


Previous article
Chapter 4. Fast algorithm for $$$\boxdot$$$ operator
We stopped at the point where we learned how to:
- Implement the $$$\boxdot$$$ operator in $$$O(N^3)$$$ time
- Use the $$$\boxdot$$$ operator for $$$O(N^2)$$$ time
I actually didn't introduce the name to avoid unnecessary scare, but the original paper calls this operator as unit-Monge matrix-matrix distance multiplication. Throughout the article, we will call it as the unit-Monge multiplication (of permutation) or just $$$\boxdot$$$ operator as we did before.
Let's see how to compute the $$$\boxdot$$$ operator in $$$O(N \log N)$$$ time. For a matrix $$$\Sigma(A), \Sigma(B)$$$ consider the partitioning $$$\Sigma(A) = [\Sigma(A)_{lo}, \Sigma(A)_{hi}], \Sigma(B) = \begin{bmatrix} \Sigma(B)_{lo} \newline \Sigma(B)_{hi} \end{bmatrix}$$$, where $$$lo$$$ denotes the first $$$N/2 + 1$$$ entries, and $$$hi$$$ denotes last $$$N/2$$$ entries. We assume $$$N$$$ to be even for a simpler description.
$$$\Sigma(A) \odot \Sigma(B)$$$ is a element-wise minimum of $$$\Sigma(A)_{lo} \odot \Sigma(B)_{lo}$$$ and $$$\Sigma(A)_{hi} \odot \Sigma(B)_{hi}$$$. Also, $$$\Sigma(\{A, B\})_{lo, hi}$$$ will roughly correspond to $$$\Sigma(\{A, B\}_{lo, hi})$$$ where
- $$$A_{lo}$$$ is the subpermutation of $$$A$$$ composed of elements in value range $$$[1, N/2]$$$
- $$$A_{hi}$$$ is the subpermutation of $$$A$$$ composed of elements in value range $$$[N/2+1, N]$$$
- $$$B_{lo}$$$ is the subpermutation of $$$B$$$ composed of elements in index range $$$[1, N/2]$$$
- $$$B_{hi}$$$ is the subpermutation of $$$B$$$ composed of elements in index range $$$[N/2+1, N]$$$
We will compute $$$A_{lo} \boxdot B_{lo}$$$, $$$A_{hi} \boxdot B_{hi}$$$ recursively, and use the result to compute $$$C = A \boxdot B$$$.
Let
- $$$M_{lo}(i, k) = \min_{j = 1}^{N/2 + 1} (\Sigma(A)(i, j) + \Sigma(B)(j, k))$$$
- $$$M_{hi}(i, k) = \min_{j = N/2+2}^{N + 1} (\Sigma(A)(i, j) + \Sigma(B)(j, k))$$$ Then as we've just observed, $$$\Sigma(C)(i, k) = \min(M_{lo}(i, k), M_{hi}(i, k))$$$.
We want to express $$$M_{lo}$$$ and $$$M_{hi}$$$ as $$$A_{lo} \boxdot B_{lo}$$$ and $$$A_{hi} \boxdot B_{hi}$$$, but they are not the same — in the end $$$M_{lo}$$$ is an $$$(N+1) \times (N+1)$$$ matrix while $$$A_{lo} \boxdot B_{lo}$$$ is an $$$(N/2+1) \times (N/2+1)$$$ matrix.
Representing $$$M_{lo}, M_{hi}$$$ as $$$C_{lo} = A_{lo} \boxdot B_{lo}$$$ and $$$C_{hi} = A_{hi} \boxdot B_{hi}$$$
We will assume
- $$$\Sigma(A_{lo})$$$ to be an $$$(N+1) \times (N/2+1)$$$ matrix defined in row/column index $$$[1, N+1] \times [1, N/2+1]$$$
- $$$\Sigma(A_{hi})$$$ to be an $$$(N+1) \times (N/2+1)$$$ matrix defined in row/column index $$$[1, N+1] \times [N/2+1, N+1]$$$
- $$$\Sigma(B_{lo})$$$ to be an $$$(N/2+1) \times (N+1)$$$ matrix defined in row/column index $$$[1, N/2+1] \times [1, N+1]$$$
- $$$\Sigma(B_{hi})$$$ to be an $$$(N/2+1) \times (N+1)$$$ matrix defined in row/column index $$$[N/2+1, N+1] \times [1, N+1]$$$
Note that $$$N/2+1$$$ rows are extended to $$$N + 1$$$ rows by copying values from the downward rows, and ditto for columns.
What we have is:
- $$$\Sigma(A)_{lo}(i, j) = \Sigma(A_{lo})(i, j)$$$
- $$$\Sigma(A)_{hi}(i, j) = \Sigma(A_{hi})(i, j) + \Sigma(A_{lo})(i, N/2 + 1)$$$
- $$$\Sigma(B)_{hi}(i, j) = \Sigma(B_{hi})(i, j)$$$
- $$$\Sigma(B)_{lo}(i, j) = \Sigma(B_{lo})(i, j) + \Sigma(B_{hi})(N/2+1, j)$$$
Good, let's write down:
- $$$M_{lo}(i, k) = \min_{j = 1}^{N/2 + 1} (\Sigma(A_{lo})(i, j) + \Sigma(B_{lo})(j, k) + \Sigma(B_{hi})(N/2+1, k))$$$
- $$$M_{hi}(i, k) = \min_{j = 1}^{N/2 + 1} (\Sigma(A_{hi})(i, j) + \Sigma(A_{lo})(i, N/2+1) + \Sigma(B_{hi})(j, k))$$$
We know $$$C_{lo} = A_{lo} \boxdot B_{lo}$$$ and $$$C_{hi} = A_{hi} \boxdot B_{hi}$$$, why don't we use it?
- $$$M_{lo}(i, k) = \Sigma(C_{lo})(i, k) + \Sigma(B_{hi})(N/2+1, k)$$$
- $$$M_{hi}(i, k) =\Sigma(C_{hi})(i, k) + \Sigma(A_{lo})(i, N/2+1)$$$ (Note that we consider $$$C_{lo}, C_{hi}$$$ as $$$(N+1) \times (N+1)$$$ matrix)
We again, consider the derivatives, and simplify:
- $$$M_{lo}(i, k) = \Sigma(C_{lo})(i, k) + \Sigma(C_{hi})(1, k)$$$
- $$$M_{hi}(i, k) =\Sigma(C_{hi})(i, k) + \Sigma(C_{lo})(i, N + 1)$$$
Good, now we represented $$$M_{lo}$$$ and $$$M_{hi}$$$ in terms of $$$C_{lo}$$$ and $$$C_{hi}$$$.
Recovering $$$C$$$ from $$$C_{lo}, C_{hi}$$$
To evaluate $$$C$$$ where $$$\Sigma(C)(i, k) = \min(M_{lo}(i, k), M_{hi}(i, k))$$$, it will be helpful to characterize the position where $$$M_{lo}(i, k) - M_{hi}(i, k) \geq 0$$$. Let's denote this quantity as $$$\delta(i, k) = M_{lo}(i, k) - M_{hi}(i, k)$$$, we can see
- $$$\delta(i, k)= \Sigma(C_{lo})(i, k) - \Sigma(C_{lo})(i, N + 1) + \Sigma(C_{hi})(1, k) - \Sigma(C_{hi})(i, k)$$$
- $$$\delta(i, k) = |\{x | 1 \le x \le i - 1, 1 \le C_{hi}[x] \le k - 1\}| - |\{x | i \le x \le N, k \le C_{lo}[x] \le N\}|$$$
Observe that the function is nondecreasing for both $$$i, k$$$. More specifically, since all values $$$C_{hi} \cup C_{lo}$$$ are distinct, we have
- $$$0 \leq \delta(i, k+1) - \delta(i, k) \leq 1$$$
- $$$0 \leq \delta(i+1, k) - \delta(i, k) \leq 1$$$
If we characterize the cells where $$$\delta(i, k) < 0$$$ and $$$\delta(i, k) \geq 0$$$, the demarcation line will start from lower-left corner $$$(N+1, 1)$$$ to upper-right corner $$$(1, N+1)$$$. The difference of $$$\delta(i, k+1) - \delta(i, k)$$$ and $$$\delta(i-1, k) - \delta(i, k)$$$ can be computed in $$$O(1)$$$ time, so the demarcation line can be actually computed in $$$O(N)$$$ time with two pointers.
We want to find all points $$$(i, j)$$$ where $$$\Sigma(C)(i, j+1) - \Sigma(C)(i, j) - \Sigma(C)(i+1, j+1) + \Sigma(C)(i+1, j) = 1$$$. If such points in $$$C_{lo}$$$ and $$$C_{hi}$$$ is not near the demarcation line, we can simply use them. But if they are adjacent to the demarcation line, we may need some adjustment. Let's write it down and see what cases we actually have:
- Case 1. $$$\delta(i + 1, j +1) \le 0$$$: In this case, all corners use the value from $$$M_{lo}$$$ and hence the point in $$$C_{lo}$$$ is preserved: If there is a point $$$(i, j) \in C_{lo}$$$, we can use it.
- Case 2. $$$\delta(i, j) \geq 0$$$: In this case, all corners use the value from $$$M_{hi}$$$ and hence the point in $$$C_{hi}$$$ is preserved: If there is a point $$$(i, j) \in C_{hi}$$$, we can use it.
- Case 3. None of the above: For this to hold, we need $$$\delta(i, j) = -1, \delta(i, j+1) = \delta(i+1, j) = 0, \delta(i+1, j+1) = 1$$$. I'm omitting the proof, but you can show that $$$(i, j)$$$ is always included in $$$C$$$.
Note that the points in $$$C_{lo}$$$ and $$$C_{hi}$$$ are distinct per their $$$x$$$-coordinate and $$$y$$$-coordinate, therefore you can set $$$C$$$ as the union of $$$C_{lo}$$$, $$$C_{hi}$$$ and overwrite in the position where the Case 3 holds. This can be done by simply moving through the demarcation line, and checking the Case 3 condition whenever its necessary.
As a result, we obtain an $$$O(N)$$$ algorithm to obtain $$$A \boxdot B$$$ from $$$A_{lo} \boxdot B_{lo}$$$ and $$$A_{hi} \boxdot B_{hi}$$$, hence the total algorithm runs in $$$T(N) = O(N) + 2T(N/2)$$$ time.
I tried to implement the above algorithm and I think I got a pretty short and nice code. However, when I tried to obtain an actual seaweed matrix, I found that my code was about 5x slower than the fastest one (by noshi91) on the internet. The difference between my code and the fastest one seems to come from memory management — I declare lots of vectors in recursion, whereas the fastest one allocates $$$O(n)$$$ pool and use everything from there. I decided to not bother myself and just copy-paste it :) You can test your implementation in LibreOJ. 单位蒙日矩阵乘法. Here is my final submission.
Chapter 5. Using the $$$\boxdot$$$ operator to obtain the seaweed matrix
Now we know how to implement the $$$\boxdot$$$ operator, and we know how to solve the Range LIS problem with $$$O(N^2)$$$ application of $$$\boxdot$$$, therefore we obtain an $$$O(N^3 \log N)$$$ algorithm. This is bad, but actually, it's pretty obvious to solve the Range LIS problem with $$$N$$$ application of $$$\boxdot$$$: Observe that, instead of creating a permutation for each entry, we can simply create a permutation for each row of seaweed matrix:
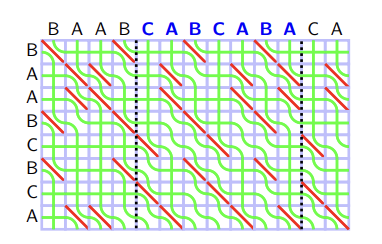
Therefore we have an $$$O(N^2 \log N)$$$ algorithm, but we still need more work. Hopefully, this isn't as complicated as our previous steps.
We will use divide and conquer. Consider the function $$$f(A)$$$ that returns the result of the seaweed matrix for a permutation $$$A$$$. Let $$$A_{lo}$$$ be a subpermutation consisted of numbers in $$$[1, N/2]$$$ and $$$A_{hi}$$$ as numbers in $$$[N/2+1, N]$$$. Our strategy is to compute the seaweed matrix $$$f(A_{lo})$$$ and $$$f(A_{hi})$$$ for each half of the permutation and combine it. We know how to combine the seaweed matrix with $$$\boxdot$$$, but the seaweed matrix from each subpermutation has missing columns.
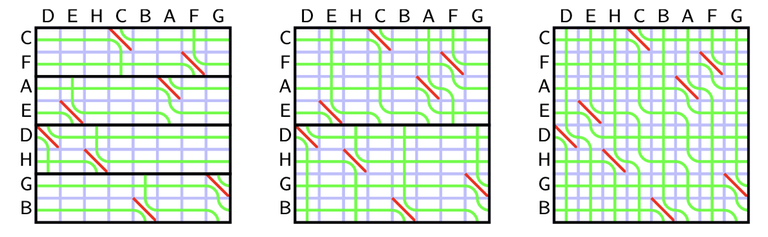 Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.
Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.
Extensions can be computed in $$$O(N)$$$ time and multiplication can be computed in $$$O(N \log N)$$$ time, hence $$$T(N) = 2T(N/2) + O(N \log N) = O(N \log^2 N)$$$. Hooray! we now know how to compute the Range LIS in $$$O(N \log^2 N)$$$. Here is my code which contains all of the contents above.
Chapter 6. Using the seaweed to solve the problem
We obtained the seaweed matrix of a permutation in $$$O(N \log^2 N)$$$, so it is trivial to compute the range LIS of a permutation.
Problem: Range LIS. Given an permutation $$$A$$$ and $$$Q$$$ queries $$$(l, r)$$$, compute the LIS of $$$A[l], A[l + 1], \ldots, A[r]$$$.
Solution. Compute a seaweed matrix of $$$A$$$ in $$$O(N \log^2 N)$$$. As observed in Chapter 1, the length of LIS is the number of seaweeds with index at most $$$l + N - 1$$$ which arrived to $$$[l, r]$$$. The seaweeds that can arrive to $$$[l, r]$$$ has index at most $$$r + N$$$, so we can instead compute the seaweed from range $$$[l+N, r+N]$$$ that arrives to $$$[l, r]$$$, and subtract the quantity from $$$r - l + 1$$$.
In other words, the size of LIS equals to $$$r - l + 1$$$ minus the number of seaweeds that starts from the upper edge of dotted box and ends in the lower edge of dotted box. This is a 2D query, and can be computed with sweeping and Fenwick trees.
We can compute other nontrivial quantities as well.
Problem: Prefix-Suffix LIS. Given a permutation $$$A$$$ and $$$Q$$$ queries $$$(l, r)$$$, compute the LIS of $$$A[1], \ldots, A[l]$$$ where every elements have value at least $$$r$$$.
Solution. We want to compute the number of seaweeds that starts from the upper edge of box $$$[r, N] \times [1, l]$$$ and ends in the lower edge (such box is in the bottom-left position). Seaweeds that passes the upper edge of box will start in range $$$[N - r + 1, N + l]$$$. Therefore we also obtain a similar 2D query and it can also be solved with Fenwick trees. Note that same strategy works for Suffix-Prefix LIS as well (Prefix-Prefix or Suffix-Suffix are just trivial).
The second problem is interesting, since it can be used to solve a well-known problem in a more efficient way.
Problem: Maximum Clique in a circle graph. Given $$$n$$$ chords in a circle where each endpoints are distinct, compute the maximum size subset of chords, where each pair of chords intersect each other. Each endpoint of chords are labeled with distinct integers from $$$[1, 2n]$$$, where labels are in circular order.
Solution. We will denote "left endpoint" as a endpoint with smaller label, and "right endpoint" similarly. In an optimal solution, there exists some chord which its left endpoint has smallest label. Let $$$c = (s, e)$$$ be such a chord. If we fix such chord $$$c$$$, the remaining chords should cross $$$c$$$, and each intersecting chords should cross each other: For two chord $$$p = (l_1, r_1), q = (l_2, r_2)$$$, if $$$l_1 < l_2$$$ then $$$r_1 < r_2$$$. Let $$$A[x]$$$ be the opposite endpoint of chord incident to endpoint $$$x$$$. The above observation summarizes to the following: For all $$$x < A[x]$$$, compute the LIS of $$$A[x], A[x + 1], \ldots, A[A[x] - 1]$$$ where every elements have value at least $$$A[x]$$$. This is hard, but indeed it does not hurt to compute the LIS of $$$A[1], A[2], \ldots, A[A[x] - 1]$$$ where every elements have value at least $$$A[x]$$$: the LIS gives the valid clique anyway. Now the problem is exactly the prefix-suffix LIS and can be solved in $$$O(N \log^2 N)$$$ time, where the naive algorithm uses $$$O(N^2 \log N)$$$ time.
Practice problems
- LibreOJ. 单位蒙日矩阵乘法
- Yosupo Judge. Static Range LIS Query
- Ptz Winter 2014. Circle Clique (solve it in $$$O(n \log^2 n)$$$!)
- Ptz Summer 2018. Form the Maximal Set (solve it in $$$O(n \log^2 n)$$$!)
- BOJ 26164. 싱싱미역







Why didn't you cite the paper where the idea and the pictures were taken from?
They kinda did in Part 1, Chapter 1.
edit : ok there where even more papers to it, my bad
https://arxiv.org/abs/0707.3619
Links are added to post.