


Hello everybody!
I just want to invite you to participate in Codeforces Round #261 (Div.2 only), which will be held on August 15th, 19:30MSK.
This round is prepared by ShayanH, Haghani and me. Special thanks to mruxim for helping us to prepare the problems. Actually, this is our first round and we hope you'll enjoy the contest.
Traditionally, we thank Gerald for helping us to get the contest prepared and also MikeMirzayanov, for the great Polygon system.
Main characters of our stories are two interesting persons, named "Pashmak" and "Parmida"; such a lovely couple! <3
Score distribution will be announced soon.
Have fun. ;)
UPD1: Dynamic scoring system will be used.
UPD2: We recommend you to read all problems, although they're sorted by their estimated difficulty.
UDP3: We also thank Aksenov239 who helped us a lot in fixing the Russian statements.
UDP4: It's over!
Congratulations to all people who solved the five problems.
These are the 7 top official contestants:
Editorial will be published soon.
UDP5: We're sorry for the delay. We put a brief editorial here.







Codeforces Round #260?
That was a mistake.
It seems that some time after Round #261 gets over, the World Finals of Code Jam 2014 will begin.
Link to live stream on YouTube
Right,the 2014 Code Jam World Finals will coming!On August 15th, the reigning champion, Ivan Miatselski (mystic), will make his return to the Finals to face off against the top 25 Code Jammers in Los Angeles.
click here for more information
wow :) iranian contest I love them :)
Great! Finally Div 2 comes. I'll try to use Java in this round. ..
hope for many hacks and no [pure] math :D
also for dp!!!
Hope for no hacks (strong pretest) and much [pure] math
Why would you hope for that
Well, they obviously love math, duh.
@above i know that. He's posted this in almost every recent contest thread.
But why strong pretests D:. Codeforces hacking is very fun.
i hate hacking ): I like contests like ICPC, where you know if your submission is right or wrong when you submit it.
Eh, well it is a matter of opinion. I personally believe that hacking creates more suspense, especially right after you try to hack someone.
Iranian contest :)
And better than this it's prepared by Allame Helli students :)
Wish luck for all participants :)
I also hope you'll not cheat again! Have you seen your other pupil and newbie accounts? Competing for RATING and CHEATING wont make you learn anything! I'm wondering how you got rank 20 div2 as a new account! :)
mobinTE
Mobin_Teymoori
Mobin_Teymoori
Mobint3ymoori
mr.mobin
mobinTEY
mobin2000
mobin_t
I think he did not find a new combination for his name and just created this new account Mobin-Teymoori! :)
!
At leas i don't cheat like you by taking rank 20 div 2! You are ruining the true ranking. I don't think having 8 accounts is a good idea!
If you pay attention to the second one, you'll see i'm competing all of my contests with it (22 until now), and this account is just additional that i'm not using it anymore (look my last contest).
-
oha O_o mobin1,mobin2,mobin3...mobinN-1,mobinN
Koorosh_Ahmadi_deleted
DaneshvarA
deleted1
Waiting for a great contest from our friends! :)
It seems that I need another account..
why? for cheating?
Oh, sorry. I thought that only rating between 0 and 1699 can register. It's my fault.
q
We don't understand what your meaning,Please use English. :)
Please don't bomb us
:|
a
Nice couple =)) Parmida & Pashmak :D
kind of ironic that i missed this round due to attending a friend's marriage. :)
Another contest another new things to Learn wow!!!! Thanx codeforces :)
Can't wait to meet. Pashmak and Parmida. Hope the couples are really nice with their problems need dp,math and maybe geometry.
just god knows who is Pashmak! somebody with a lot of short pashms? :D
Pashmak = matrix :D
this pashmak or another pashmak?
give me "-" pls
Today is the Independence Day in India!
Wish all Indians a good luck.
Give your best today!
Jai Hind
I could never understand ethnic of national pride. Because to me pride should be reserved for
something you achieve or attain on your own, not something that happens by accident of birth.
Being Irish isn't a skill, it's a fuckin' genetic accident. You wouldn't say "I'm proud to be 5'1 1. I'm proud
to have a predisposition for colon cancer." So why the fuck would you be proud to be Irish, or proud to be Italian, or American or anything?
(c) George Carlin
Because maybe ethnic pride is not about oneself but about one's country. I think that "I'm proud to be an X", means that you like an X, you are proud of people of your country and you are happy that you are a member of this group. I don't know if it would be intelligent enough to interpret it as one's achievement :)
I don't understand why the yash gets so many negative votes. Usually, people tend to be individualists and they are not united enough. So the guy has the right values.
Likewise, I don't understand, why so obvious thought from quisorci gets so many positive votes. Moreover, swear words never strengthen ones position, I think :)
Feel free to downvote my comment, I don't care about the contribution at all :)
"I don't understand why..."
Hmm, because society just tired of this nonending "today is some religious(usually muslim) or national holiday, so I wish good luck for the next nations: ..." phrases. It seems little bit egoistic and unpleasant. Have you seen at least once smth like "today is an Orthodoxian holiday, so, do your best Russians"?
Nothing to add here. You've outlined all of my thoughts.
That's not the problem in their national pride, that's all I wanted to say. I agree with you as people from some regions tend to write about their holidays more and some others don't write at all.
I don't understand their feelings and most of their holidays, but I don't downvote (mainly because I don't understand it). For me, it is much more convenient just to skip them. I am not sure if he offends any other people with wishing good luck to Indians and expressing good feelings about oneself. If some people feel unpleasantly so aren't they egoistic too? :)
If you would like to know it, then you should explore about the Great Indian Freedom Struggle!
This day fills almost all of us with great positive energy to give our best!
I have changed the photo as it was causing unnecessary troubles. Frankly, I had not read that statement (of pride) seriously!
It had the map, the tricolour and the national anthem, so I posted it. Also, I had just taken the image from google and not MADE it.
hope short problem statement , short solutions , long editorial :)
That could also mean short but extremely hard solutions :D
UDP: an easy short solution :D
So, the problems would be so easy that ranking only stands on small bugs and time tiebreakers? Not very ideal either.
Be careful what you wish for :D
Hoping for the best problem set =)
Dynamic scoring will be used. The problems are gonna be ordered by their difficulty?
Added in post.
gl&&hf!
I know this is off topic question, but this guy FreezingCool has rating 1889 and he's not purple :-). Looks like an issue.
see his rating in the graph 1884 :D
strange, i see 1889...
UPD: ah, i saw it! looks like there is two "points" in graph, don't know..
see the graph :) 1884 but in profile is 1889 :D
i saw another example of this few days ago ... may be they want to change master rating in 1850-2050 :D
:D
Take a look at his contest list. It shows that he participated in both online and onsite version of MemSQL Start[c]UP 2.0:)
here is a screenshot of his Contests page. i think this is definitely an issue.
Too many registrants today...
4716registrants...I'm scared, as there may be
in queueproblem today... :(Soooooooooo many contestants that out-of-competition participants have to use 4-digit room number :p
Maybe it is a record high register number for a single division contest :p
Whee! Full score in half an hour!
Kinda easy, no?
UPD: Also, my room only has unofficial participants. Lolwut...
Problems are too easy. I will go to bed now.
Congratulations:)
It is div2 contest, it should be very easy. Maybe not so much as today, but generally it should:) And i don't understand authors who give for div2 rounds problems like 424E - Colored Jenga — it is not a div2 problem at all.
Room assigment is done this way to decrease your impact on div2 standings — i guess there will be almost nothing to hack for div2 users, if you'll add 2-3 red coders to div2 room.
Got My answer already... with losing Problem B......
Great contest! It was easy somehow (this is div2 it shouldn't be hard) , but it had so many good things by the way!
for example there existed a huge test in pretest that we don't get Run Error by getting max n , 10^5 or something like this! (I got runtime error during contest!)
also problem statements were so good and easy to understand!
A,B too easy! C,D too hard! :D
Hope there will be an complete editorial for the hard problems.
Thanks
Tremendous contest for division 2. Thanks to you, author, my depression is over :)
The easiest hack was for problem A. Half the people in my room that solved the problem didn't use if (abs(x2-x1) == abs(y2-y1), or some variant of that. They mostly used if (x2-x1 == y2-y1). Therefore, they could not pass the test case (x1==10, y1==-10, x2==-10, y2==10). x1-x2 would be -1 * y1 — y2. Therefore, they would output "-1" when there was an optimal solution. I got 500 points this way :)
I liked the contest and the difficulty was ok for div2. Also , very nice problem C. Congrats !
Very Weak Pretest !! I am really afraid about system testing !!
No! I believe that it was a really good pretest that is also open for hackers!
Nice contest (also the first time for me to pass pretests on all problems). For me C was the hardest problem in today's set. What made C so hard for me was realizing the proof that splitting the students in groups of ~(n/k) is optimal. Also liked D and E (don't really know why — maybe because I tried E in the past without success).
Double post, sorry (chrome ... )
How to solve C ?
there are K^D configuarations for any students becaue can choose any of the K busses on a given day and there are D days.
so if N > K^D , one these configs will repeat.return -1 if this is true.
Else think of how 4 digit binary no.s are arranged. - 0 0 0 0 - 0 0 0 1 - 0 0 1 0 - 0 0 1 1 - 0 1 0 0 - 0 1 0 1 - 0 1 1 0 - 0 1 1 1 - 1 0 0 0 - 1 0 0 1 - 1 0 1 0 - 1 0 1 1 - 1 1 0 0 - 1 1 0 1 - 1 1 1 0 - 1 1 1 1
Note that thse places are analogous to days in our question and value of these place will be between 1 to K instead of 0 to 1
Hope this helps.
In short, before the first day you have the group of n students, and every day you break every group of g>=2 students in min(g,k) new groups. If g <= k, then each student gets its own bus, otherwise the group is split into k new groups of about (g/k) students.
Okay, here's a full proof and stuffs. Shorter solutions are present above.
Claim: If n > kd, then there's no solution.
Proof: Induct on d. For d = 1, if n > k1 = k, then by Pigeonhole Principle, at least two students go to the same bus and they become good friends. Now suppose our claim is proven for d = i. To prove this for d = i + 1, we see that if we have n > ki + 1 students, by Pigeonhole Principle again ki + 1 students will go to the same bus on the first day, and we can invoke our induction hypothesis on these students for the remaining i days. Thus if n > kd, there's no solution.
Claim: If n ≤ kd, then there is a solution.
Observe all d-digit numbers in base k, including leading zeroes. (This means the numbers 000, 001, 010, 011, 100, 101, 110, 111 for k = 2, d = 3, and 00, 01, 02, 10, 11, 12, 20, 21, 22 for k = 3, d = 2, for example.) Since there are kd such numbers, we can assign each student to some number so no two students share a number. Now, on the i-th day, all students whose i-th digit (from either end, but let's suppose from the right) is j goes to bus j + 1. For example, with k = 2, d = 3, we have the students 000, 010, 100, 110 in bus 1 on day 1, and the students 010, 011, 110, 111 in bus 2 on day 2. This gives the required schedule.
Now our task is to implement the above.
Checking the first claim is simple; however, since kd can potentially go to (109)1000 = 109000 (over 9000...not), we need to handle some overflows. The easiest method is to declare a temporary variable tmp that is a 64-bit integer, initializing it to 1, then loop d times, multiplying k to tmp and comparing it with n. If after all d iterations we still have n > tmp, then there's no solution. Otherwise, at the first moment n ≤ tmp is true, the value of tmp is at most kn, since before this tmp < n is true and we multiply tmp by k. Since n ≤ 103, k ≤ 109, tmp ≤ kn ≤ 1012 fits in our 64-bit integer.
Now, after we check this, we can start constructing our numbers. We can check the i-th digit from the right of a number j in base k in a simple way: (j / ki - 1) % k, with / being truncated division and % being modulo. This is true since dividing by ki - 1 means we're removing the last i - 1 digits, which makes the unit digit to be the i-th digit originally, and "modulo-ing" by k means we throw away all digits except the unit digit, so now we have the i-th digit alone.
If we assign the numbers to the students consecutively starting from 00... 0 = 0, it becomes a simple iteration to find the bus numbers. For day i, iterate over j = 0, 1, ..., n - 1; find the i-th digit of j in base k, add by one (since the possible digits are from 0 to k - 1, but the buses are from 1 to k), and that's the bus number of the student.
Here's my solution in C++, which should be rather straightforward.
Or in a shorter way: each student is assigned a D-digit number in base K. If N > KD, then there's no solution based on the pigeonhole principle. Otherwise, assign decimal number i to student i and convert it to base K, which gives (+1) the i-th column of the answer.
Exactly; I just made it fully rigorous or something. I'm too immersed in math.
Its called the AoPS disease
Thanks !!! Now I understand .... The key point is I can assign any number among K^D different numbers , cause any two of them will contain at least one different digits , meaning different bus at some day.
Could you add more details please?
Seriously? chaotic_iak's long post above mine has more details, read that.
I've probably read you answer 20 times to get it, but finally I've made it. As for me, it's much easier to think about
k^dnumbers, takeNdistinct of them (if we actually can), represent them in baseKand this is our answer, now we just need to convert it to the printable result :-).Thank you, your post helped a lot.
Can you help me please to understand this line . " This is true since dividing by k^(i - 1) means we're removing the last i - 1 digits, which makes the unit digit to be the i-th digit originally, and "modulo-ing" by k means we throw away all digits except the unit digit, so now we have the i-th digit alone."
Sorry for my poor question...
one can also use DFS to solve this problem.
see my submission below for more information. The basic idea is to go through all permutations using for loops, and stopping when we have enough of them.
http://codeforces.com/contest/459/submission/7470821
How to solve D?
Something like this.
Wow, such a beauty one:)
What is this?
Is it C++ built in BIT???
:O
No, it is red-black tree implemented in SGI STL like set but with some additions. You can read more here.
If it is, then it is a slam dunk from I_love_Tanya_Romanova
just like I did — http://codeforces.com/contest/459/submission/7470554
first calculate l[i] = f(1,i,ai), r[i]=(i,n,ai); then you just need a BIT(binary indexed tree) to find the answer :)
How do you calculate l[i] and r[i] efficiently? Only way I can think of right now is to use a map to know the last position of each a[i]. Is it possible to calculate them in linear time?
unordered_map has amortized so you can do it in
so you can do it in 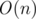 with it. But anyway you'll need
with it. But anyway you'll need  time to use BIT. Btw you don't need the last position as you can hold number of each a[i] in map[i].
time to use BIT. Btw you don't need the last position as you can hold number of each a[i] in map[i].
I used a manually coded hash table. It pretty much runs in amortized O(1) time because I don't add the same element multiple times. Also, you could use a segment tree for finding all 1<=i<j<=N for which l[i]>r[j], even without space compression.
Here is my code: 7477309
Thanks to you both. This helped
Another way to calculate l and r, is to have an array of pairs (a[i], i) and sort it. For each i, you do binary search to find the index of (a[i], i), the index of the first (a[i]) and the index of the last (a[i]), and calculate l[i] and r[i] based on that.
Yes, I saw this in some in solution However a simpler thing to do after sorting the pairs is to do 2 traversals with a counter that resets every time the a[i] changes. A traversal from 1 to n to calculate l[i] then from n to 1 to calculate r[i]
Nice observation! The other approach is overkill given this one.
Can you explain a bit more on how to use BIT here after computing L[i] and R[i]?
iterate over l[i] from n to 1 each time do { ans += query(l[i]); update(r[i]+1, 1); // add 1 to the position r[i]+1 in BIT } now think why it works...
I didn't come up with the BIT solution once you have l and r array. Instead I solved it using a Treap. Good to know there was a simpler way to solve it.
Power of Codeforces!!
I'm seeing about 50 submissions that are being judged simultaneously.....!
wow....thanks a lot MikeMirzayanov
I don't think "saying good things about Mr. mirzayanov" increases your contribution
although Codeforces is the fastest online judge
I think my contribution is high enough so I don't do something like this for increasing contribution.....
You should think about your contribution :P
you found this "HIGH CONTRIBUTION" of yours in the same way
it's the worst use of Codeforces blog
Alright girls, don't fight :D
Today AK is crazy
Wasted precious time in problem A!
I focussed on the boundary cases and later saw that p1 and p2 were in [-100,100] while p3 and p4 were in [-1000,1000]. I misread first as [-1000,1000]...
Also, very fast systest! (Remember last time)
Hahaha same here. I was fooled. But the big problem is that I spent on it lot of time to make a silly mistake at the end.
I tried to hack more solutions.At 9 of them I got this error: "FAIL Unexpected character #13, but ' ' expected (stdin) [validator Validator.exe returns exit code 3]" and invalid input.I really do not know why...the tests were like this: n 1 1 1 ... 1 I took care in don't having a space at the end of the string formed by 1.
I had the same problem.
Character #13 is carriage return. Looks like you put a new line while you should have put a space. Which problem are you trying to hack?
...actually, it's also possible that you're using Windows-style newline \r\n (or Mac?-style \r) while the validator expects Unix-style \n. Yeah, which problem are you trying to hack?
I tried to hack problem B. The following hack attempts 108706, 108803 weren't accepted.
I was trying to hack B and D and I'm using Windows.I tried all the posibilities(with space or '\n' at the end, etc)
Always this bug. sigh.
cout << ( (long long) (x * (x - 1) ) / 2 ) << endl;whats that?
A nasty bug called overflow :(
If you declare x as long long, then you'll not have this problem.
I know :( just a bug that happens everytime. It should be
((long long) x * (x - 1) ) / 2.If you use "#define int long long" these things never happends ... :)
If you use "#define int long long" you obfuscate your code and got a chance to have unexpected TLE or MLE.
I can't agree more!
Such a dirty thing!
This is good for noob (newbie) programmers!
I think it changes int main() to long long main() and causes an error. If you put the define inside the main function, It doesn't get any error.
I think you should use
1ll *instead of castingxto long long like that.Use x*1LL*(x-1)/2
problem B,if we use "int",it can be Multiplication overflow. TAT
I tried to hack a guy with that case in the last few seconds. Guess what I got ? An apache error :)
In A I hacked one solution by silly test "1 5 5 1" :|
I hacked 6 solution by 2 3 1 4 :D
Congratulations, azizkhan!
right, but even more congratulations to vanhanh.pham! :)
He has +317!
Submission 7474163, I've tested on my llvm-g++. While running the data "625 5 4", it did not output "-1", but the right answer. While running on Codeforces server, it returned Wrong Answer.
Could anyone tell me why it had happened?
Got AC by adding 1e-9
What was the tricky test for problem E?
Editorials?
I have a question that we always ask! :D
When are the ratings going to be updated?
why http://codeforces.com/contest/459/submission/7468758 got skipped???
This code submitted with another account too. So both of 'em got skipped.
Why everyone who tried to solve the problem C by FPC got a TLE on the testcase 9?
My java solution runs test 9 in 1.5 seconds... The time constraints seem a little harsh, especially when we are asked to print out as many as 1,000,000 ints on 1000 lines during that time.
yyfkiller3 registered 5 hours ago :(
Hopefully this is his real account
Problem E is almost the same as Codility's Magnesium 2014 challenge.
Wrong Answer: http://codeforces.com/contest/459/submission/7475559 Accepted: http://codeforces.com/contest/459/submission/7475581
Sorry guys, but it seems like a BUG in Codeforces. Those are the same, and there was no warning informing about the %ld issue (%Ld is also WA). I have no idea why this hasn't been fixed already, it has been around for a long time, but now Codeforces is not warning us about the replacement of %ld by %I64d anymore.
Thumbs down.
I believe that
$I64dand%lldmean the same thing now on CF, whereas%ldand%Ldare both wrong and there have never been any replacement warnings about them.%ldis forlong, but notlong longhi It's a very good contest.
I haven't seen theory of problem E ever.
Div.2 Problem B: http://codeforces.com/contest/459/submission/7476006 Why should the type of counter of flowers be long long? MAX_N = 10 ^ 5 which is integer. I saw many who solved this problem used long long instead of int. I got AC with that but I don't know why. Any help?
Yo can have, for example 10⁵ 3s, and 10⁵ 4s, so 10⁵ * 10⁵ = 10¹⁰, so you needed long long
The result (number of pairs) can be up to N*(N-1)/2
The counter of flowers don't need to be
long long, if you remember to cast the multiplicationit_min->second * it_max->secondtolong longfirst. If both variables areints, when you multiply the two, the result will still be anintand it might cause an overflow.After all, you can't do this to print 1018 due to overflow:
int a = 1000000000; cout << a*a;. The same reason with why you can't docout << it_min->second * it_max->second;without risking overflow.Ok but If I do this: cout << (long long) a*a; Does It cast the overflowed value?
So my question is: When does casting be enough and when does making "a" long long be a must?
cout << (long long) a*a;is enough, since the order is(long long) afirst, before multiplied witha, so the result is stored as along longand it won't overflow.Casting is enough if the variables don't overflow. For example, if
ais anint, as long as you don't put anything greater than the maximum capacity (usually 231 - 1) toait's enough. However, if you keep using(long long) a*a,(long long) a*b,(long long) a*BIG_NUMBEReverywhere, consider to as well setaaslong longto avoid casting all the time even if it doesn't store a large number. Faster (and cleaner) that way.Hello all, could anyone please help me why this code is TLE on tc 31? 7470052
I really don't have idea what I'm doing wrong here :(
dfsis called O(M) times:And it calls itself O(M) times:
You might want to rethink your algorithm.
doesn't even matter if dfs is called M or M*M times... 7476933 is O(M+N) and still TLEd (maybe because of recursion? idk)
PS: is it just me or codeforces is really slow nowadays? (except on contests)
I don't think it is.
dfsis called for each edge (u_i,v_i) and iterates through all edges that start at v_i. Therefore your algorithm runs in O(M^2+N).hm, you're right, i'm sorry
Who can explain me why in my solution http://codeforces.com/contest/459/submission/7464445 are wrong? On my own comp i have right answer on test #6 for this solution
Your code: else result =numb_min*(numb_min-1); Correct: else result =numb_min*(numb_min-1)/2; Just because pairs AB and BA are same pairs.
Hello! I want to ask you is that the correct solution for the fifth task. We can use dynamic programming and the state will be the current node and the weight of the last edge. But it uses too much memory. The maximum number of edges is only 30000. Moreover an edge has the information for the current node and the weight and our state now will be only the last edge. Is that correct?
Yes, 7464168.
Я кстати правильно понимаю, что Е это баян? Потому что если нет, то как люди решали её за 6-7 минут?
As far as I understand, E is a well-known problem for top contestants of these round, because they solved it in 6-7 minutes, isn't it?
You asked this question in english thread, so i'll respond in English
I saw this problem 5 or 6 times during last year, most recently — 2 days ago at SNSS Round 1. BTW, i think that general idea "sort edges and then add them one by one" for this kind of problems is well-known, and one could come up with solution in short time even if he did not solved exact same problem before.
I initially forgot the contest and came in the middle, didn't look the scoring system is dynamic, found D easy and participated then solved A and B with very low points. Finally get WA on D because of overflow . I'm green again !!! :S
Hello guys, Please look on this sumbit: http://codeforces.com/contest/459/submission/7477151
v[MAXN] = (the biggest weight on path, path's length) Why, if I comment this if, I got WA on test 5? It looks to me unnecessary, since I find always the longest path (INF)?
Round was great one, although I solved only B and E. Problem A: Failed. Problem D: didn't have time. Problem C: I don't know solution.
I found a solution for problem E where we build a secondary graph with the edges of the original graph(G=(V,E)) as vertices, let's call it G'=(V',E'). Obviously |V'|=|E|. Now for each two vertices from V'- u and v, if there is an ascending path using the edges from the original graph that correspond to u and v, then we connect them(we build a directed edge from u to v).
For example: There is a directed edge from 1 to 2 with weight 4, and an edge from 2 to 3 with weight 6, then we connect the vertices that correspond these edges in G'.
The resulting graph is a DAG and we can use a simple BFS to find the longest path after using a topological sort. The only thing that I can't figure out is how to prove that G' is a DAG. I know the solution is O(M^2), the complexity can be easily reduced by not trying all the possible combinations of edges.
I came up with similar solution, but don't know how to reduce complexity.
I doubt it can be reduced — but you can just add edges by non-decreasing weight and update an array of longest paths ending in a given vertex.
Well, you don't really need to try all possible combinations of edges. Just pick any two adjacent nodes u and v, and let the cost of the path between them be w. Now for every edge that goes from v, check if it's cost is greater than w. If yes, then add an edge in G' from (u,v) to (v,k), where k is the node adjacent to v for which cost(u,v)<cost(v,k). The complexity will be greatly reduced because this way we don't check a lot of unnecessary combinations of edges.
It's still O(m2). take a look at my TLEd solution that made exactly what you described:7477085. I didn't even built the graph, just did DFS on it implicitly.
I tried optimizing further:
sorting edges by decreasing weight, this way we have a valid topological sort on the implicit DAG when we traverse it.
with the topological sort, I can do a iterative DP:
here is the submission: 7477218
but this is still O(m2), and a fairly easy test case generator can create the worst case scenario: half of the edges going out of a single vertex and the other half ending in this same edge. you can see the amount of comparisons increases exponentially. in the end my solution converged to what most people did: sorting edges and adding each edge: 7477362
I came up with an (mlgm) solution , for case 10^5 its ok but for 2*10^5. TLE. I can't understand, even sorting takes mlgm 7481958
that's exactly what I've explained here. it's not O(m * log(m)), it's O(m2). Consider this case: 3 * 105 vertices and 3 * 105 edges. the first 2 * 105 edges (in order of decreasing weight) go out of vertex 1 and into some random vertex. The other 105 edges come from a random vertex and end in vertex 1. In your algorithm, (even with the sorting), you'd make 2 * 105 * 105 = 2 * 1010 calculations, which obviously results in TLE.
what if we select the edges randomly ? That should decrease some time , but will it be sufficient?
can you elaborate on how would choosing edges randomly would help? I didn't get it
Nope .. Sorry !!! I misunderstood. At the end of the day I also had to do the sorting and adding each edge. Please comment here if you had found something else.
"It's guaranteed that the graph doesn't contain self-loops and multiple edges."
That's not even a valid test case?
but my example doesn't have any self-loops nor multiple edges
What does no multiple edges even mean then if it doesn't mean no more than one edge from vertex A to vertex B?
And where diz I said there was more than one edge from A to B? Remember edges are directed, and assume no constrants are violated when I say "random"
When editorial will be published?
problem c i think is too strict time limit, my submission tle in tc 9, which is 1000*1000 numbers needed to print
http://codeforces.com/contest/459/submission/7479926
i tried counting time needed to fill all output to array, just needed 12 ms, and in custom test it needs about 1600 ms until it finished running
edit : tried to add them all to StringBuffer first, then print in one line for each line got AC, i wonder printf from printwriter java is slower than println
Yes, input/output is slow as heck. When there are a lot of things to read/write, this rules out many slow languages. Consider learning C++ or some fast language for this kind of problems with heavy I/O. (I mostly use Python, but I used C++ for this problem for this very reason; Python wouldn't be able to print 106 numbers in time.)
As for your question added as an edit, I can't say, since I don't know Java much.
Round Stats
I have come up a solution of E with mlgm time. My approach is , first take the graph as edge list. Now for each edge we do a dfs(i.e DP) from that edges endpoint. and calculate the maximum path from that edge and save it in a map.
but this solution gets TLE. I tried unordered map hashing, but still TLE at case 6. Can someone explain why mlgn solution doesn't work? Here's my submission 7481958
Div.2 Problem C: http://codeforces.com/contest/459/submission/7482628 On test 3, d = 2 so the answer should be 2 lines not 3.
You read the n, d, k instead of n, k, d
are you sure about meaning of "soon" ?
How do I do problem D using Segment Tree ?
First, precompute f(1,i,a_i) and f(j,N,a_j). Then, do a linear scan for j from 1 to n. For each v, store the number of indices i with i<j such that f(1,i,a_i)=v in a SegmentTree (let's call it S) by simly calling S.add(f(1,j,a_j),1) at the end of each iteration. Then you get the number of indices i with i<j such that f(1,i,a_i)>f(j,n,a_j) as S.sum(f(j,n,a_j)+1,10^9).
Note that you can use a BIT as well.
In addition to what magula said, here's code: http://codeforces.com/submissions/venk13#
Congratulations to all that solved all five problems! By the way, why did http://codeforces.com/contest/459/submission/7473140 fail test 45?
there isn't any square with these vertices: (70,0) & (0,10).
In your "diagonal case" you must first check that this statement is true: |x1 - x2| = |y1 - y2|.
Checking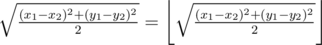 isn't enough. As you can see, on test case
isn't enough. As you can see, on test case 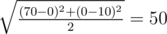 and you assume that answer is existing.
and you assume that answer is existing.
70 0 0 10please add editorial soon
"Editorial will be published soon." = "Never."
Самую сложную задачу решили 500 человек и если хотя бы один человек написал разбор для этой же задачи, и остальные разборы написали другие люди, в итоге мы получим разбор одного раунда?
Идея такая. Сортируем все ребра в порядке убывания. Для каждой вершины поддерживаем вектор двух чисел. А именно, вес и ответ, если начинать обход из данной вершины. Теперь идем по отсортированным ребрам. Для каждого ребра смотрим на вектор чисел вершины, в которую ребро входит. Бинпоиском подбираем позицию, в которой вес будет нас удовлетворять. Назовем пару найденных чисел W и ANS. Тогда для текущей вершины (вершина из которой исходит текущее ребро) пушим в вектор вес текущего ребра и max(ANS + 1, предыдущий ответ для этой вершины). Очевидно, что в этом векторе веса будут в убывающем порядке, а ответы в возрастающем, что позволяет при бинпоиске подбирать оптимальный "путь".
P.S. Зачем было писать комментарий на русском в английскую ветку?
Можно обойтись без бинпоиска, если просто поддерживать в вершине лучший ответ для двух различных весов исходящих рёбер.
Still waiting for the editorial... :/
R.I.P :p
Its easier to wait for round 262's editorial
that's okay...

UPD: also if you go through the blog you could find a lot of good solutions for above problems :-)
"soon" is up :D where is the editorial? Erfan.aa
Maybe, here?