


div2 A. In this problem you should find length of polyline, multiply it by k / 50 and output that you will recieve. Length of polyline is sum of lengths of its segments. You can calculate length of every segment using Pythagorean theorem: 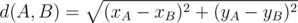 .
.
div2 B. Idea of this problem was offered by RAD. It was the last problem in the problemset and I had no any easy idea:) I thank him for it.
Here you should calculate an array cnt[100]. i-th element of it stores number of sticks whose lengths equal i. Now you should calculate number of pairs of sticks of equal lengths. This number is 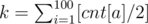 , where [x] is floor of x. For every frame you need 2 if such pairs and you can choose it in any order. Therefore the answer will be z = [k / 2].
, where [x] is floor of x. For every frame you need 2 if such pairs and you can choose it in any order. Therefore the answer will be z = [k / 2].
div2 С. div1 A. At the first you should consider cases when t0 = t1, t0 = t2 and t1 = t2. Answers will be (x1, 0), (0, x2) and (x1, x2). The last 2 of them didn't present in the pretests.
Next, for all 1 ≤ y1 ≤ x1 you should find minimal y2, for that t(y1, y2) ≥ t0. You can do it using one of three ways: binary search, two pointers or just calculation by formula [y1(t0 - t1) / (t2 - t0)], where [x] is rounding up of x. You should iterate over all cases and choose one optimal of them.
The last tricky case consists in the fact that for all 1 ≤ y1 ≤ x1 и 1 ≤ y2 ≤ x2 t(y1, y2) < t0. For example, you can see following test
100 110 2 2 109 (it is the 6th pretest).
In this case you should output (0, x2).
All calculations should be done in 64-bit integers (8th pretest checks overflow of 32-bit integers) or very carefully in the real numbers.
div2 D. div1 B.
Let us calculate a prefix-function for all prefices of string. Prefix-function p[i] is maximal length of prefix that also is suffix of substring [1...i]. More about prefix function you can see in a description of Knuth-Morris-Pratt algorithm (KMP).
The first of possible answers is prefix of length p[n]. If p[n] = 0, there is no solution. For checking the first possible answer you should iterate over p[i]. If at least one of them equal to p[n] (but not n-th, of course) - you found the answer. The second possible answer is prefix of length p[p[n]]. If p[p[n]] = 0, you also have no solution. Otherwise you can be sure that the answer already found. This substring is a prefix and a suffix of our string. Also it is suffix of prefix with length p[n] that places inside of all string. This solution works in O(n).
Also this problem can be solved using hashing. You can find hash of every substring in O(1) and compare substrings by comparing thier hashes. Well, let's check for every prefix that it is a suffix of our string and store thier lengths into some array in the increasing order. Then, using binary search over the array, you can find maximal length of prefix that lie inside of string. Check of every prefix you can do in O(n). So, you have some  solution.
solution.
In point of fact, the array of prefix lengths in the previous solution is list { p[n], p[p[n]], ... }, that written if reversed order. From the first solution you know that the answer is prefix of length either p[n], or p[p[n]] (if it exists, of course). Therefore some naive solution without binary search can fits in the limits if you will stupidly check all prefices in the order of decrease thier lengths:) This solution works in O(n).
Also this problem can be solved using z-function.
div2 E. div1 C. You can see that every command i, j you should do no more than once. Also order of commands doesn't matter. Actually, sequence of command you can represent as boolean matrix A with size n × n, where aij = 1 mean that you do the command i, j, and aij = 0 mean that you don't do it.
Let us describe one way to construct the matrix.
Let the starting image is boolean matrix G. A boolean matrix B of size n × n stores intermediate image that you will recieve during process of doing commands.
For the upper half of matrix G without main diagonal you should move line by line from the up to the down. For every line you should move from the right to the left. You can see that for every positions all nonconsidered positions do not affect the current position. So, if you see that values for position i, j in the matrices G and B are different, you should do command i, j: set in the matrix A aij = 1, and change segments (i, i) - (i, j) and (j, j) - (i, j) in the matrix B.
For the lower half of the matrix G without main diagonal you should do it absolutely symmetric. At the end you should iterate over main diagonal. Here it should be clear.
Well, for matrix G you always can build matrix A and do it by exactly one way. It mean that this way requires minimum number of commands. So, you can get answer for problem by following way: you can build the matrix A from the matrix G and output number of ones in the matrix A.
There is only one problem that you should solve. Algorithm that you can see above works in O(n3), that doesn't fit into time limits. Let's speed up it to O(n2). Consider in the matrix B the upper half without main diagonal. During doing commands all columns of cells that placed below current position will have same values. Values above current position are not matter for us. Therefore instead of the matrix B you can use only one array that stores values of columns. It allows you do every command in O(1) instead of O(n). This optimization gives a solution that works in O(n2).
div1 D. Let us represent a number in the Fibonacci code. You can imagine Fibonacci coding by following way: i-th bit of number corresponds to the i-th Fibonacci number. For example, 16=13+3 will be written as 100100. You can represent into this code any positive integer, for that no two neighbouring 1-bit will be present. It is possible to do it by only one way (let's define this way as canonical). In the problem you should calculate a number of ways to represent some number into Fibonacci code in that two ones can be placed in the neighbour positions.
You can easily get the canonical representation if you generate several of Fibonacci numbers (about 90) and after that try to substract all of them in the decreasing order.
You should store positions of 1-bits of canonical representation into an array s in the increasing order. You can decompose any of them into two ones. It looks like that:
1000000001 // starting number;
0110000001 // there we decompose
0101100001 // the first "one"
0101011001 // using all
0101010111 // possible ways
After some number of such operations you will meet next 1-bit (or the end of number). This 1-bit also can be decomposed, but it can be "shifted" by only one bit.
Let us dp1[i] is number of ways to represent a number that consists of i last 1-bits of our number in the case that the first of 1-bits are NOT decomposed. Also let us dp2[i] is number of ways to represent a number that consists of i last 1-bits of our number in the case that the first of 1-bits are decomposed.
You can easily recaclulate this dp following way
dp1[0] = 1, dp2[0] = 0
dp1[i] = dp1[i - 1] + dp2[i - 1]
dp2[i] = dp1[i - 1] * [(s[i] - s[i - 1] - 1) / 2] + dp2[i - 1] * [(s[i] - s[i - 1]) / 2]
where [x] is rounding down.
Answer will be dp1[k] + dp2[k], where k is total number of 1-bits in the canonical representation. So, we have  solution for one test.
solution for one test.
div1 E. Consider all partitions of 7 × 8 board into dominoes. There is only 12988816 of them (you can get this number using some simple bruteforce algorithm)
Also, consider all "paintings" of 7 × 8 board (i.e. number of cells of every color) and find number of patritions into set of pills of 10 types for every of them. In the worst case you will get 43044 partitions (this number you can get using another bruteforce algo).
In the first part of solution you should iterate over all partitions of board into dominoes and find all sets of pills that you will get. You will have no more than 43044 of them.
In the second part of solution you should try to distribute all available pills for every of sets that you recieved in the first part. You should distribute them in such way that maximal number of colors match.
You should build a graph that composed from 4 parts - source, the first part of 10 nodes, the second part of 10 nodes and sink. There are edges between all pairs of nodes from neighbour parts. From source to the first part you should set capacities of edges equal to numbers of available pills of every type. From the second part to sink you should set capacities of edges equal to numbers of pills in the current partition. From the first part to the second part you should use infty capacities and set costs equal to number of MISmatched colors in the types of pills (it is some numbers in range from 0 to 2). At the end, you should find maximal flow of minimal cost (MCMF) if this graph and save a flow that gets minimal cost.
In the third part of solution you should restore answer from optimal flow.
In the second part of solution you can replace MCMF by usual maxflow. You can see that at the beginning MCMF will fill edges of cost 0. So, you can fill them by hand. After that you can drop all edges of cost 0 and 2 and just find maxflow.







Using the prefix function it would take linear time, I'm not sure of another way, using hashes can speed up most cases but worst case can be indeed O(n2)
hashing , rabin karp + binary search works in O( n log(n) ) click it
89824218 Hashing with precalc to avoid TLE
In div B in kmp type solution, if p[n] != 0 than we have to search in the p[1..n-1] for the p[n] value, suppose the example is aaaaa, its p will be p={0,1,2,3,4} clearly there do not exist a value in p[1..n-1] such that it is equal to p[n] ,but it has a solution. and also in the second part it is there, if p[p[n]]=0 there exits no solution, suppose the example is qweqwexqwe its p will be p={0,0,0,1,2,3,0,1,2,3} here p[p[n]]=0 but there exists a solution? can any one explain me in detail??
sorry got my mistake !! kmp is hard to understad
please can you please tell me what your understood I also have the same problem
In problem div1 B can somebody explain this "The second possible answer is prefix of length p[p[n]]." thanx in advance.
P[n] is LPS(longest proper prefix of string that is also a suffix ending at n) (refer kmp string matching algorithm if you don't know about it)
let the string be abcabcabc here P[n] = 6 ("abcabc" is suffix ending at 9 which also a prefix of original string) check if any other i has P[i]= 6, ie a prefix of length 6 ends at i(i!=n)
if you found such i , ans is P[n] else check P[P[n]] (here P[6]=3)
if P[P[n]]=0, no other suffix other than P[n] is a prefix of original string ie no solution (eg abcdabcabcd, P[n]= 4, P[P[n]]= 0, no solution )
else a string of length P[P[n]] occurs atleast 3 times in original, once in prefix, once in suffix and once in middle at position (n-P[n]+1= 4 in ("abcabcabc")) so the ans in P[P[n]]
Can you please also suggest what leads us to think only about the two mentioned solutions? why can't there be any more ?
1) Suppose P[n] = 0, we can't find any by definition.
2) Suppose P[n] = L. By iterating the P[i] and if we've found one that equals L, then these three triplets has to be the largest by definition.
3) Suppose P[n] = L, But we didn't find any P[i] = L. That can only mean one thing, the answer we are looking for has to be strictly smaller than L.
3a) Further assume P[P[n]] = 0, then we know that, in the prefix of substring (from 1 to P[n]), it doesn't match any suffix of the same substring. Which means it doesn't match any suffix of the entire string of length smaller than L(anything equal to L is dealt in 2). If the beginning prefixes and ending suffixes don't match, then we cannot have any answers.
3b) Assuming that P[P[n]] = K > 0. Then this number must be the maximum. Suppose we have something in the middle that is larger than K and satisfies the constraints. Then it must exist in the prefix and suffix of the entire string. However, notice that when we looked at the suffix of the substring ending at P[P[n]], we should be able to construct a string of the same length since the prefix of the entire string = suffix of entire string = suffix of the substring ending at P[P[n]]. Then we have the contradiction that P[P[n]] = K which is supposed to be the maximal.
Most amazing explanation thanks for explaining. This question is amazing as well.
I don't know what you found amazing about the explanation. It was rather obvious if you really know "WHY" PREFIX FUNCTION algorithm "WORKS". And for somebody who doesn't know, even after reading this explanation he still wouldn't know "WHY" prefix function works which is the most important part.
Thank you so much for that reply. It is so much better worded than the editorial. But it is my first time reading about KMP and I am having a hard time figuring out how we can say that the substring we get from P[P[n]] will also be a suffix of the original, complete string. I understand that it will be a prefix (by the property of array itself), but can't wrap my head around it being a suffix too. I have been stuck at this for some time now, but I don't know what possibly obvious thing I am missing, and I would appreciate any help I can get. Thanks!
p[n] gives the suffix which is also prefix. So there is a string of length p[n] starting from beginning(prefix)..Now by p[p[n]] we are basically checking if this prefix string has again any sub-suffix that is also sub-prefix if it is so then it guarantees that suffix (p[n]) also follows the same. ``
EG
qwertyqwertyqwerty
p: 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 10 11 12
here p[n] = 12 (suffix of length 12)
so it means there is a prefix of length 12
now in this prefix of length 12(qwertyqwerty) we search if there is a sub-suffix which is also sub-prefix which we can get by p[12] which is nothing but p[p[n]].
now this guarantees the original suffix of length 12 has also these same sub-prefix and sub-suffix.
Hope it clears your doubt.
i also got this very clearly the only think i dont like is that i am unable to solve it without reading tutorial and reading discussions..plzz can you help me with it
Hello everyone. This is my code for c and can only run for first two cases. Does anyone know why it is incorrect code? Thanks.
include
include
using namespace std;
const double eps=1e-8;
int t1,t2,x1,x2,t0; int y1,y2,minV,maxL; int le,ri,mid; long double tempT;
int b_s(int x,int i){ tempT = (i*t1+x*t2)/((double)(i+x)); return tempT >= t0; }
int main(){ cin>>t1>>t2>>x1>>x2>>t0;
}
Did you sell your brain for 50 penny 50Penny?
Can anyone tell why my code gives TLE. According to me its complexity should be nlogn which is within the time limits. I use suffix arrays to calculate all suffixes that are also prefixes and store them in array. this is nlogn+nlogn = O(nlogn) Then I use binary search on this array to get the string. For string comparison in binary search i use KMP. again this is O(nlogn) It gives TLE on TC 26. here's a link to my code link.
You should try z-function, it is very easy and effective. I understood KMP for the first time and now i think it takes me 15min to understand again. :v
Seems that people like me are coming back to Password for z-function after contest #726
Let me share my z-function solution for div2 D. div1 B. https://codeforces.com/contest/126/submission/120114668
problem e is trash.
Can somebody tell me why this is TLE : https://codeforces.com/contest/126/submission/252494278
I have the exact same solution in C++ and it passes : https://codeforces.com/contest/126/submission/252154602
Is python inherently slower for this or am I doing something wrong?