


Happy Children's Day everyone. What should you do to celebrate the special holiday?
Of course, another Codeforces Round is your best choice!
There is a child who is our friend. Now he has faced a lot of algorithm problem, could you please help him?

We invite you to participate in Codeforces Round #250, which will take place at 17:00 MSK on 6.1 — Children's Day. This round will be held in both divisions.
Note that the starting time of this round is quite unusual.Why? Because it's yet another CF Round held by Chinese! We prepared many interesting problems for you.
Are you getting excited? Don't miss this round!
The problems were prepared by delayyy, Picks and me. This is our first Codeforces round~~~~.
Many thanks to Gerald, who gave us enormous help during the preparations for this round; to ftiasch, Kissshot and jqdai0815, who are the testers of this round; and to MikeMirzayanov, who created such a wonderful platform.
In Div. 1, scores for each problem will be 500-1000-1500-2000-3000.
In Div. 2, scores for each problem will be 500-1500-1500-2000-2500.
Look! Your high rating is waiting for you! What are you waiting for?
Just participate in this contest and write code fast and nicely, and you will take the high rating home!
Good luck and have fun!
UPD: The contest is over! Congratulations to winners!
Top 5 of Div. 1:
Top 5 of Div. 2:
Unfortunately, no one has solved the problem E in both divisions. What a sad story.... 
Editorial for the round will be added soon.
UPD2: Editorial for the round can be found here: Editorial






cin >> A long long time ago, there is a child who is our friend.
cout << A long long time ago, there was a child who was our friend.
/* UPD: Thanks for the Round :).
Good luck and have fun all */
It's my fault.I have removed the stupid "a long long time ago". Oh, my poor English……
i am reminded of this comment
You have a good sense of humor. I believe this round will be very wonderful :)
So fast announcement of the score distribution!
"Just participate in this contest and write code fast and nicely, and you will take the high rating home!"
I'm sure about that. lol
Happy to see a new template for the round announcement instead of those formal templates with the same sentences (only changing the numbers) used for the last rounds! This round seems special. Everything is new... Wish luck for everyone!
quite looking forward to this round.
Problem E 3000...I guess it must be very hard
Maybe you're right!~ Maybe not~
What a very clever guess!!! you must be genius!!
I did the same guess! I must be genius!!
that was an understatement. not even a single Pretests passed!
Why understatement? More like usual Chinese round :D
Chinese Div 1 E problems with wealth 3000 are usually very hard. Let's see who will solve it..
I'm curious about it, too.
lol.
Maybe is a child
A child can do any thing including solving E!~
I think Chinese Div 1 D problem is also very hard..
This time may not.
haha u were right! D was easier than C today! :)
Because I set D. :)
Is picks a person?
ammm... Maybe he is.
broken voice!
and maybe he is not! :D
What about Russian language?
what about the russian language? nowhere in the blog is it mentioned that the problem statements will be in chinese.
We would like to add Chinese language but it seems to need a big change to the website. Maybe we should advise Mike to add Chinese to codeforces? Lots of Chinese participants will be very happy for that.
Such a request should probably already include one qualified translation of the page :D
Yeah. So i said it needs a big change to the website. Whatever, I'm looking forward to it.
CodeChef now supports both Russian and Mandarin Chinese translations of English problems (MinakoKojima and gediiiiiii are usually the Mandarin translators).
maybe Chinese language will be added to Codeforces soon. :)
Looking forward to it.
Five years past, We Chinese are able to understand the English, and I like English so much!
Unleash the child coder within
Today is my first Children's Day after my 18th birthday. I'm looking forward to having a memorable contest. Thank you very much. Good luck.
Wow, a typical Chinese style announcement. LOL
I think this announcement is very nice :) It seems it will be a funny round.
A contest on my birthday :D Thank you very much. Good luck.
Happy birthday :D
Thanks :D
No Chinese Discription.....Sad....
click zan
a 3000 E …… no one can solve Chinese's E until……
Not exactly right
There was some people solve E in WJMZBMR's round & cgy4ever's round
though even tourist can't solve WJMZBMR's div2 E :P
@toursit
Click ZAN
I hope i do something better this time...All the best to everyone :)
Obviously, the problem E is going to be a good surprise :D
vfleaking is good at I think problem E can't be solved by Ordinary people 。。
i thing it does not connect!
"Happy Children's Day everyone. What should you do to celebrate the special holiday?
Of course, another Codeforces Round is your best choice!"
Problem E 3000 again... just can't imagine how hard it can be :p The same as last chinese round
My previous contest was good bye 2013. After a long time I registered today again. Then what do I see? Chinese problem setter with 3000 pointer E!! Perhaps I should postpone my first contest of 2014 till "Good Bye 2014" :p
Not like you have to solve E... not like anyone will solve E...
True. I barely passed the pretest for A. Definitely going down today.
me too... going down consecutively for the 4th time :(
Can I upvote twice? Or thrice? Please?
As far as I know, you cannot. Sorry :)
.
I'm probably going to kill the problemsetter if in Div1 250C the 6th pretest (the one almost everyone has failed in their first submission) has multiple copies of the same vertex.
I do really hope that there is another reason for my solution failing it... :D
Come on, that test wasn't so bad... pretests 5 and 9 were equally [sarcasm]user-friendly[/sarcasm]
I'm guessing more like tricky situations with diagonals inside/outside the polygon with multiple collinear vertices — the standard geometric axe
Oops I gave you -1. [truth] I wanted to give +. Liked that [sarcasm] [/sarcasm] [/truth]
Maybe collinear segments? It took me more than one hour to find this... So bad that I didn't have it in my library ; d.
A Google search on mysterious number 998244353 leads to integer FFT, maybe that's a hint to problem E, but I can't got any idea.
That'd be finally one nice modulo that allows it. It's annoying that you can't do FFT with the most common ones, 109 + 7 and 109 + 9...
That's quite possible. Note that if we were to count number of directed paths (let's say, there can be no left children), our answer would be the coefficients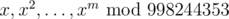 of the following polynomial:
of the following polynomial:
(it's easy to see if you know anything about generating functions). However, at the moment I have no idea how to generalize it to count number of trees... ;)
Okay, so let's define the generating function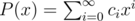 as follows: there are ci good binary trees of weight i. Then P(x) satisfies
as follows: there are ci good binary trees of weight i. Then P(x) satisfies
Explanation: every tree is either a "dead end" ("empty set"); this is this 'one' in the equation or a vertex having one of the weights: c1, ..., cn and two subtrees (maybe non-existent). Of course, each of the subtrees can be described by the same generating function P(x). That's why we have the second addend.
However, I have no idea how to compute P(x) fast (even the m lowest coefficients)...
Square root of polynomials is the solutiin. However, to let it easier, we let divide and conquer + FFT pass it, even though the only person who do this got TLE with some reason...
How to calculate the square root of polynomial fast?
In problem E answer is the same row, but with catalanian numbers as a coefficients
how to solve Div-1 B?
i used maximum spanning tree and disjoint set.
cost for each edge between U and V is min(animal[U], animal[v]) .
Then...How to get the answer in this way? I'm afraid I still don't know what to do next.
while you build maximum spanning tree you can calculate the answer. when you add edge U-V the number of ways use this edge is ( number of nodes are reachable nodes from U in spanning tree before adding U-V) * (number of reachable nodes from V in spanning tree before adding U-V) so ans+=(cnt[U]*cnt[V])*Cost[U-V], and then you add U-V to the maximum spanning tree with updating disjoint set (like Kruskal algorithm).
I used a Union-Find approach, where you add the nodes from largest value to smallest value. Then think about what happens when you add a new node — all nodes that are not yet connected must use a node that is at least this low. It then comes down to combining multiple adjacent components of already added nodes, think about this and you will figure it out (it`s simply multiplying the sizes together with the current node value).
Not sure if this is intendend solution or even passes systest, but it worked on pretests.
Srsly, D... I wonder how many people had the same trololo solution as me: keep an interval tree that allows operation 3 and is able to find the largest number in a given interval along with its position; when performing operation 2, just keep taking out the largest number and moduling it until there are no numbers ≥ x; sums are then handled by a Fenwick tree.
I have a nice proof of why it works: consider a number a and applying a = an = a%x on it for various x. If such an operation had any effect, then either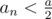 or the next modulo that has any effect is
or the next modulo that has any effect is 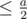 , or it's
, or it's 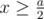 . In the second case,
. In the second case, 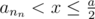 , and in the third,
, and in the third, 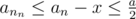 . We can see that after 2 modulos do something, a must decrease at least 2 times, which can only repeat
. We can see that after 2 modulos do something, a must decrease at least 2 times, which can only repeat 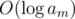 times. Therefore, the total number of actions for all operations of type 2 is
times. Therefore, the total number of actions for all operations of type 2 is 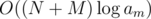 and with
and with 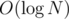 lookup and related updates, plus the cost of processing the other queries, gives total time complexity
lookup and related updates, plus the cost of processing the other queries, gives total time complexity 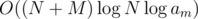 . WIN!
. WIN!
It's quite right. You can think about how to solve it when operation 3 is segment modify.
i don't know way My Solution got TLE, for operation of type 2 i update an interval if maximum number in this interval is >mod.
Updates all numbers in the interval or just the ones that are actually larger? It's a huge difference in complexity.
it's a segment tree, if int an interval C , node[C].max<=mod then i return other wise i process this interval with calling upd(i*2), upd(i*2+1), i think this should update only bigger number ans skip the other ones.
Sounds like it should work, maybe it's just a problem with constant factors.
maybe, that's disappointing :(
Looking at your code's times: or maybe an unlucky infinite loop. Or I'm wrong and it's really too slow, maybe by little and there's an evil test. Who knows...
There is bug in function updmod:
nd[i].m=x;oh, that was a stupid bug ! :(( thanks
Try this:
i got it, thanks. i should be more careful next time
Same as your solution, but I used a division into sqrt(N) blocks instead of a segment tree (and for each block I maintained a multiset with the sorted elements, in order to easily update only the needed numbers at each modulo operation). I was very reluctant to implement this and I thought quite a long time about how I could "compose" two modulo operations, but after not finding any way of efficiently composing them, I implemented this just in case :) Still, it could have TLE'ed, because of the sqrt(N) factor (compared to only a log(N) factor in the segment tree solution), but it didn't.
I guess it would me more correct to put Div2 C problem worth 1000 points.
The solution was quite easy, but realizing it wasn't (in my opinion).
In my opinion realizing this problem was very easy. Here is my code. 6772286
Please, what is the proof behind your solution?
proof explained here
thanks!
I am really surprised by the elegant solution for Div 1 A ( min of each end of an edge ). It's like instead of removing the nodes, we were just cutting the ropes.
So was I. That's really an awesome solution!
you say Div2 B?
Div1 A = Div2 C.
Thanks, I'm glad you like it >_< .
BTW is vfk some kind of abbreviation of vfleaking?
Yes! You find it! :)
You got it! =w=
I can't figure it out why this solution get write answer ? can you explain more please
How to prove it?
forthright48's and following idea are same ideas, but idea below is more intuitive I think:
Idea:
First choose the toy with maximum vi, and remove it. Now remove toy next with maximum vi (if it has any adjacent rope, of course). And so on.
proof explained here
At the start I opened Div1 problems instead of Div2 and thought the problems look much tougher than the usual rounds. So I checked the dashboard and found 230 people had already solved A(Div2 C) so I decidded to manage it somehow and started working on it. I got the idea in a few minutes and thanks to my poor internet connection after reconnecting 2-3 times when I finally tried to submit it showed "You must be registered to submit" error. Only then did realize my mistake and finally solved my first problem C in contest time. :D Earlier I did not even read problems beyond B because I thought they are too hard for me. But after this I think I will atleast read all problems after solving A and B.
Sometimes C is much easier than B!
Yeah this was one of those occasions. I couldn't solve B.
That is a great story, congratulations! Sometimes the biggest obstacle is the belief “This problem must be too hard for me.”
Prob C Div2 which is Prob A div 1 is it a greedy or DP problem ?
It's a "don't think hard, think smart" problem. Read the comments above before asking.
As I thought (it might be wrong), we can add to sum minimal cost of line from a to b or from b to a for every line.
Greedy.
do u mean remove the nodes in decreasing order of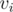 ? if so, can u give a proof for this?
? if so, can u give a proof for this?
i couldn't prove it during contest, so i just checked that it worked for all sample cases (and 2 more of my own), and implemented it!
Yup, remove the vertices in decreasing order of vi. It's obvious that you can do it, and that this way, each edge will be removed exactly once, adding cost vi to the total. Also, when an edge is removed, it adds to the total cost v of one of its endpoints, so this greedy gives the total cost equal to this lower bound.
will, can you please explain this case
My name isn't Will :D
We have 4 parts connected to a central one. Removing each of those 4 parts costs us 10, and that's what we get when taking min(v1,vx) for x=2,3,4,5.
I know i meant the word will :3
thank you for explanation, im convinced now :D
When we remove vertex i, we get a cost from vertex j (namely vj). Assign this cost to the edge ij. Then the total cost required is the sum of costs of all edges.
Note that each edge is only counted once (when removing one of its endpoints; removing any other vertex doesn't affect this, and removing the second endpoint has no effect as the first endpoint has gone), and its value is the cost of one of its two endpoints. Thus we minimize the total cost by minimizing the costs of all edges, namely by choosing the smaller cost for each edge.
When we remove the nodes in decreasing order of vi, we always assign the smaller cost to each edge. Suppose for edge ij, we assign the value vj, but vi < vj. Then we should have removed vertex j first and assigned the value vi to the edge, contradiction. Thus we have assigned the smaller cost to every edge, and thus we have obtained the smallest total cost.
Nice explanation. I also couldn't proof it during contest.
nice proof. thanks a lot! :)
I tried to find the i-th node having the minimum sum of energy of its connected j-nodes and removed the i-th node iteratively. I was wrong hoping that greedy approach would work here :( I did not think that removing minimum sum cost of connected node can have its own energy values too high and thus increasing the total cost. Still I understood my mistake and i hope i don't commit this mistake again
The solution is actually greedy, but in a different greedy way (take the vertex with the largest cost every time).
Your solution fails for the following:
A vertex with cost 3 is connected to two vertices with cost 2.
Your solution dictates that as both of the cost-2 vertices have lower minimum sum of costs (namely 3) as opposed to the cost-3 one (namely 2 + 2 = 4), you remove one of them first. This way you get an answer of 5, while the optimal solution is 4 (remove the cost-3 vertex first).
Hi setters, I really like at least those problems I had a chance to read — A, B, C, D in DIV2, thanks ;-)
Any hint for task D div2?
DSU. Kruskal's algorithm.
It's not the Kruskal algorithm in fact. It just uses disjoint set union.
Mmm, in my solution in the end I have maximum spanning tree so I think it can be called Kruskal algorithm.
Well, I'm sorry then. In my solution I do not use Kruskal's algorithm at all.
Oh, no problem. I think ideas of all solutions are the same and having Kruskal or not is just question of implementation.
At first, I didn't know how to solve A and got WA twice. Then, I checked Status and noticed that the memory usage of those who passed pretests was too low. I realized that I didn't have to make an adjacency matrix XD
Nice round. It seems that the ones who predicted there won't be any accepted solution to E where right. I want to ask what are some good materials on FFT (because Wikipedia gives a lot of probably interesting stuff, but they seem too mathy to apply in any programming contest task). Thanks in advance.
"Introduction to Algorithms".
hacking at DIV2 was like hell :D pretty contest,thanks vfleaking
i only wish Div-1 also had more hacking opportunities!
other than that, it was a great round! keep it up vfleaking! :)
I think that the test cases for Div1D are weak because many users get accepted solutions using O(NlogN) for operations type 2. For example Petr solution: 6770456
It's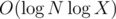 in average, because each number X can be decreased with operation Mod only
in average, because each number X can be decreased with operation Mod only 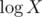 times.
times.
I explain it here
consider this test case
N = M = 10^5
all elements a[i]=10^9
all querys of type 2
1st — [1 N] x=10^9 — 1
2st — [1 N] x=10^9 — 2
3st — [1 N] x=10^9 — 3
..
what is the complexity for this test case?
LOL, after the first query all numbers will become 1's, so other ones will be processed in O(1) time.
the time limit is 4 secs. And it is not O(nlogn) for operations type 2. When the maximum of an interval is smaller than the mod number, this interval can be skipped, because x%m=x, when x<m. Then if x>=m,we can get x%m<m, so the number decrease very fast.
That's because a number won't be done modulo operation efficaciously too many times.
Solution of 1D works in O(MlogNlogMAX) , we can use potential method to prove it. Let's assign the potential of number P be logP, then if that number is changed by operation 2 its potential decreases at least 1. And then build an interval tree which supports dynamic RMQ problem, and while working on operation type 2 first check if the maximum element in range(l,r) >= M, then process it on that number, until such number doesn't exist in asked range.
We can see that:
Initially: the potential of the sequence <= NlogMAX
Operation 1: costs O(logN) time, and potential doesn't change. Amortized complexity = O(logN).
Operation 3: costs O(logN) time, and potential increases at most logMAX, as we need O(logN) time to clear 1 unit of potential, amortized complexity is O(logN + logNlogMAX).
Operation 2: We need O(logN) time to check the maximum <= M, and because the time to clear potential is included in operation 3, this is not counted in total time.
Summing up all these cases gives us O(MlogNlogMAX) total time complexity
Мне неясно почему в задаче A DIV.2 в 28 тесте ответ С, а не A?
Два хороших ответа: A и D. Значит, мальчик выберет ответ C
1 по крайней мере в 2 раза меньше и 2, и 4, и 8
А 8 по крайней мере в 2 раза больше и 1, и 2, и 4
could both write in english for everyone understand? or translate in google like me
It's because hball1st forgot to check Russian language when writing the comment.
hball1st: Why in Div2 A "C" is answer to 28-th test, but not "A"?
me: Two good answers A and D. So, boy will choose answer C
1 is at least 2 times less than 2, 4, 8
And 8 is at least 2 times greater than 1, 2, 4
Google translation is convenient...but the result may be strange for understand....
Потому что D длиннее всех остальных вариантов как минимум в два раза, а значит у нас есть два хороших варианта, в таком случае мы должны выбрать С. upd: не заметил ответ выше :)
answer D and A satisfy the conditions
in this case you should print C
BOOOOOOOP!
I just found out what my WA in div1 B was about. I forgot to add
1LL*once...Perhaps you won't forget it any more~ XD~
I doubt it. It isn't really forgetting, just that I don't write it even if I realize that it should be there, and don't notice it. I don't really have time to check my code line by line and compare it with my idea of the algorithm.
when it comes to this kind of problem, especially in the problem there is a sentence like "please use 64-bit....." I always declare all the variable as long long.....
It can still fail. Suppose that you're actually multiplying vector/string sizes — you'd still need to cast them, and if you're used to thinking "if I declare all as long long, then it's fine", you can fail in that case.
Everything can fail, especially if you just unexplainably don't write something.
I finish my div1D code at 1:59:59, and submit it...then unfortunately,out of time,just a second.... then after system test....I submit it again, accepted.what a sad story...
http://codeforces.com/blog/entry/8341#comment-140681 I know that pain :P
Problem Div1 C is similar to this problem Ears Cutting
I used a DP solution for DIV2 B to collect the sum which gave TLE at system test
and i thought of DIV2 C as a graph problem
I wasn't pretty sure about disconnecting the node which has a minimum-cost neighbors, maximum neighbors or the node which has maximum cost and none of them gave me optimal solution.
i'm going really down today but Great contest!.
Lesson learned, Never overestimate the problem!
Honestly speaking, I solved DIV2 C using greedy algorithm, which was really out of my expectation.
yes. i thought of every possible way to solve this problem except the greedy way! :D
How is your dp then? Actually using dp and simple backtrack can run in linear time, should be fast enough
Hi icalFikr, could you please explain the dp method? Thanks
I'm not pretty sure if its called DP or else
Suppose we have range
[0..X], we can make every number from 0 to X with lowbit of some elements from set S.If we add one more element from S, supposed to be M. We can update range become
[0 .. X + lowbit(M)], the proof is really easy. So, range[X + 1 .. X + lowbit(M)]can be arranged by M as last component.After we precalc last component for each X <= sum, we can backtrack the query and find all of components of sum.
Sorry for my bad english ^^
Here is my solution if you want to know more
please update the ratings soon
done
Very nice contest in this special day. Problems was very interesnting to solve, and the div 2 A problem was like a bomb for hacking. I want more contest from you vfleaking
подскажите почему в задаче А вот такой тест дает ответ А
сам тест
A.aaaa
B.aa
C.a
D.a
"Why the answer is A and not C?" -- Google Translate
C and D aren't great, because the 1-character C is not twice shorter than the 1-character D. However, if we modify the case:
Then yes, A and D are both great, and so the answer is C.
What is the complexity of optimal solution for Div2B?
O(Limit)
why have you added test case on div 2 B problem after the contest
the sad thing is that the only one who submit E problem got WR in testcase 15 :(
only one who
submittedpassed pretests :)im not convinced with the solution of problem C Div2 does any one has any proof for it ??
proof
Thanks :D
http://codeforces.com/blog/entry/12490#comment-172014
Thanks :D
my rating was not changed :D
u will find urself under Balance points in the round stats published by DmitriyH.
Round Stats
Wow, kids from China. such a great round!