


1770A - Koxia and Whiteboards
Idea by m_99
Exactly $$$n$$$ items out of of $$$a_1,\ldots,a_n,b_1,\ldots,b_m$$$ will remain on the whiteboard at the end.
$$$b_m$$$ will always remain on the board at the end.
Consider the case where $$$n=2$$$ and $$$m=2$$$. As we mentioned in hint 2, $$$b_2$$$ will always be written, but what about $$$b_1$$$?
This problem can be solved naturally with a greedy algorithm — for $$$i = 1, 2, \dots, m$$$, we use $$$b_i$$$ to replace the minimal value among the current $$$a_1, a_2, \dots, a_n$$$. The time complexity is $$$O(nm)$$$ for each test case.
Alternatively, we can first add $$$b_m$$$ to our final sum. For the remaining $$$(n+m-1)$$$ integers, we can freely pick $$$(n - 1)$$$ out of them and add it to our final sum. This is because if we want a certain $$$a_i$$$ to remain on the board at the end, we simply do not touch it in the process. If we want a certain $$$b_i$$$ to remain on the board at the end, then on the $$$i^{th}$$$ operation we replace some $$$a_j$$$ that we do not want at the end by $$$b_i$$$.
Using an efficient sorting algorithm gives us a $$$O((n + m) \log (n + m))$$$ solution, which is our intended solution.
#include <stdio.h>
#include <bits/stdc++.h>
using namespace std;
#define rep(i,n) for (int i = 0; i < (n); ++i)
#define Inf32 1000000001
#define Inf64 4000000000000000001
int main(){
int _t;
cin>>_t;
rep(_,_t){
int n,m;
cin>>n>>m;
vector<long long> a(n+m);
rep(i,n+m)scanf("%lld",&a[i]);
sort(a.begin(),a.end()-1);
reverse(a.begin(),a.end());
long long ans = 0;
rep(i,n)ans += a[i];
cout<<ans<<endl;
}
return 0;
}
1770B - Koxia and Permutation
Idea by m_99
For $$$k = 1$$$, the cost is always $$$2n$$$ for any permutation.
For $$$k \geq 2$$$, the minimal cost is always $$$n + 1$$$.
When $$$k = 1$$$ every permutation has the same cost.
When $$$k \geq 2$$$, the minimal cost will be at least $$$n+1$$$. This is because there will always be at least one segment containing the element $$$n$$$ in the permutation, contributing $$$n$$$ to the "max" part of the sum, and the "min" part will add at least $$$1$$$ to the sum.
In fact, the cost $$$n+1$$$ is optimal. It can be achieved by ordering the numbers in the pattern $$$[n, 1, n - 1, 2, n - 2, 3, n - 3, 4, \dots]$$$.
The time complexity is $$$O(n)$$$ for each test case. Other careful constructions should also get Accepted.
#include <iostream>
#define MULTI int _T; cin >> _T; while(_T--)
using namespace std;
typedef long long ll;
int n, k;
int main () {
ios::sync_with_stdio(0);
cin.tie(0);
MULTI {
cin >> n >> k;
int l = 1, r = n, _ = 1;
while (l <= r) cout << ((_ ^= 1) ? l++ : r--) << ' ';
cout << endl;
}
}
1770C - Koxia and Number Theory
Idea by triple__a
If $$$a_i$$$ are not pairwise distinct we get a trivial NO.
If all $$$a_i$$$ are pairwise distinct, can you construct an example with $$$n = 4$$$ that gives an answer NO?
Perhaps you are thinking about properties such as parity? Try to generalize the idea.
Consider every prime. Consider Chinese Remainder Theorem.
How many primes should we check? Consider Pigeonhole Principle.
First, we should check whether the integers in $$$a$$$ are pairwise distinct, as $$$a_i + x \geq 2$$$ and $$$\gcd(t,t)=t$$$, which leads to a trivial NO.
Given an integer $$$x$$$, let's define $$$b_i := a_i + x$$$. The condition "$$$\gcd(b_i,b_j)=1$$$ for $$$1\le i < j \le n$$$" is equivalent to "every prime $$$p$$$ should divides at most one $$$b_i$$$". Given a prime $$$p$$$, how should we verify whether for every $$$x > 0$$$, $$$p$$$ divides at least two elements in $$$b$$$?
A small but guided sample is $$$a = [5, 6, 7, 8]$$$ with answer NO, because
- $$$\gcd(6 + x, 8 + x) \neq 1$$$ if $$$x \equiv 0 \pmod 2$$$,
- $$$\gcd(5 + x, 7 + x) \neq 1$$$ if $$$x \equiv 1 \pmod 2$$$.
That is, if we consider $$$[5, 6, 7, 8]$$$ modulo $$$2$$$, we obtain the multiset $$${1, 0, 1, 0}$$$. Both $$$0$$$ and $$$1$$$ appeared twice, so for any choice of $$$x$$$, exactly two integers in $$$b$$$ will be divided by $$$2$$$.
This idea can be extended to larger primes. For a given prime $$$p$$$, let $$$cnt_j$$$ be the multiplicity of $$$j$$$ in the multiset $$$[ a_i \text{ mod } p, a_2 \text{ mod } p, \dots, a_n \text{ mod } p ]$$$. If $$$\min(\mathit{cnt}_0, \mathit{cnt}_1, \dots, \mathit{cnt}_{p-1}) \geq 2$$$, we output NO immediately.
While there are many primes up to $$${10}^{18}$$$, we only need to check for the primes up to $$$\lfloor \frac{n}{2} \rfloor$$$. This is because $$$\min(\mathit{cnt}_0, \mathit{cnt}_1, \dots, \mathit{cnt}_{p-1}) \geq 2$$$ is impossible for greater primes according to Pigeonhole Principle. Since the number of primes up to $$$\lfloor \frac{n}{2} \rfloor$$$ is at most $$$O\left(\frac{n}{\log n} \right)$$$, the problem can be solved in time $$$O\left(\frac{n^2}{\log n} \right)$$$.
The reason that $$$\min(\mathit{cnt}) \geq 2$$$ is essential because for a prime $$$p$$$, if $$$a_u \equiv a_v \pmod p$$$, then it's necessary to have $$$(x + a_u) \not\equiv 0 \pmod p$$$, because $$$\gcd(x + a_u, x + a_v)$$$ will be divided by $$$p$$$ otherwise. So actually, $$$\mathit{cnt}_i \geq 2$$$ means $$$x \not\equiv (p-i) \pmod p$$$. If $$$\min(\mathit{cnt}) < 2$$$ holds for all primes, then we can list certain congruence equations and use Chinese Reminder Theorem to calculate a proper $$$x$$$; if there exists a prime that $$$\min(\mathit{cnt}) \geq 2$$$, then any choose of $$$x$$$ leads to the situation that $$$p$$$ appears twice.
#include <iostream>
#include <algorithm>
#define MULTI int _T; cin >> _T; while(_T--)
using namespace std;
typedef long long ll;
const int N = 105;
const int INF = 0x3f3f3f3f;
template <typename T> bool chkmin (T &x, T y) {return y < x ? x = y, 1 : 0;}
template <typename T> bool chkmax (T &x, T y) {return y > x ? x = y, 1 : 0;}
int n;
ll a[N];
int cnt[N];
int main () {
ios::sync_with_stdio(0);
cin.tie(0);
MULTI {
cin >> n;
for (int i = 1;i <= n;++i) {
cin >> a[i];
}
int isDistinct = 1;
sort(a + 1, a + n + 1);
for (int i = 1;i <= n - 1;++i) {
if (a[i] == a[i + 1]) isDistinct = 0;
}
if (isDistinct == 0) {
cout << "NO" << endl;
continue;
}
int CRT_able = 1;
for (int mod = 2;mod <= n / 2;++mod) {
fill(cnt, cnt + mod, 0);
for (int i = 1;i <= n;++i) {
cnt[a[i] % mod]++;
}
if (*min_element(cnt, cnt + mod) >= 2) CRT_able = 0;
}
cout << (CRT_able ? "YES" : "NO") << endl;
}
}
1770D - Koxia and Game
Idea by m_99
If all of $$$a$$$, $$$b$$$ and $$$c$$$ are fixed, how to determine who will win?
If $$$a$$$ and $$$b$$$ are fixed, design an algorithm to check if there is an array $$$c$$$ that makes Koxia wins.
If you can't solve the problem in Hint 2, try to think about how it's related to graph theory.
Try to discuss the structure of components in the graph to count up the number of $$$c$$$.
Firstly, let's consider how an array $$$c$$$ could make Koxia wins.
Lemma 1. In each round, Koxia should remove an element in $$$S$$$ to make the remaining $$$2$$$ elements in $$$S$$$ the same (i.e. Mahiru's choice determined nothing actually).
- In round $$$n$$$, if Koxia leaves two choices for Mahiru then Mahiru will be able to prevent $$$d$$$ from being a permutation.
- This means if Koxia wins, there is only one choice for $$$d_n$$$.
- Now $$$(d_1, d_2, \dots, d_{n-1})$$$ have to be a permutation of a specific $$$n-1$$$ numbers. Apply the same argument on $$$d_{n-1}$$$ and so on, we can conclude that every $$$d_i$$$ only has one choice if Koxia wins.
Lemma 2. Let $$$p$$$ be array of length $$$n$$$ where we can set $$$p_i$$$ to either $$$a_i$$$ or $$$b_i$$$. Koxia wins iff there exists a way to make $$$p$$$ a permutation.
- According to Lemma 1, if there is a way to make $$$p$$$ a permutation, we can just set $$$c_i = p_i$$$. Koxia can then force Mahiru to set $$$d_i = p_i$$$ every round and Koxia will win.
- If it is impossible to make $$$p$$$ a permutation, Mahiru can pick either $$$a_i$$$ or $$$b_i$$$ (at least one of them is available) every round. The resulting array $$$d$$$ is guaranteed to not be a permutation.
First, we need an algorithm to determine if there is a way to make $$$p$$$ a permutation.
We can transform this into a graph problem where $$$(a_i, b_i)$$$ are edges in a graph with $$$n$$$ vertices. Then there is a way to make $$$p$$$ a permutation iff there is a way to assign a direction for every edge such that every vertex has one edge leading into it. It is not hard to see that this is equivalent to the condition that for every connected component, the number of edges equals the number of vertices. We can verify this by a Disjoint-Set Union or a graph traversal in $$$O(n \alpha(n))$$$ or $$$O(n)$$$ time complexity.
To solve the counting problem, we consider the structure of the connected components one by one. A component with $$$|V| = |E|$$$ can be viewed as a tree with an additional edge. This additional edge can be categorized into two cases:
- The additional edge forms a cycle together with some of the other edges. There are $$$2$$$ choices for the cycle (clockwise and counterclockwise), and the choices of other edges are fixed then (point away from the cycle).
- The additional edge forms a self-loop. Then the value of $$$c_i$$$ determines nothing in this situation so it can be any integers in $$$[1, n]$$$, and the choices of all other edges are fixed.
Therefore, if exists at least one $$$c$$$ to make Koxia wins, then the answer is $$$2^{\textrm{cycle component cnt}} \cdot n^{\textrm{self-loop component cnt}}$$$. The time complexity is $$$O(n \alpha(n))$$$ or $$$O(n)$$$.
#include <iostream>
#include <numeric>
#define MULTI int _T; cin >> _T; while(_T--)
using namespace std;
typedef long long ll;
const int N = 1e5 + 5;
const int mod = 998244353;
int n;
int a[N], b[N];
int fa[N], cnt_v[N], cnt_e[N], selfloop[N];
int vis[N];
void init () {
iota(fa + 1, fa + n + 1, 1);
fill(cnt_v + 1, cnt_v + n + 1, 1);
fill(cnt_e + 1, cnt_e + n + 1, 0);
fill(selfloop + 1, selfloop + n + 1, 0);
fill(vis + 1, vis + n + 1, 0);
}
int getfa (int x) {
return fa[x] == x ? x : fa[x] = getfa(fa[x]);
}
void merge (int u, int v) {
u = getfa(u);
v = getfa(v);
cnt_v[u] += cnt_v[v];
cnt_e[u] += cnt_e[v];
selfloop[u] |= selfloop[v];
fa[v] = u;
}
int main () {
ios::sync_with_stdio(0);
cin.tie(0);
MULTI {
cin >> n;
for (int i = 1;i <= n;++i) {
cin >> a[i];
}
for (int i = 1;i <= n;++i) {
cin >> b[i];
}
init();
for (int i = 1;i <= n;++i) {
if (getfa(a[i]) != getfa(b[i])) merge(a[i], b[i]);
cnt_e[getfa(a[i])]++;
if (a[i] == b[i]) selfloop[getfa(a[i])] = 1;
}
ll ans = 1;
for (int i = 1;i <= n;++i) if (vis[getfa(i)] == 0) {
if (cnt_v[getfa(i)] != cnt_e[getfa(i)]) ans = 0;
else ans = ans * (selfloop[getfa(i)] ? n : 2) % mod;
vis[getfa(i)] = 1;
}
cout << ans << endl;
}
}
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5;
const int P = 998244353;
int n, a[N], b[N];
vector <int> G[N];
bool vis[N];
int vertex, edge, self_loop;
void dfs(int x) {
if (vis[x]) return ;
vis[x] = true;
vertex++;
for (auto y : G[x]) {
edge++;
dfs(y);
if (y == x) {
self_loop++;
}
}
}
void solve() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) scanf("%d", &a[i]);
for (int i = 1; i <= n; i++) scanf("%d", &b[i]);
for (int i = 1; i <= n; i++) G[i].clear();
for (int i = 1; i <= n; i++) {
G[a[i]].push_back(b[i]);
G[b[i]].push_back(a[i]);
}
int ans = 1;
for (int i = 1; i <= n; i++) vis[i] = false;
for (int i = 1; i <= n; i++) {
if (vis[i]) continue ;
vertex = 0;
edge = 0;
self_loop = 0;
dfs(i);
if (edge != 2 * vertex) {
ans = 0;
} else if (self_loop) {
ans = 1ll * ans * n % P;
} else {
ans = ans * 2 % P;
}
}
printf("%d\n", ans);
}
int main() {
int t;
scanf("%d", &t);
while (t--) {
solve();
}
return 0;
}
1770E - Koxia and Tree
Idea by m_99
Solve a classic problem — find the sum of pairwise distances of $$$k$$$ chosen nodes in a tree.
If we add the move operations while the direction of edges are fixed, find the sum of pairwise distances of $$$k$$$ chosen nodes.
If you can't solve the problem in Hint 2, consider why writers make each edge passed by butterflies for at most once.
When the direction of edges become random, how maintaining $$$p_i$$$ as the possibility of "node $$$i$$$ contains a butterfly" help you to get the answer?
At first sight, we usually think of a classic problem — find the sum of pairwise distances of $$$k$$$ chosen nodes in a tree. For any edge, if there are $$$x$$$ chosen nodes and $$$n - x$$$ chosen nodes respectively on each side of it, then there will be $$$x (n - x)$$$ pairs of nodes passing this edge. Without loss of generality, let's assign node $$$1$$$ as root, and define both $$$\mathit{siz}_i$$$ as the number of chosen nodes in subtree $$$i$$$. By summing up $$$\mathit{siz}_{\mathit{son}} (n - \mathit{siz}_{\mathit{son}})$$$ for each edge $$$(\mathit{fa}, \mathit{son})$$$, we derive the answer, which equals to the expected value of the distance of two nodes (Uniformly randomly chosen from $$$k$$$ nodes) after dividing by $$$\binom{k}{2}$$$.
Let's turn to Hint 2 then — add the move operations while the direction of edges are fixed. Let's define $$$\mathit{siz}^0_i$$$ and $$$\mathit{siz}_i$$$ as the number of butterflies in subtree $$$i$$$, but before any move operation / in real time respectively. A very important observation is, although butterflies are moving, we can always claim $$$|\mathit{siz}_{\mathit{son}} - \mathit{siz}^0_{\mathit{son}}| \leq 1$$$ because each edge is passed by butterflies for at most once. This property allows us to discuss different values of $$$\mathit{siz}_{\mathit{son}}$$$ to sum up the answer in constant time complexity, if you maintain butterflies' positions correctly.
When we introduce random directions additionally, if we define $$$p_i$$$ as the possibility of "node $$$i$$$ contains a butterfly", then an equivalent statement of move operation from node $$$u$$$ to node $$$v$$$ will be, actually, set $$$p_u = p_v = \frac{p_u+p_v}{2}$$$, which allows us to maintain $$$p$$$ in real time easily. Similarly, by discussing values of $$$\mathit{siz}_{\mathit{son}}$$$ (but with possibilities of each case instead of specified moves), we get the final answer. The total time complexity is $$$O(n)$$$.
#include <iostream>
#include <vector>
using namespace std;
typedef long long ll;
const int N = 3e5 + 5;
const int mod = 998244353;
const int inv2 = 499122177;
ll qpow (ll n, ll m) {
ll ret = 1;
while (m) {
if (m & 1) ret = ret * n % mod;
n = n * n % mod;
m >>= 1;
}
return ret;
}
ll getinv (ll a) {
return qpow(a, mod - 2);
}
int n, k;
int a[N];
int u[N], v[N];
vector <int> e[N];
int fa[N];
ll p[N], sum[N];
void dfs (int u, int f) {
sum[u] = p[u];
for (int v : e[u]) if (v != f) {
dfs(v, u);
fa[v] = u;
sum[u] += sum[v];
}
}
int main () {
ios::sync_with_stdio(0);
cin.tie(0);
cin >> n >> k;
for (int i = 1;i <= k;++i) {
cin >> a[i];
p[a[i]] = 1;
}
for (int i = 1;i <= n - 1;++i) {
cin >> u[i] >> v[i];
e[u[i]].push_back(v[i]);
e[v[i]].push_back(u[i]);
}
dfs(1, -1);
ll ans = 0;
for (int i = 1;i <= n - 1;++i) {
if (fa[u[i]] == v[i]) swap(u[i], v[i]);
ll puv = p[u[i]] * (1 - p[v[i]] + mod) % mod;
ll pvu = p[v[i]] * (1 - p[u[i]] + mod) % mod;
ll delta = 0;
delta -= puv * sum[v[i]] % mod * (k - sum[v[i]]) % mod;
delta -= pvu * sum[v[i]] % mod * (k - sum[v[i]]) % mod;
delta += puv * (sum[v[i]] + 1) % mod * (k - sum[v[i]] - 1) % mod;
delta += pvu * (sum[v[i]] - 1) % mod * (k - sum[v[i]] + 1) % mod;
ans = (ans + sum[v[i]] * (k - sum[v[i]]) + delta * inv2) % mod;
ans = (ans % mod + mod) % mod;
p[u[i]] = p[v[i]] = 1ll * (p[u[i]] + p[v[i]]) * inv2 % mod;
}
cout << ans * getinv(1ll * k * (k - 1) / 2 % mod) % mod << endl;
}
1770F - Koxia and Sequence
Idea by m_99
From symmetry, for any non-negative integer $$$t$$$, the number of good sequences with $$$a_1=t$$$, the number of good sequences with $$$a_2=t$$$, ... are equal.
It is useful to consider the contribution of each bit to the answer independently.
Since XOR is undone twice, considering the contribution to the answer can be regarded as counting up over mod $$$2$$$.
It is difficult to count those for which total or is $$$y$$$, but it is relatively easy to count those for which total or is a subset of $$$y$$$. Then, we can consider a way using the inclusion-exclusion principle.
Lucas's theorem and Kummer's theorem are useful. In particular, you can derive equivalence conditions on or.
"There are $$$a+b$$$ white balls. For every pair $$$(c,d)$$$ of nonnegative integers satisfying $$$c+d=n$$$, find the sum of the ways to choose $$$c$$$ balls from the first $$$a$$$ balls and $$$d$$$ balls from the remaining $$$b$$$ balls." The answer to this problem is $$$_{a+b} C_{n}$$$. This is because considering how to choose for every pair $$$(c,d)$$$ of non-negative integers satisfying $$$c+d=n$$$ merely consider the case of choosing $$$n$$$ balls as how many balls to choose from $$$a$$$ balls and $$$b$$$ balls. This result is called Vandermonde's identity.
Let $$$f(i,t)$$$ is the number of good sequence such that $$$a_i=t$$$. $$$f(1,t)=f(2,t)=...=f(n,t)$$$, so if $$$n$$$ is even, the answer is $$$0$$$. Otherwise, the answer is total xor of $$$t$$$ such that number of good sequences such that $$$a_1=t$$$ is odd. We can consider each bit independently, so we can rewrite the problem "for each $$$i$$$, find the number of good sequences such that $$$a_1$$$'s $$$i$$$-th bit is $$$1$$$, modulo $$$2$$$".
Let $$$g(y')$$$ is the answer if $$$y$$$ is a subset of $$$y'$$$(means $$$y \mid y'=y'$$$). We can prove with induction the answer of the original problem is total xor of $$$g(y')$$$ such that $$$y'$$$ is a subset of given $$$y$$$. So, the goal is for each $$$i$$$, find the number of $$$y'$$$ such that $$$y'$$$ is a subset of $$$y$$$ and $$$g(y')$$$'s $$$i$$$-th bit is $$$1$$$, modulo $$$2$$$.
We can prove with Lucas's theorem or Kummer's theorem ($$$p=2$$$), "$$$\binom{a}{b} \bmod 2$$$ is $$$1$$$" is equivalent to "$$$b$$$ is a subset of $$$a$$$". The number of sequences such that the length is $$$n$$$ and total sum is $$$x$$$ and total or is a subset of $$$y$$$, modulo $$$2$$$ is equal to $$$\sum_{t_1+\ldots+t_n=x} \prod{} \binom{y}{t_i}$$$, because if there is $$$t_i$$$ which is not a subset of $$$y$$$, $$$\binom{y}{t_i}$$$ is $$$0$$$ and the product is also $$$0$$$, modulo $$$2$$$. Consider Vandermonde's identity, the value is equal to $$$\binom{ny}{x}$$$. In a similar way, we can rewrite the problem to "for each $$$i$$$, find the number of $$$y'$$$ such that $$$y'$$$ is a subset of $$$y$$$ and $$$y'$$$'s $$$i$$$-th bit is $$$1$$$ and $$$x-2^i$$$ is a subset of $$$ny'-2^i$$$($$$\binom{ny'-2^i}{x-2^i} \bmod 2 = 1$$$), modulo $$$2$$$".
From the above, we can solve this problem in $$$O(y \log y)$$$ by performing the calculation in $$$O(1)$$$ for all $$$i$$$ and all $$$y'$$$.
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define ll long long
#define ii pair<ll,ll>
#define iii pair<ii,ll>
#define fi first
#define se second
#define endl '\n'
#define debug(x) cout << #x << ": " << x << endl
#define pub push_back
#define pob pop_back
#define puf push_front
#define pof pop_front
#define lb lower_bound
#define ub upper_bound
#define rep(x,start,end) for(int x=(start)-((start)>(end));x!=(end)-((start)>(end));((start)<(end)?x++:x--))
#define all(x) (x).begin(),(x).end()
#define sz(x) (int)(x).size()
mt19937 rng(chrono::system_clock::now().time_since_epoch().count());
int n,a,b;
bool isSub(int i,int j){
if (i<0 || j<0) return false;
return (j&i)==i;
}
signed main(){
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin.exceptions(ios::badbit | ios::failbit);
cin>>n>>a>>b;
int ans=0;
for (int sub=b;sub;sub=(sub-1)&b) rep(bit,0,20) if (sub&(1<<bit)){
if (isSub(a-(1<<bit),n*sub-(1<<bit))){
ans^=(1<<bit);
}
}
cout<<ans*(n%2)<<endl;
}
1770G - Koxia and Bracket
Idea by huangxiaohua and errorgorn
What special properties does the deleted bracket sequence have?
Try to solve this with $$$O(n^2)$$$ DP.
If there is no balance requirement, can multiple brackets be processed quickly with one operation?
Can you combine the last idea with divide-and-conquer or something?
$$$O(n^2)$$$ Solution
Let us consider what properties the removed bracket subsequence has.
First, it must be a bracket subsequence in the form ))...)((....(. The proof is simple: if there is a deleted ) on the right-hand side of a (, then we can keep them in $$$s$$$ without breaking the balancing property of the remaining sequence.
This property means that we can divide the string into $$$2$$$ parts. We only delete ) from the first part and only delete ( from the second part. Now let us try to find the dividing point between the two parts: Consider a prefix sum based on a sequence of brackets in which each ( is replaced by 1 and each ) is replaced by -1.
We define a position as a special position if and only if the number corresponding to this position is less than the previously occurring minimum value. It is easy to see that whenever a special position occurs, we must remove an additional ) before this position to make the bracket sequence satisfy the condition again.
Considering the above idea, we can find that only the ) before the farthest special position may be deleted, so we can use this position as the dividing point.
We now solve two separate problems. However, we can turn the problem on deleting only '(' into the one on deleting only ). For example, if we are only allowed to delete ( from (()((()()), it is equivalent to the number of ways to delete only ) from (()()))()).
For the part where only ) is deleted, the sufficient condition for it to be a balanced bracket sequence is that each number in the prefix sum must be greater than 0 after the operation.
Also considering the above ideas, let us define the state $$$dp_{i,j}$$$, which represents after removing the breakets required by special position, the number of ways to delete additional $$$j$$$ $$$(j \geq 0)$$$ occurrence of ) from the string up the $$$i$$$-th occurrence of ) in the string.
Multiply the $$$dp_{end,0}$$$ obtained from both parts of the string to obtain the answer. The time complexity is $$$O(n^2)$$$ and optimized implementations can run in about 9 seconds, but it is not enough to pass.
$$$O(n\sqrt{n \log n})$$$ Solution
Let's try to optimize the transitions when there are no special positions. For state $$$dp_{i,j}$$$, after processing $$$k$$$ individual ), the transitions are as follows:
We find that this transfer equation behaves as a polynomial convolution. Thus we can optimize this convolution by NTT with a time complexity of $$$O(n \log n)$$$ for a single operation, while the worst global complexity of this Solution is $$$O(n^2 \log n)$$$ due to the presence of the special position.
Consider how this Solution can be combined with the $$$O(n^2)$$$ Solution. For states $$$dp_{i,j}$$$ where we want to consider its contribution to $$$dp_{i+k}$$$, if $$$j \geq k$$$ is satisfied, then the transitions are not affected by the special position anyway.
Based on the above idea, we can adopt a mixed Solution based on periodic reconstruction: set the reconstruction period $$$B$$$, and within one round of the period, we use the $$$O(n^2)$$$ DP Solution to handle the part of $$$j \le B$$$, while for the part of $$$j>B$$$, we compute the answer by NTT after one round of the period.
The time complexity $$$O(\frac{n^2}{B}+B\cdot n \log n)$$$ can be optimized to $$$O(n\sqrt{n \log n})$$$ by setting the appropriate $$$B$$$. Although the time complexity is still high, given the low constant factor of the $$$O(n^2)$$$ solution, a decently-optimized implementation is able to get AC.
$$$O(n\log^2 n)$$$ Solution
Consider combining the idea of extracting $$$j \geq k$$$ parts for NTT with divide-and-conquer. Suppose now that the interval to be processed is $$$(l,r)$$$, where the DP polynomial passed is $$$s$$$. We proceed as follows:
- Count the number of special positions $$$num$$$ in the interval $$$(l,r)$$$, extract the part of the polynomial $$$s$$$ corresponding to the state $$$j \geq num$$$, and convolute it with the current interval alone.
- Pass the part of the polynomial $$$s$$$ corresponding to the state $$$j < num$$$ into the interval $$$(l,mid)$$$, and then pass the result into the interval $$$(mid+1,r)$$$ to continue the operation.
- Add the polynomials obtained by the above two steps directly, and return the obtained polynomial.
How to calculate the time complexity of performing the above operations? Let's analyze the operations passed into the left interval and the right interval separately.
- When passing in the left interval $$$(l,mid)$$$, the size of the polynomial for the NTT operation is the number of special positions in the interval $$$(l,r)$$$ minus the number of special positions in the left interval $$$(l,mid)$$$, i.e., the number of special positions in the right interval $$$(mid+1,r)$$$, which does not exceed the length of the right interval $$$(mid+1,r)$$$.
- When passed into the right interval $$$(mid+1,r)$$$, the size of the polynomial does not exceed the length of the left interval $$$(l,mid)$$$.
- Also, the length of the combinatorial polynomial multiplied with $$$s$$$ is the interval length + 1.
In summary, the size of the two polynomials for the NTT operation in the interval $$$(l,r)$$$ does not exceed the interval length + 1. Thus the time complexity of this solution is divide-and-conquer combined with the time complexity of NTT, i.e. $$$O(n \log^2 n)$$$.
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <ext/rope>
using namespace std;
using namespace __gnu_pbds;
using namespace __gnu_cxx;
#define int long long
#define ll long long
#define ii pair<ll,ll>
#define iii pair<ii,ll>
#define fi first
#define se second
#define endl '\n'
#define debug(x) cout << #x << ": " << x << endl
#define pub push_back
#define pob pop_back
#define puf push_front
#define pof pop_front
#define lb lower_bound
#define ub upper_bound
#define rep(x,start,end) for(auto x=(start)-((start)>(end));x!=(end)-((start)>(end));((start)<(end)?x++:x--))
#define all(x) (x).begin(),(x).end()
#define sz(x) (int)(x).size()
#define indexed_set tree<ll,null_type,less<ll>,rb_tree_tag,tree_order_statistics_node_update>
//change less to less_equal for non distinct pbds, but erase will bug
mt19937 rng(chrono::system_clock::now().time_since_epoch().count());
const int MOD=998244353;
ll qexp(ll b,ll p,int m){
ll res=1;
while (p){
if (p&1) res=(res*b)%m;
b=(b*b)%m;
p>>=1;
}
return res;
}
ll inv(ll i){
return qexp(i,MOD-2,MOD);
}
ll fix(ll i){
i%=MOD;
if (i<0) i+=MOD;
return i;
}
ll fac[1000005];
ll ifac[1000005];
ll nCk(int i,int j){
if (i<j) return 0;
return fac[i]*ifac[j]%MOD*ifac[i-j]%MOD;
}
//https://github.com/kth-competitive-programming/kactl/blob/main/content/numerical/NumberTheoreticTransform.h
const ll mod = (119 << 23) + 1, root = 62; // = 998244353
// For p < 2^30 there is also e.g. 5 << 25, 7 << 26, 479 << 21
// and 483 << 21 (same root). The last two are > 10^9.
typedef vector<int> vi;
typedef vector<ll> vl;
void ntt(vl &a) {
int n = sz(a), L = 31 - __builtin_clz(n);
static vl rt(2, 1);
for (static int k = 2, s = 2; k < n; k *= 2, s++) {
rt.resize(n);
ll z[] = {1, qexp(root, mod >> s, mod)};
rep(i,k,2*k) rt[i] = rt[i / 2] * z[i & 1] % mod;
}
vi rev(n);
rep(i,0,n) rev[i] = (rev[i / 2] | (i & 1) << L) / 2;
rep(i,0,n) if (i < rev[i]) swap(a[i], a[rev[i]]);
for (int k = 1; k < n; k *= 2)
for (int i = 0; i < n; i += 2 * k) rep(j,0,k) {
ll z = rt[j + k] * a[i + j + k] % mod, &ai = a[i + j];
a[i + j + k] = ai - z + (z > ai ? mod : 0);
ai += (ai + z >= mod ? z - mod : z);
}
}
vl conv(const vl &a, const vl &b) {
if (a.empty() || b.empty()) return {};
int s = sz(a) + sz(b) - 1, B = 32 - __builtin_clz(s), n = 1 << B;
int inv = qexp(n, mod - 2, mod);
vl L(a), R(b), out(n);
L.resize(n), R.resize(n);
ntt(L), ntt(R);
rep(i,0,n) out[-i & (n - 1)] = (ll)L[i] * R[i] % mod * inv % mod;
ntt(out);
return {out.begin(), out.begin() + s};
}
vector<int> v;
vector<int> solve(int l,int r,vector<int> poly){
if (poly.empty()) return poly;
if (l==r){
poly=conv(poly,{1,1});
poly.erase(poly.begin(),poly.begin()+v[l]);
return poly;
}
int m=l+r>>1;
int num=0;
rep(x,l,r+1) num+=v[x];
num=min(num,sz(poly));
vector<int> small(poly.begin(),poly.begin()+num);
poly.erase(poly.begin(),poly.begin()+num);
vector<int> mul;
rep(x,0,r-l+2) mul.pub(nCk(r-l+1,x));
poly=conv(poly,mul);
small=solve(m+1,r,solve(l,m,small));
poly.resize(max(sz(poly),sz(small)));
rep(x,0,sz(small)) poly[x]=(poly[x]+small[x])%MOD;
return poly;
}
int solve(string s){
if (s=="") return 1;
v.clear();
int mn=0,curr=0;
for (auto it:s){
if (it=='(') curr++;
else{
curr--;
if (curr<mn){
mn=curr;
v.pub(1);
}
else{
v.pub(0);
}
}
}
return solve(0,sz(v)-1,{1})[0];
}
int n;
string s;
int pref[500005];
signed main(){
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin.exceptions(ios::badbit | ios::failbit);
fac[0]=1;
rep(x,1,1000005) fac[x]=fac[x-1]*x%MOD;
ifac[1000004]=inv(fac[1000004]);
rep(x,1000005,1) ifac[x-1]=ifac[x]*x%MOD;
cin>>s;
n=sz(s);
pref[0]=0;
rep(x,0,n) pref[x+1]=pref[x]+(s[x]=='('?1:-1);
int pos=min_element(pref,pref+n+1)-pref;
string a=s.substr(0,pos),b=s.substr(pos,n-pos);
reverse(all(b)); for (auto &it:b) it^=1;
cout<<solve(a)*solve(b)%MOD<<endl;
}
1770H - Koxia, Mahiru and Winter Festival
Idea by SteamTurbine
In what scenario the maximum congestion is $$$1$$$?
Assume you have a blackbox that can solve any problem instance of size $$$n-2$$$, use it to solve a problem instance of size $$$n$$$.
This is a special case for a problem called congestion minimization. While in general this problem is NP-hard, for this special structure it can be solved efficiently.
The only case where the maximum congestion is $$$1$$$, is when $$$p = q = [1,2,\dots,n]$$$. This can be proved by a pigeonhole argument — if there exists some $$$p_i \neq i$$$ or $$$q_i \neq i$$$, the total length of the $$$2n$$$ paths will be strictly greater than the number of edges which means at least one edge has to be used more than once.
Our goal now is to try constructing a routing scheme with maximum congestion $$$2$$$. We will show that this is always doable for any input. We will first show a pictorial sketch that presents the idea, and fill in the details later.
We also provide you a python script that visualize the output to help you debug, you can find it at the end of this section.
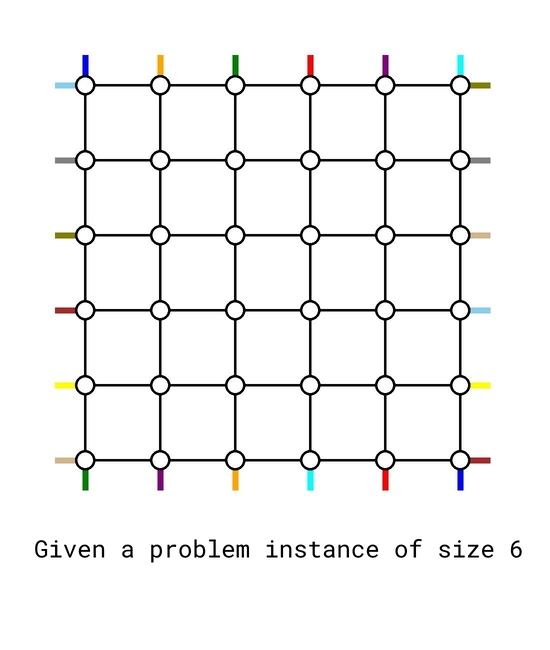
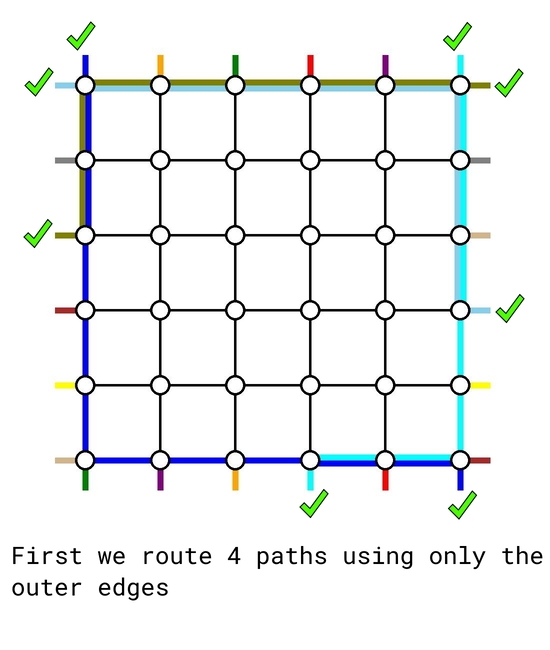
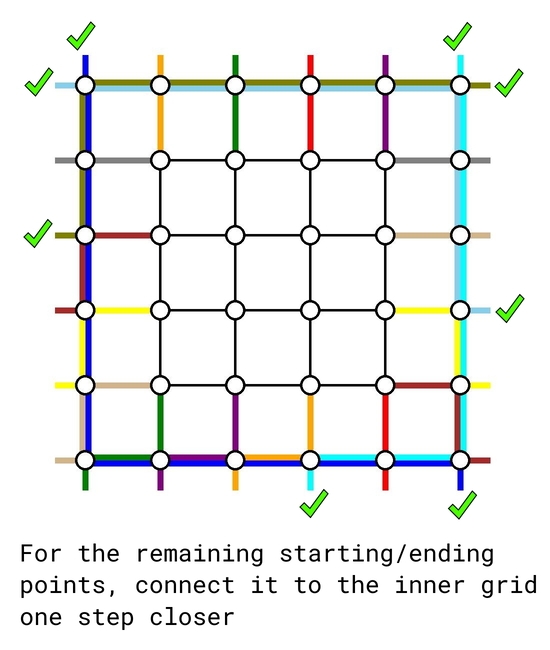
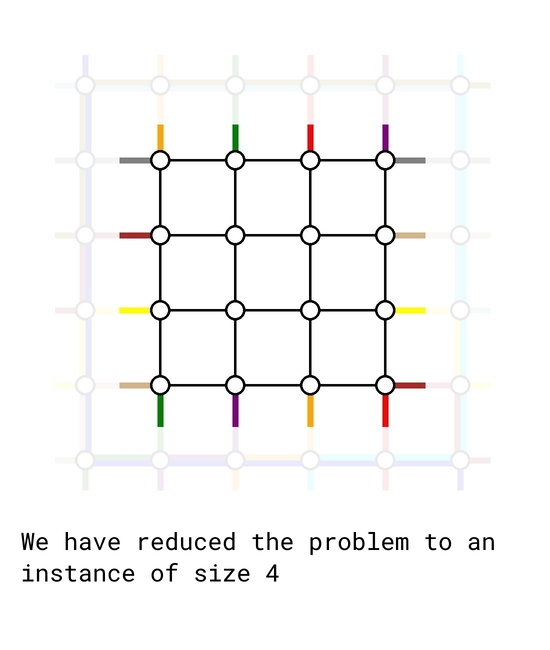
The solution is based on induction. The base cases $$$n=0$$$ and $$$n=1$$$ are trivial. Now assume we can solve any problem instance for size up to $$$k-2$$$. We will treat it as a blackbox to solve a problem instance of size $$$k$$$.
Given any problem instance of size $$$k$$$, first we route the following $$$4$$$ demand pairs using only the outer edges:
- the top-bottom pair that starts at $$$(1, 1)$$$, using the left and bottom edges;
- the top-bottom pair that starts at $$$(1, k)$$$, using the right and bottom edges;
- the left-right pair that starts at $$$(1, 1)$$$, using the top and right edges;
- the left-right pair that ends at $$$(1,k)$$$, using the left and top edges. However, if this is the same pair as above, then we route another arbitrary left-right pair using the left, top and right edges.
As of now, there are $$$k-2$$$ top-bottom demands and $$$k-2$$$ left-right demands remain to be routed. We simply connect their starting and ending points one step closer to the center, retaining their relative order. In such way, we reduced the problem to a problem instance of size $$$k-2$$$ which we already knew how to solve.
#include <bits/stdc++.h>
#define FOR(i,s,e) for (int i=(s); i<(e); i++)
#define FOE(i,s,e) for (int i=(s); i<=(e); i++)
#define FOD(i,s,e) for (int i=(s)-1; i>=(e); i--)
#define PB push_back
using namespace std;
struct Paths{
/* store paths in order */
vector<vector<pair<int, int>>> NS, EW;
Paths(){
NS.clear();
EW.clear();
}
};
Paths solve(vector<int> p, vector<int> q){
int n = p.size();
Paths Ret;
Ret.NS.resize(n);
Ret.EW.resize(n);
// Base case
if (n == 0) return Ret;
if (n == 1){
Ret.NS[0].PB({1, 1});
Ret.EW[0].PB({1, 1});
return Ret;
}
// Route NS flow originating from (1, 1) and (1, n) using leftmost and rightmost edges
FOE(i,1,n){
Ret.NS[0].PB({i, 1});
Ret.NS[n-1].PB({i, n});
}
// Routing to final destination using bottom edges
FOE(i,2,p[0]) Ret.NS[0].PB({n, i});
FOD(i,n,p[n-1]) Ret.NS[n-1].PB({n, i});
// Create p'[] for n-2 instance
vector<int> p_new(0);
FOE(i,1,n-2) p_new.PB(p[i] - (p[i]>p[0]) - (p[i]>p[n-1]));
// Route EW flow originating from (1, 1) using topmost and rightmost edges
FOE(i,1,n) Ret.EW[0].PB({1, i});
FOE(i,2,q[0]) Ret.EW[0].PB({i, n});
// Route EW flow originating in (m, 1) with q[m] as small as possible
int m = 1;
// special handle so congestion is 1 if possible
if (p[0] == 1 && p[n-1] == n && q[0] == 1 && q[n-1] == n){
m = n - 1;
FOE(i,1,n) Ret.EW[n-1].PB({n, i});
}
else{
FOR(i,1,n) if (q[i] < q[m]) m = i;
// Route(m+1, 1) --> (1, 1) --> (1, n) --> (q[m], n)
FOD(i,m+2,2) Ret.EW[m].PB({i, 1});
FOR(i,1,n) Ret.EW[m].PB({1, i});
FOE(i,1,q[m]) Ret.EW[m].PB({i, n});
}
// Create q'[] for n-2 instance
vector<int> q_new(0);
FOR(i,1,n) if (i != m) q_new.PB(q[i] - (q[i]>q[0]) - (q[i]>q[m]));
if (n > 1){
Paths S = solve(p_new, q_new);
int t;
// connect NS paths
FOR(i,1,n-1){
Ret.NS[i].PB({1, i+1});
for (auto [x, y]: S.NS[i-1]){
Ret.NS[i].PB({x+1, y+1});
t = y + 1;
}
Ret.NS[i].PB({n, t});
if (p[i] != t) Ret.NS[i].PB({n, p[i]});
}
// connect EW paths
int l = 0;
FOR(i,1,n) if (i != m){
Ret.EW[i].PB({i+1, 1});
if (i > m) Ret.EW[i].PB({i, 1});
for (auto [x, y]: S.EW[l]){
Ret.EW[i].PB({x+1, y+1});
t = x + 1;
}
Ret.EW[i].PB({t, n});
if (q[i] != t) Ret.EW[i].PB({q[i], n});
++l;
}
}
return Ret;
}
int main(){
int n;
vector<int> p, q;
scanf("%d", &n);
p.resize(n), q.resize(n);
FOR(i,0,n) scanf("%d", &p[i]);
FOR(i,0,n) scanf("%d", &q[i]);
Paths Solution = solve(p, q);
for (auto path: Solution.NS){
printf("%d", path.size());
for (auto [x, y]: path) printf(" %d %d", x, y);
puts("");
}
for (auto path: Solution.EW){
printf("%d", path.size());
for (auto [x, y]: path) printf(" %d %d", x, y);
puts("");
}
return 0;
}
# ---------------------------------------------------
# Visualize the ouput
# Pass the output as stdin to the script
# Only works for output with congestion at most 2
# Code by SteamTurbine Dec 2022
# ---------------------------------------------------
from PIL import Image, ImageDraw, ImageColor
from sys import stdin
import random
# Visual the ouput
# Pass the output as stdin to the script
Lines = [line for line in stdin if len(line.strip()) > 0]
n = int(len(Lines)/2)
im = Image.new('RGB', (n*150+200, n*150+200), (255, 255, 255))
draw = ImageDraw.Draw(im)
S = {(0,0,0,0)}
Dict = {}
Colors = ['orange', 'blue', 'green', 'red', 'skyblue', 'olive', 'brown', 'yellow', 'gray', 'tomato', 'tan' , 'purple', 'cyan', 'skyblue']
# use color map if n is large
if (n+n > len(Colors)):
Colors = []
for name, code in ImageColor.colormap.items():
if (name != "black" and name != "white"): Colors.append(name)
random.shuffle(Colors)
# draw blank lines
# lines to down
for i in range(1, n+1, 1):
for j in range(1, n, 1):
draw.line((i*150+20, j*150+20, i*150+20, j*150+170), fill = 'black', width = 5)
# lines to right
for i in range(1, n, 1):
for j in range(1, n+1, 1):
draw.line((i*150+20, j*150+20, i*150+170, j*150+20), fill = 'black', width = 5)
for i in range(len(Lines)):
line = Lines[i]
arr = [int(x) for x in line.split()]
pathlen = arr[0]
color = Colors[i % len(Colors)]
# draw source and sink
if (i >= n):
# x from 0 to n
y = arr[1]
x = arr[2]
draw.line((x*150-40, y*150+20, x*150+20, y*150+20), fill=color, width=12)
y = arr[len(arr)-2]
x = arr[len(arr)-1]
draw.line((x*150+20, y*150+20, x*150+80, y*150+20), fill=color, width=12)
else:
# y from 0 to n
y = arr[1]
x = arr[2]
draw.line((x*150+20, y*150-40, x*150+20, y*150+20), fill=color, width=12)
y = arr[len(arr)-2]
x = arr[len(arr)-1]
draw.line((x*150+20, y*150+20, x*150+20, y*150+80), fill=color, width=12)
for k in range(3, len(arr), 2):
(y1, x1, y2, x2) = arr[k-2:k+2]
if (x1 > x2): (x1, y1, x2, y2) = (x2, y2, x1, y1)
elif (x1 == x2) and (y1 > y2): (x1, y1, x2, y2) = (x2, y2, x1, y1)
# check if set used
if ((x1, y1, x2, y2) in S):
old_color = Dict[(x1, y1, x2, y2)]
used = 1
else:
used = 0
S.add((x1, y1, x2, y2))
Dict[(x1, y1, x2, y2)] = color
# drawline
if (x1 == x2):
if (used):
draw.line((x1*150+26, y1*150+20, x2*150+26, y2*150+20), fill=old_color, width=12)
draw.line((x1*150+14, y1*150+20, x2*150+14, y2*150+20), fill=color, width=12)
else: draw.line((x1*150+20, y1*150+20, x2*150+20, y2*150+20), fill=color, width=12)
else:
if (used):
draw.line((x1*150+20, y1*150+26, x2*150+20, y2*150+26), fill=old_color, width=12)
draw.line((x1*150+20, y1*150+14, x2*150+20, y2*150+14), fill=color, width=12)
else: draw.line((x1*150+20, y1*150+20, x2*150+20, y2*150+20), fill=color, width=12)
# draw nodes
for i in range(1, n+1, 1):
for j in range(1, n+1, 1):
draw.ellipse((i*150, j*150, i*150+40, j*150+40), fill = 'white', outline = 'black', width = 5)
im.show()
im.save("problemF.png")






