


Suppose I have a set of intervals and for any given interval I want to know how many intervals in my set are fully contained in it.
Does anybody know of an efficient way doing this?
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | jiangly | 3578 |
| 4 | orzdevinwang | 3570 |
| 5 | Geothermal | 3569 |
| 5 | cnnfls_csy | 3569 |
| 7 | tourist | 3565 |
| 8 | maroonrk | 3531 |
| 9 | Radewoosh | 3521 |
| 10 | Um_nik | 3482 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 165 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Suppose I have a set of intervals and for any given interval I want to know how many intervals in my set are fully contained in it.
Does anybody know of an efficient way doing this?






If you sort all intervals in the set according to their right ends the problem is easily transformed into a well-known problem "How many elements from l to r have their values ≥ x".
Yes that is true but it is not clear to me how one solves this problem.
For a fixed x one could use a segment tree but I don't see how to do this as x varies.
The problem "How many elements from l to r are greater than or equal to k" is a common problem that can be solved with a persistent segment tree. At first we will compress the values so that they are all positive numbers less than or equal to N. Then, for each position i, we will build a segment tree with all numbers up to index i. So we will do update_tree_i(A[1],1), then update_tree_i(A[2],1), then update_tree_i(A[3],1) and so on until we do update_tree_i(A[i],1). Now a query for given i,j,k can be found easily — it's query_tree_j(p,n)-query_tree_i-1(p,n) where p is the compressed value of the least number greater than or equal to k among the initial N numbers. What we can notice is that the tree for index i is the same as the tree for index i-1 except for O(logN) nodes so we need to use a persistent segment tree.
UPD: I fixed a small mistake in the "query" part.
P.S. This is an online solution. There exists an offline one based on BIT/segment tree and sorting the queries from largest to smallest K and storing the array numbers in a max-heap. Then we loop over the sorted queries and successively insert the numbers into the tree so that at each step we have included all numbers which are greater than or equal to the number we query so it's just a normal BIT/segment tree :)
Thanks for this. I am still not sure if I get it but this should be enough to figure it out.
The way you're describing it here "Then, for each position i, we will build a segment tree with all numbers up to index i. So we will do update_tree_i(A[1],1), then update_tree_i(A[2],1), then update_tree_i(A[3],1) and so on until we do update_tree_i(A[i],1)." makes it seem like the construction takes O(N^2) memory and time. What am I missing?
Yeah, it's O(N^2) memory if we make new segment tree each time. But what we can notice is that if we do update_tree_i(A[i+1],1) we get the tree for position i+1. So the "difference" between the trees for two consecutive positions is only one update which is O(logN) nodes. So that's why we need to use a persistent segment tree. This is a tree in which every update allocates memory only for the changed nodes. Here is a good tutorial on it — http://blog.anudeep2011.com/persistent-segment-trees-explained-with-spoj-problems/. Implementing it can be done in the following way. We use a structure node which contains it's value, the range it covers [from; to] and pointers to the left and right children. The function update(node *root, int pos, int value) returns a pointer to the root of the new tree, obtained after the update. If root is NULL, then we return NULL. Otherwise, we check if we are out of range, that is root->from>pos or root->to<pos. If that's so, then we return the unchanged root. Otherwise, if root->from==root->to and root->from==pos, then we create a new node pointer "res" in which we copy the information of "root", increase its value with "value" and then return "res" as the root after the updates. Otherwise, we create a new node pointer "res" and do:
Tell me if something is unclear, I will try to help :)
Can you explain the offline version more clearly ?
Yes, very briefly, you can consider the problem as a 2D range query. Map each interval to a point (L, R), meaning the beginning index is the X coordinate and the ending index is the Y coordinate. Then if we want to query for an interval (L, R), we simply want to find all points to the bottom right of that point.
Thus we have a collection of points and a collection of range queries that we want to consider. If we know all the queries beforehand (offline version), we just have to sort them by decreasing order of x-coordinate and sweepline while maintaining a fenwick tree on y-coordinate.
As Lord_F said after sorting by minimum left end. Now for a query [L, R] we want to know how many intervals from those whose left end equals L to those whose left end equals R, has a right end ≤ R. This can be done in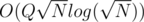 by sqrt decomposition, decompose the intervals into buckets after sorting them by left end, and then sort every bucket by its right end. Then each query can be done by binary search in every candidate bucket.
by sqrt decomposition, decompose the intervals into buckets after sorting them by left end, and then sort every bucket by its right end. Then each query can be done by binary search in every candidate bucket.
buckets based on what?
Are you here because of the Codechef December Long? xD