


I hope you've enjoyed the problems! Please ask your questions and report flaws in the comments.
Problem A
First insight is that two spells are always enough. Why? Let's freeze all leftbound penguins at point 10 - 9 and all rightbound penguins at point 109.
So the only problem is to determine when only one spell is enough. If that holds, there should exist a point which all penguins will cross at some moment. Let's put this point at x + ~--- rightmost point among penguins' coordinates which run to the right. Now all rightbound penguins will cross this point. If there is a leftbound penguin which doesn't cross x + then its coordinate x - must be less than x + . But in this case there are two penguins running away from each other~--- clearly one spell will not suffice.
So, the easiest and most effective solution is to find x + ~--- the location of rightmost rightbound penguin, and x - ~--- the location of leftmost leftbound penguin, and check if x - < x + . If that holds, the answer is 2, otherwise it's 1. This can be easily done in O(n). Other approaches include checking for all pairs of penguins if they run away from each other in O(n2), or more effeciently using sorts in  .
.
Problem B
Let's divide all configurations by leftmost turned-on bulb. Suppose the leftmost turned-in bulb is i-th. If i + k - 1 ≤ n, then the bulbs i + 1, \ldots i + k - 1 can be turned on or off in any combinations, so the number of such configurations is 2k - 1. If i + k - 1 > n, then the ``free'' bulbs are limited by the end of the line, and the number of configurations is 2n - i. There is also one combination when all bulbs are off.
These quantities can be summed up in if one uses binary modulo exponentation of 2, or in O(n) if the powers of 2 are precomputed with DP. It can also be shown (by summing the geometric progression which you can try to do yourself) that the answer is always equal to (n - k + 2)2k - 1, this number can be computed in 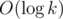 .
.
Problem C
Let's come up with a straightforward solution first. We will just simulate the battles and keep the current value of M. How many iterations we will have to make? And more importantly, how can we tell if the answer is - 1 or we just didn't do enough battles yet?
To answer that, let's keep track of values of M before all battles with the first opponent. If some value of M repeats twice, then the whole process is looped and the answer is - 1. On the other hand, if M > A (the largest possible value of ai, that is, 106) we will surely win all battles. So the maximal number of iterations is n(A + 1) (since no value of M ≤ A can repeat twice).
This is still too much for straightforward simulation (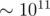 battles). How can we optimize that? Let us find f(M)~--- the number of first lost battle for each value of M at the start that does not exceed A. This can be done in O(A) for all M's at the same time using the fact that f(M) does not decrease. Indeed, suppose we know f(M) and also g(M)~--- our power before battling the last opponent. If the starting power were M + 1, at this point our power would be g(M) + 1. If this is still not enough to win opponent f(M), then f(M + 1) = f(M), g(M + 1) = g(M) + 1. Otherwise, we proceed to following opponents updating f(M + 1) and g(M + 1) accordingly until we lose or win them all. Notice that the total number of increases of f(M) is at exactly n, thus the complexity is O(n).
battles). How can we optimize that? Let us find f(M)~--- the number of first lost battle for each value of M at the start that does not exceed A. This can be done in O(A) for all M's at the same time using the fact that f(M) does not decrease. Indeed, suppose we know f(M) and also g(M)~--- our power before battling the last opponent. If the starting power were M + 1, at this point our power would be g(M) + 1. If this is still not enough to win opponent f(M), then f(M + 1) = f(M), g(M + 1) = g(M) + 1. Otherwise, we proceed to following opponents updating f(M + 1) and g(M + 1) accordingly until we lose or win them all. Notice that the total number of increases of f(M) is at exactly n, thus the complexity is O(n).
Using values f(M) we can emulate the battles much more quickly: for given M find the first lost battle, add f(M) to the total number of battles, update M with max(0, g(M) - aM), proceed until we win everyone or M repeats. This optimization leads to O(n + A) solution.
There is another tempting idea for this problem which turns out to be wrong. If you have trouble with WA3, consider this case:
4 2
0 5 0
6 0 3
7 0 6
8 0 4
Problem D
Let's call a position x \emph{interesting} if color(x) ≠ color(x - 1). If we find two interesting positions x < y so that color(x) = ... = color(y - 1), then the answer is equal y - x.
How can we find a single interesting position? Suppose we have two arbitrary positions a < b and color(a) ≠ color(b). Then we can find an interesting position x with a < x ≤ b using binary search: let 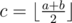 . If color(a) ≠ color(c) update a with c, otherwise update b with c. At some point b - a = 1 and we're done. Denote this resulting position as f(a, b).
. If color(a) ≠ color(c) update a with c, otherwise update b with c. At some point b - a = 1 and we're done. Denote this resulting position as f(a, b).
Okay, how to find two positions of different colors first? Let M be the maximal possible value of L. Consider a segment of length, say, 2M. The colors inside this segment have to be distributed \emph{almost evenly}, so after trying several random cells we will find two different colors with high probability.
There are several possible options what to do after we have obtained two interesting positions x and y. We can use the fact that either the segment x, \ldots, y - 1 is same-colored, or it has at least 1 / 3 of the cells with color! = color(x), so we can try random cells until we find z with color(z) ≠ color(x), and then we can shrink the segment to either x, f(x, z) or f(z, y), y, whichever's shorter. Length of the segment shrinks at least two times after each iteration (in fact, it shrinks even faster).
Another approach is to note that L divides y - x for all interesting positions x and y. Thus we can obtain several interesting positions f(a, b) for random values of a and b, and find G~--- GCD of their differences. Clearly, 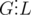 . It can also be shown that G = L with high probability is the number of positions is, say, at least 50; it is a bit harder to analyze though, but the general idea is that while it's hard to determine the exact distribution of f(a, b), it is \emph{not that bad}, so it is improbable for many values of f(a, b) to be, say, multiples of 2L apart.
. It can also be shown that G = L with high probability is the number of positions is, say, at least 50; it is a bit harder to analyze though, but the general idea is that while it's hard to determine the exact distribution of f(a, b), it is \emph{not that bad}, so it is improbable for many values of f(a, b) to be, say, multiples of 2L apart.
I want to describe another, much simpler solution by Chmel_Tolstiy. Let's find the smallest k such that color(2k) ≠ color(0). It is easy to prove that there is exactly one change color between these two positions, so its position can be found with binary search as before. Do the same way in negative direction and find another closest color change, output the difference. This solution turned out to be most popular among contestants (but less popular among the testers).
Problem E
Let's find out how to check if the answer is at most D and binary search on D.
Let's make an arbitrary vertex the root of the tree. Note that if the subtree of any vertex v contains even number of outposts then no paths can come out of the subtree (since their number must be even, but at most one path can pass through an edge). Similarly, if there is an odd number of outposts then one path must come out of the subtree. Consider all children of v: each of their subtrees will either yield a single path or nothing. We have to match the resulting paths between each other and choose at most one of them to yield to the parent. Naturally, our intention is to make the unmatched path as short as possible while making suring that in each pair of matched paths their total length does not exceed D. We can also note that the answer is never - 1 since we can always match the paths if we ignore their lengths.
Consider the case when we have to match an even number of paths. Let's say we have an array of even length a1, \ldots, a2k, and want to make pairs of its elements such that sum in each pair does not exceed D. It can be shown that the optimal way is to sort the array and then match a1 + a2k, a2 + a2k - 1, and so on. Indeed, consider that a1 is not matched with a2k but with ax, and a2k is matched with ay. Let's rematch them as a1 + a2k and ax + ay. Since the array is sorted, a1 + a2k, ax + ay ≤ ay + a2k and the maximum sum won't increase after rematching. Drop the elements a1 and a2k and proceed until we obtain the matching a1 + a2k, a2 + a2k - 1, \ldots.
Now we want to match an odd number of paths while minimizing the unmatched path length. This can be done with binary search on unmatched length and checking if the rest of the paths can be matched using previous approach. Another approach is greedy: take the maximal element x, find maximal element y such that x + y ≤ D, erase them both. If there is no such y, then x must be unmatched. Finally, check if there is at most one unmatched element. All these approaches take 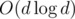 time for a vertex with d children, but the real time depends hugely on the actual approach (say, using std::set or TreeSet is much slower than sorts and binary searches).
time for a vertex with d children, but the real time depends hugely on the actual approach (say, using std::set or TreeSet is much slower than sorts and binary searches).
The total complexity is 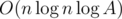 , where A is maximal possible answer value.
, where A is maximal possible answer value.
Problem F
Consider all possible values of a and b such that 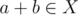 . Let's arrange them in a table, roughly like this (second sample, O stands for possible value, . for impossible):
. Let's arrange them in a table, roughly like this (second sample, O stands for possible value, . for impossible):
0 1 2
0 O O .
1 O . .
2 . . .
When can one determine the numbers? Consider the position (0, 2): the person with number 2 knows that the only possible pair is (0, 2), so he can answer it. In general, once there is only one possible value in some row or some column this value is removed on this day since one person can deduce the other number. So, after day 1, the table becomes (X stands for no longer possible value):
0 1 2
0 O X .
1 X . .
2 . . .
Now position (0, 0) can be solved on day 2 according to our rule. One can see that in the third sample the only solvable positions are (0, 2) and (2, 0).
It is tempting to look for a simple formula, but behaviour of how positions are resolved turns out to be complex (for example, try X = {5, 13, 20}). We should look for a way to simulate the process efficiently.
First, note that there will be at most 2(A + 1) resolved positions, where A is the maximal element of X. Indeed, each resolved position leaves a new empty row or a column. Thus, the process will terminate quite quickly, but the total number of possible initial positions is too large to choose resolved positions straightforwardly.
There are few possible optimization. For one, suppose we have the data structure with following operations: initialize with a set of numbers, remove a single number, once there is a single number in the set, find it. Let's store this kind of structure for each row and column, now the process can be simulated easily. The simplest way to implement this structure is to store a pair (sum of numbers, count of numbers). Moreover, all the structures can be initialized at once in O(A) time using prefix sums and prefix counts.
Another idea: if there are three consecutive numbers xi, xi + 1, xi + 2 with xi + 2 ≤ xi + xi + 1 + 1, then all positions with a + b < xi will be unsolvable. If we drop all xj < xi, the sum of the rest elements of X will be O(A), which allows for a simple simulation.


