision issue?
double ans = (double)sum/n
ans might overflow, you should've typecasted sum to long double!
sum will not overflow, it's about O(n3·maxn) which is smaller than 1018
I meant after typecasting long long int to double it might overflow!
Updated!
No, it should be okay.
Today's D was easier (till now I think) compared to the last contests. And I wasted my time to look for corner cases and if any case that will lead me to TLE. Could not get time to solve E (which had a nice pattern). Anyway, educational contests are fun than the usual ones. Though I messed up today's one badly. Did not think today's one was going to be simpler than the past.
...
We can always bring any 1 to the beginning of the string, since we can swap 1 with any other digit.
because there are sufficiently many 1s in the string, the 0 and 2s have become invisible after the moves.
guys someone sent me a message which asks me to help him solve C and that he will help me solve B. Fortunately I was not noticed with that message during the contest and as you guys can see I ended up without solving B and after the contest i solved it by myself. My question is: how can I report him for cheating?
In the test 11 of problem C:
Checker comment ok found '621354311313.3487500', expected '621354311564.2170400', error '0.0000000'
Why is the output correct?
Its relative error is smaller than 10 - 6
In terms of relative error, it's correct.
If it is stated that "Your answer is considered correct if its absolute or relative error doesn't exceed 10 - x", then checker considers the minimum of absolute and relative errors.
how to solve D?
Run two loops(1 to n and from i+1 to n)and calculate gcd (i,j)if it is 1 then print as m can be atmost 100000 so the both loop terminates after m iteration. And if n>m-1 you have to print impossible as the graph then can't remain connected
"as m can be atmost 100000 so the both loop terminates after m iteration" can you please prove it or can give some intuition behind it?
It's not true, using this method at least. Since every pair is being checked, even those with
gcd(i, j) != 1will be checked, leading to more than m iterations in total.for(int i=1;i<=100000 && al.size()<=100000;i++){ for (int j = i+1; j <=100000 && al.size()<=100000; j++) { if(gcd(i,j)==1){ al.add(new pair(i,j)); } x++; } }x came out to be 100002
The worst case for this will actually be with a somewhat smaller n but large m. Maybe something like n = 10000, m = 100000 will work, I haven't tested exactly. If n is very large, most of the edges will come very quickly since you get n-1 from 1, and 2 and 3 are both prime. Only when you need i to go fairly high (and be composite) do you start getting less edges added per iteration.
Edit: n = 10000 and m = 100000 gives x = 161528. This algorithm is probably going to be fast enough, but certainly not going to stop in exactly m steps.
The ratio of number of relatively prime pairs (i, j) that 1 ≤ i ≤ j ≤ n and all pairs is:
Probability of coprimality. We can generate random pairs using uniform distribution and choose only $ m $. In C++ I used
std::uniform_int_distribution,std::mt19937and my hastable and got accepted.Given n, the number of possible edges is basically all those (unordered) pairs (x, y) such that x, y ≤ n and gcd(x, y) = 1 and x ≠ y. This number is simply φ(1) + φ(2) + ... + φ(n) - 1, where φ is the totient function. (subtracting 1 since we can't have the pair (1, 1).
This gives us 2 edge cases: if m is greater than this number or m < n-1 it's not possible to create such a graph — either it won't be connected or there won't be enough edges.
In every other case, it's possible. Connect 1 to every other node first to connect the graph. Then, for each pair (i, j) such that gcd(i, j) = 1, i ≤ j, 1 < i, j ≤ min(n, 600) you have one edge. 600 because φ(1) + ... + φ(600) > 100000 so you're guaranteed to have enough edges with just that.
nice observation! and thanks a lot.
In D, the most important task was to check possible or not because other than that, we just need to output co-primes together.
In order to check co-primes of available, you just need to implement Euler's totient function. Thus in O(n), we can check possibility or not.
We could have stored this value in a vector to check is total count is greater than required and n-1 as well. But that can bring TLE for large cases.
Submission
How to solve F? Can it be done in O(NlogN) or O(N)?
https://codeforces.com/blog/entry/44351
Do dfs on a tree, and for every node x, you can find the array d(x). You can make it in O(nlogn) if you merge there arrays carefully. MLE solution: 40349306 Correct: 40349677
This technique is called dsu on tree?
Idk, I just call it merging vectors on trees.
In fact, we can even make it O(n) if we merge the structures for subtrees not according to their sizes, but according to their heights (merge lower subtree to higher).
Can you explain this, how to merge in O(n)?
It seems that 40349677 (if I understood the code correctly) actually uses this method of merging in O(n). You just need to do the same things you do in standard small-to-large approach, and it "magically" works in O(n) time if the size of subtree's structure is proportional to its height (and merging two structures can be done in time proportional to the size of a smaller structure).
A more detailed explanation, proof and my implementation will be in editorial.
Okay , thanks!
Can someone confirm if everything is okay with Problem-D ? My solution SEEMS to be working well on my system but failed pretest number 3.
Turns out my solution was wrong. Sorry.
Obviously http://codeforces.com/contest/1009/submission/40351881 submission will eventually fail, because of taking limit small, but I can't for the life of me figure out why it is getting wrong answer on test case 4. Could someone please help me out? Every single thing besides considering number of nodes(which should in no way be a cause of getting wa at this test case) seems fine in here to me and yet I'm getting WA on F, test case 4
Can anyone tell why my solution got hacked after passing the preliminary tests here
Maybe using long double instead double will help?
long double where?
cout<<fixed<<setprecision(8)<<(long double)su/n;
I tried, still, it got hacked :(. My solution here. Any idea what the failed test case might be?
The answer can be up to 5.0005 * 10^12 * 10^5 = 5.0005 * 10^17 — when n, m = 10^5, all x = 1000 and all d = 1000. So 8 digits isn't enough.
Please try this test: 3 1 0 -1 The answer must be -0.6666667
if d<0 we need to take into consideration 2 cases: n is odd and n is even. 40355675
It's working now and I got it. I just considered the case of n is odd. Thanks a lot!.
You're welcome! Good luck!
Maybe it's one of the simplest solutions on problem E.
In Problem D . I tried to use totient function to find out if it's possible or impossible to form the graph. And then just printed out the no whose __gcd(i,j) == 1. Is this approach correct although I'm getting wrong answers . Am I missing some vertices? http://codeforces.com/contest/1009/submission/40351068
The graph should be connected.So your solution got wrong when m<n-1
So what's the correct procedure to print?
You are supposed to print "Impossible" when m<n-1,since in that case you can't connect all n vertices within m edges.
Yes, 3 things-
1) Your graph is not necessarily connected so include all the edges of type 1 i ,i>=2
2) Check condition for p>=m and m>=n-1 in your if part
3) Run loop only till 600 because summation of euler function is >100000 for 600 i.e upto 600 you will get enough edges to make the graph connected satisfying condition for m edges.
Can't be more accurate
Recurrence for generating coprime pairs for D.
https://en.wikipedia.org/wiki/Coprime_integers#Generating_all_coprime_pairs
This works, but wouldn't there be any overlapping cases ?
It says that "This scheme is exhaustive and non-redundant with no invalid members" so it shouldn't produce overlaps.
Sequence A001792 in OEIS for task E.
Was the evaluator for problem C correct? My solution ( 40334143 ) got hacked after the contest, and after checking the test cases that were ok i found something weird. In Test 11 my answer was off by more than 100 and the evaluator returned ok. Is this a problem with the evaluator? I believe this shouldn't happen
http://mathworld.wolfram.com/RelativeError.html
In terms of relative error, it's correct
None of this matters much, but I'm curious how the standings and problems solved vary during the hacking phase. I understand that as solutions get hacked, people lose credit for problems, so their ranking would go down. That means that if you don't have a solution hacked, your rank tends to get better. And, the dashboard generally shows fewer of each problem solved, as solutions get hacked.
But, I've also seen my ranking get worse (without having a solution hacked) at some points during the hacking phase — generally just a little bit — maybe 10 places. And, I occasionally see the number of solved problems go up during the hacking phase. I imagine the number solved might include people submitting them afterward, but presumably that doesn't affect ranking. Any ideas how this is happening?
Virtual participators.
Uncheck the checkbox stating "show unofficial" on top right corner of Standings page.
In today's contest I saw many solution of C got hacked,after the hacking phase could anyone please state in what case many of the contestant's solution went wrong.
most of them have kept of datatype of sum variable as double which will overflow for large values x and d when summed across m queries.So use long double instead!!
I also have used double, but when I tried to hack my solution by putting maximum constraints, even then it passed the test.
I used long long. Still no hack. And a lot of used long long. long long sum and then cout << fixed << setprecision (10) << (double) sum / n * 1.0 << endl;
This seems to work fine. So, I am curious about what the hack case is.
I see that Test #11 says "ok found '621354311564.2196000', expected '621354311564.2170400', error '0.0000000'". Umm why is this? Edit: Sorry for the mistake, I just found out that it is the relative error.
Yeah I just checked the sizes of double and long double.Double is of 8 bytes while long double is 16 bytes on C++ 14. I kind of had a misconception both were of 8 bytes,but now I see those were for older versions.
Can somebody please explain how double in C++ works? I was sure it takes 8 bytes and has diapason from -9 * 10^18 to 9 * 10^18. Where am I wrong?
Double (and other data types for real numbers) can have precision errors. The numbers in computers are represented by bits. Int takes 4 bytes, long depends on the OS, long long 8, float 4, double 8 and so on.. Check this link for more information: https://www.tutorialspoint.com/cplusplus/cpp_data_types.htm
I think you know that int data type is limited to values between -2^31 to (2^31 — 1). In that range, there are exactly 2^32 different numbers which is the maximum we can represent with 32 bits. Float is a data type for real numbers and its size is 4 bytes (same as int). That means, we have 32 bits and we can represent at most 2^32 different values. We know that float can be used to represent some real numbers which we cannot represent with int. That means for one real number, we have used one of those 2^32 combinations for its representation. Then if we try to represent every possible integer in the int range, there will be some numbers whose int and float values will be different. Thus those floats will be rounded to another value.
Real numbers can be represented with the IEEE 754 standard. You can Google it for more information if you want to see how it works. That representation, allows us to represent very high numbers (I think it’s something like 10^308). But, we can only represent 2^size different numbers where size is the size of the data type in bits.
I explained you about float, and I hope you understand what’s the problem with those representations. It’s similar for double, its length is just 8 bytes.
Try the following program. An example of an integer that gets rounded when represented by double.
And since some integer numbers get rounded by real data types, it’s also true that some real numbers will get rounded as we don’t have infinite precision. And if your program rounds the number many times, you may get wrong answer verdict for some example.
I fixed your program: http://codeforces.com/contest/1009/submission/40360084 My advice is, try to use as less real data types as possible. In line #13, you were using double to calculate a number which can be as big as 10^10 (= (10^5)^2) and as I explained you, it’s a bad idea.
Thank you very much!
halyavin is doing wonders!!! What a hacker!!
True hacker
That's system testing in disguise
I think that for C the judge should be made with integers, because it can be not fair sometimes.
After how many hours does system testing start for educational CF rounds?
Where's editorial?
Can anyone please tell me what is wrong with this 40362288 ?
40362440 This one gives me AC. The Only difference is I have declared the variable sum as long long is this submission and as double in the previous submission ? How can this give me wrong answer ?
Can someone help me with problem A? My solution passed all test cases yesterday but now it shows wrong output on test case 9, but on my machine the output matches correctly with the answer.40325412
Before accessing any kind of container (queue,stack,set etc.) You should always check either it empty or not.
Use this as condition
if(!wallet.empty() && arr[i]<=wallet.front())how did halyavin hack 600+ in 12 hours manually?
You still think he did it manually
I don't understand why my solution got Hacked
doublehas problems with precision. For example, calculating1e18 - 1 - 1e18sequentially results in0.0instead of-1.0.View testprovides the generator of the hack. It constructs a general input hacking all solutions that accumulate the answer withdouble.thanks!!! and can you suggest how can I tackle this problem
The answer before being divided by
nwon't exceed mn2(d + x) about1e18. Thusint64(longin Java?) is efficient to store the answer. Then you can output the answer divided bynindouble.thanks!!! finally got Accepted
Can anyone tell if my submission for problem C is correct or not? Whether it will pass the tests used in the hacking. http://codeforces.com/contest/1009/submission/40330305
I used double in the end for division and before that used long long to store the sum. Can’t double store till 10^18?
I didn't understand problem F.
How depth array of vertex 1 of example 1 look like?
I thought it would be {0, 1, 1, 1, 0, ...} and the dominant index would be 1 but 0.
Is a vertex an ancestor of itself?
It depends on how we define i guess. I think it should have been specified to consider a vertex as ancestor of itself,but by looking at the sample tests you can get it.
Yes, vertex is an ancestor of itself in this problem.
The array is actually [1, 1, 1, 1, 0, 0, ...]. The first element is 1 because (by definition) there is one vertex so that the simple path between 1 and y contains 0 edges. Path with 0 edges means its the vertex itself, so it's 1. And yes, the vertex is its ancestor. The same is true any other vertex, so the array always starts from 1.
Thank you all for kind reply.
During the contest, I was searching the definition of ancestor over and over... to understand example
Great contest
can you tell me why my submission 40370101 is WA at test 39?PLz PLz PLz
precision error,use long double or change approach slightly and use int64
Can someone list what should I study to solve C, E and F. Thank you.
Where's editorial ?? Also what's the approach of E? Or should we just use OEIS to find the pattern?
The editorials for educational rounds are always really late. Probably will take a few more hours/days. :-(
E is just dynamic programming. Find a recursion for dp[i] = sum of all path between 0 and i. Hint: think about the location of the last rest site.
Editorial will be published in 4-5 hours, sorry for the delay.
How to solve F with dsu?
Auto comment: topic has been updated by awoo (previous revision, new revision, compare).
Can someone explain how halyavin's hack for C causes double to not be precise enough?
I construct a test where answer is close to zero but intermediate results are as large as possible. This causes catastrophic cancellation and loss of relative precision.
So the green hacks team won again?