


I stumbled upon UVA Summing the Lengths of the Longest Increasing Subsequence of Permutations, that basically asks for the first three digits of the sum of the LIS lengths over all permutations of length n. After trying it or a few days, I gave up and searched for information. It is easy to see that:

Where  denotes the expected value. It is easy to manage the logarithm of that number with Stirling's approximation, get the fractional part of the logarithm and exponentiate to get the first digits. Nevertheless the core of the problem lies in computing
denotes the expected value. It is easy to manage the logarithm of that number with Stirling's approximation, get the fractional part of the logarithm and exponentiate to get the first digits. Nevertheless the core of the problem lies in computing  for a random permutation w of length n. I have been reading about the topic, and this paper gives the estimate
for a random permutation w of length n. I have been reading about the topic, and this paper gives the estimate

Where c ≈ - 1.77108 as a known estimate. Nevertheless, this doesn't give the ouput of uDebug and differs by a ± 1 margin in about 5% of the cases . I have also asked the question in MathOverflow, and it seems that that estimate is the best known and that there is no polynomial or logarithmic time algorithm for computing .
Finally, I am right now trying to contact the problemsetter baodog looking for clues, as there seems to be few options now:
- He has improved the state of the art in computing without knowing so and expects the contestant to do so too.
- He has not improved the state of the art and expects the contestant to provide a solution.
The last option is ethically questionable. The problem stats page is quite strange too, since the only accepted solution's are Josh Bao's(the problemsetter) in the 2007 and someone else 20 days later. Also, the old version of the problem asks for the first 5 digits and has a different output for the same input truncating it to the first 3 digits. Moreover, I get the old output by truncating the BDJ estimate to 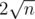 as shown by this code. So, can someone provide help to solve this problem and I am not seeing something obvious? Am I right and this problem is impossible with today's knowledge of the matter?
as shown by this code. So, can someone provide help to solve this problem and I am not seeing something obvious? Am I right and this problem is impossible with today's knowledge of the matter?







I guess he probably improved the state of the art, then, since it would make no sense for him to be expecting a novel algorithm and even providing a hint for it, as he does on the problem statement.
Anyway, have you tried contacting him here on Codeforces? His username is baodog and I've seen him taking part in a discussion recently, so, he might visit his profile once in a while.
I have PM'ed him through codeforces a day before posting this, and I have also sent a mail to the contact available on UVA. Unless he improved the state of the art by "computing the first few values and looking at beautiful patterns", I don't think that can be true. Also, the fact that the output has changed since 2007, from using the coarser estimate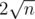 to the more procise DBJ result gives me more reasons to think that he doesn't have a proved solution to the problem. But yes, it isn't impossible.
to the more procise DBJ result gives me more reasons to think that he doesn't have a proved solution to the problem. But yes, it isn't impossible.
Please feel free to contact me via PM or on my site uDebug and we can try to get to the bottom of this. I'm happy to help with problems on UVa Online Judge and ACM-ICPC Live Archive.
Hi!
I'm actually not aware of the paper (and unreasonable for anyone to find, since it's on a contest), and it only gives an estimate. For the dataset, for the given N (from 100 to 100000), the first 3 digits was computed (if I remember correctly from nearly 10 years ago), using stochastic sampling over the permutations. We keep sample until there is no difference in the result. It's verified by 2 of my friends. Again, there shouldn't be a +-1 error, but if the sampling is somehow biased (though we tried different random seeds), it's possible.
Note UVA (and all problems on there) is a Non-Profit, Volunteering effort, so please be kind, if you find any mistakes. There is probably 15-30 incorrect problems or datasets on UVA, which is only 0.5% or so, so 99.5% of the time you should be fine on UVA, which is pretty good for a non-profit. Definitely send in corrections if you find them, however just be sure you are correct. Like this papers gives a Bound, it could error from the real values.