


Good evening Codeforces, let me briefly describe solutions for all problems of today's morning yandex algorithm round. Thanks everyone who participated, I apologize for making problems a bit too tough and viscous for a 100 minutes contest. Anyway, I hope everyone found something interesting.
I would like to thank lperovskaya for organising this competition and managing Yandex.contest, snarknews and SergeiFedorov for their help with the problemset, Endagorion, PavelKunyavskiy, AleX, glebushka98, gustokashin, map and boris for testing. Special thanks to Gassa and my girlfriend Marina Kruglikova for fixing mistakes and disambiguations in English and Russian statements.
Let's get it started.
Problem A. Odysseus Sails Home.
There is no tricky idea behind this problem: one just needs to check if the vector (xf - xs, yf - ys) can be represented as a convex combination of vectors (xi, yi). One of the easiest approaches for the general case is to try all pairs of wind vectors and check if the target vector lies inside the cone they form. However, the devil is in the details. One shouldn't forget to:
Check if it's possible to get to Ithaca using only one wind direction;
Special if for case (xf, yf) = (xs, ys);
Ignore wind vectors (xi, yi) = (0, 0);
Avoid usage of doubles — everything fits in long long.
Time complexity: O(n2). O(n) solution also exists.
Problem B. Chariot Racing.
For the fixed value t = const we can easily calculate the intersection of all segments (chariots) as max(0, min(bi + vi * t) - max(ai + vi * t)). The problem was to find maximum for t ≥ 0.
Both min(bi + vi * t) and max(ai + vi * t) are convex functions. min(bi + vi * t) is concave upward, because it's derivative only decreases, as faster chariots overtake slower one. Similar max(ai + vi * t) is convex down. This means function min(bi + vi * t) - max(ai + vi * t) is concave upward, and this, in turn is sufficient condition for applying ternary search.
Ternary search is enough to solve the problem, but the solution which does binary search on derivative is faster and more stable. We need to find the maximum t such that the chariot i with minimum bi + vi * t goes faster then the chariot j with maximum aj + vj * t.
The only special case (for some solutions only) was n = 1.
Time complexity: O(n·logMaxC).
Problem C. Equality and Roads.
First check if the graph is connected. If no, print <<\t{NO}>> for all queries.
For connected graph count the number of connected components if only 0-edges are allowed (denote it as a) and the number of connected components if only 1-edges are allowed (denote it as b). Then, for the given x it's possible to construct the desired span if and only if condition b - 1 ≤ x ≤ n - a holds.
Lets proof the above statement. It's pretty obvious that this condition is necessary, but the sufficiensy isn't that clear. In my opinion, the easiest way is to present the algorithm. It consists of five steps:
Create DSU, add all 1-edges.
Add all 0-edges, remember which of them caused joins. There will be b - 1 such edges.
Clear the DSU, add all 0-edges remembered on step 2.
Add 0-edges until there are exactly x of them in the current span.
Add 1-edges until the graphs becomes connected. That will always happen because of the step 1 and 2.
Time complexity: O(n).
Problem D. Sequences of Triangles.
Thanks to snarknews — the author and developer of this problem.
Let f(x) be the longest sequence that ends on the triangle with the hypotenuse of length x. If we generate all Pithagorean triples with a, b, c ≤ L the dynamic programming approach will be the one that is easy to implement here.
Exhaustive description of the generation process and Euclid's formula could be found here, I would like to skip copying it to analysis.
Problem E. Strong Squad.
Thanks to SergeiFedorov — the author of this problem.
Perimeter p is equal to 2·(h + w), where h is the number of rows and w is the number of columns in the resulting rectangle. Build a bipartite graph on rows and columns where there is an edge connecting row x to column y if and only if soldier(x, y) = 0. What we should find now is the maximum independent set, such that in both set of rows and set of columns there is a least one vertex chosen (we are not allowed to choose rectangles 0 × m or n × 0).
The [well-known fact](https://en.wikipedia.org/wiki/K%C3%B6nig%27s_theorem_(graph_theory)) (yes, just say that the fact is well-known if you don't want to proove it) is that the size of the maximum independent subset in bipartite graph is equal to |V| + |U| - ν(G), where ν(G) stands for the maximum matching. To meet the condition that there should be at least one vertex chosen in both parts we should:
Try all the available pairs;
Exclude vertices already connected to chosen pair;
Find maximum matching.
Time complexity: O((nm)2·min(n, m)) or O(n5) for the worst case n = m. Is reduced to O(n4.5) by using Dinic's algorithm.
About Time Limit: though for n = m = 100 the number of operations will be about C·1010, C seems to be pretty small. We can show that  comes from the fact that the worst case is then only half of the cells is filled with zeroes. Also at least
comes from the fact that the worst case is then only half of the cells is filled with zeroes. Also at least  comes from the Kuhn's algorithm itself. The actual timing for the most straightforward Kuhn was about 2.5 from 5 seconds TL. Any optimisations sped it up to less than 1 second.
comes from the Kuhn's algorithm itself. The actual timing for the most straightforward Kuhn was about 2.5 from 5 seconds TL. Any optimisations sped it up to less than 1 second.
Problem F. Lexicographically Smallest String.
We want to pick up two indices and revert corresponding substring to make the resulting string as small as possible. To start with let's reduce a degree of freedom from 2 to 1.
Statement 1. If we represent string S as S = c + S' and character c is not greater than any character in S', than Answer(S) = c + Answer(S'). Otherwise, the answer always reverts some prefix.
Proof. Assume Answer(S) < c + Answer(S'), that means we should revert some prefix of S, i.e. some substring (1, i). If we revert substring (2, i), the length of the prefix that consists of only c will increase, and the result will become lexicographically smaller. Assumption is incorrect. If c is greater than some character os S' it's obvious we should revert some prefix that ends at position with the smallest possible character.
Now we need to solve the following task: revert some prefix of the string S to make it as small as possible. First, we need to take a look at string Sr and it's suffixes. We will call two suffixes strongly comparable if none of them is a prefix of another. Similary, we will say that one suffix is strongly lesser or strongly greater than another, if they are strongly comparable and the corresponding inequality holds for classiс comparison.
Statement 2. If S = A + B = C + D and Ar is strictly lesser than Cr than Ar + B is stricly lesser than Cr + D. Proof: obvious.
From statement 2 it follows that we should only consider suffixes of Sr that are greater than any other suffix they are strictly comparable to. From definition of strict comparison it comes out all the remaining suffixes are prefixes of the longest one remaining. We can try to revert them all and choose the best, but this may be too slow.
From the string theory and prefix-function algorithm we know, that if the longest suffix of the string S' that is equal to it's prefix has length l than S' = w + w + ... + w + w', where w' is prefix of w and w has length n - l.
Statement 3. If we present the longest suffix S' that is not majorated by any other suffix in the above form, than the set of other not majorated suffixes will be equal to the set of suffixes of S' that have the form w + w + ... + w + w'.
Proof. If the string w is not prime, than there exists some suffix of S' of length more than n - |w| that is not striclty lesser than S', but this contradicts to the way we found w. That means the string w is prime and only suffixes of form w + w + ... + w + w' are not strictly comparable to S'.
Statement 4. If |A| = |B| then A + A + C < A + C + B < C + B + B or A + A + C > A + C + B > C + B + B or A + A + C = A + C + B = C + B + B for any string C.
Proof. Compare strings A + C and C + B. The result of this comparison will determine the case, as we could always change A + C to C + B or vice versa.
Applying the statement 4 to the case where C = w', A = w, B = wr we conclude that we should only try to revert the longest and the shorest prefix of S such that corresponding suffixes of Sr are not strongly greater than any other suffix of Sr.
To find those suffixes of Sr one should perform Duval's algorithm to find Lindon decomposition of the string Sr. We are interested in the last prime string in the decomposition and the last pre-prime string in algorithm's workflow (or the last prime for the string S + #, where # is some character striclty smaller than any other character in S as was mentioned in comments by Al.Cash.
Time complexity: O(|S|).







Auto comment: topic has been updated by GlebsHP (previous revision, new revision, compare).
Auto comment: topic has been updated by GlebsHP (previous revision, new revision, compare).
I'll spoil the intrigue for problem F, because I solved it during the contest but made a silly bug.
1) Skip the prefix of S, which is already lexicographically smallest that can be formed from letters of S, for example
aabdcdcdc->[aab]dcdcdc. If it's the whole string — we're done.2) If we reverse the remaining suffix, it's easy to see that we need to find the minimum suffix in it and reverse the corresponding substring in S, for example:
babca->acbab, min suffix isab, so the answer isabbca3) You could note this method doesn't work for the first example,
dcdcdcyieldscddcdc, but the answer iscdcdcd. To fix this we need to find the minimum suffix adding character at the end, which is greater than all the letters.4) From two options we choose the better one.
5) Minimum suffix is a classical algorithm with linear solution and no additional memory.
Pythagorean triples tree is also useful for D.
Thanks for nice problemset!
However those constraints in E were pretty disturbing for me. If we have 1010 then constant should be at most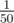 .
.  and
and  don't seem to be sufficient at the first glance. I think flow in my library is very fast, but fact that summed size of graphs whose flows I need to compute was 108 was very frightening. I think that it is possible to create tests which will cause many accepted solutions to give TLE.
don't seem to be sufficient at the first glance. I think flow in my library is very fast, but fact that summed size of graphs whose flows I need to compute was 108 was very frightening. I think that it is possible to create tests which will cause many accepted solutions to give TLE.
But even leaving that alone I have one question — why did you set constraints so high, what were you trying to achieve this way? In polish guide for problemsetters there is a statement that constraints should be lowest possible so that bruteforces won't pass (and I think that is a very wise statement). Here I think that there is only one possible bruteforce which is exponential, so n,m <= 30 should be sufficient to make it TLE! There are also some slower flows, but I don't think that we should ncessarily make them TLE. If you will be afraid of some heuristic exponential solutions then n,m<=50 would be more than sufficient, but it will be much more clear that O(n5) or O(n4.5) would pass!
At least I read that problem like 3 minutes before the end, so I haven't got any chance to solve it, but if I had come up with the solution during contest, I wouldn't code it and I would be angry afterwards :P.
Setting limits as n,m <= 30 would be too weak, I think. There could be a solution that does branch and cut.
Go from the top line to the bottom line. On each level you decide whether to "include" this line or not. If you include the line then you need to do a bitwise-AND thus excluding columns where the current line has zeros and the lines selected up to now all had ones.
With a straightforward approach you need to consider 2 possibilities (select/drop) at every line. But if adding the line excludes only 0 or 1 columns you should never drop it (as perimeter is the target function). So you only need to consider both including the current line and dropping it when at least 2 columns are excludded by adding it.
With bitwise arithmetics and LUTs for counting bits the complexity could be about 2^50 for the original problem constraints.
That's exactly what I said — if 30 seems to be too small for heuristic exponential solutions then 50 would be more than sufficient.
n,m <= 50 means that there is a O(2^25) exponential solution. Could still be fast enough.
Auto comment: topic has been updated by GlebsHP (previous revision, new revision, compare).
Auto comment: topic has been updated by GlebsHP (previous revision, new revision, compare).
I seriously wanted an answer why set n, m ≤ 100 when you can set n, m ≤ 50 in E :(
I was afraid of some sort of meet-in-the-middle approach.
In problem C, the correct condition is b - 1 ≤ x ≤ n - a
My AC solution: http://paste.ubuntu.com/11757693/
Fixed, thanks for noticing.