


div2 A. В этой задаче нужно было найти длину ломаной, умножить ее на k / 50 и вывести что получилось. Длина ломанной --- сумма длин всех ее звеньев. Длина каждого звена считается по теореме Пифагора: 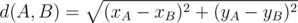 .
.
div2 B. Идею этой задачи подкинул RAD, поскольку это была последняя задача в комплекте, и мне уже ничего простого в голову не лезло:) Спасибо ему за это.
Посчитаем значения массива cnt[100], в котором будем хранить количество палочек соответствующей длины. Теперь посчитаем количество доступных пар палочек одинаковой длины. Оно равно 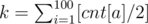 , где [x] --- целая часть числа x. Для каждой рамки нужно 2 такие пары, причем можно выбирать любые из них. Поэтому ответ будет равен z = [k / 2].
, где [x] --- целая часть числа x. Для каждой рамки нужно 2 такие пары, причем можно выбирать любые из них. Поэтому ответ будет равен z = [k / 2].
div2 С. div1 A. Во первых, нужно отдельно обработать случаи, когда t0 = t1, t0 = t2 и t1 = t2. Ответы в этих случаях будут (x1, 0), (0, x2) и (x1, x2). Последние 2 случая в претестах отсутствовали.
Далее, для всех 1 ≤ y1 ≤ x1 нужно найти такое минимальное y2, что t(y1, y2) ≥ t0. Это можно было делать тремя способами: бинпоиском, двумя указателями или же просто вычислением по формуле [y1(t0 - t1) / (t2 - t0)], где [x] --- округление числа x вверх. Перебрав все такие случаи, выбираем оптимальный.
Последний коварный случай состоит в том, что для всех 1 ≤ y1 ≤ x1 и 1 ≤ y2 ≤ x2 t(y1, y2) < t0. Например, в тесте
100 110 2 2 109 (это 6ой претест).
В этом случае следует выводить (0, x2).
Все вычисления должны быть выполнены в 64-битных числах (8ой претест был как раз на переполнение промежуточных вычислений) или же очень аккуратно в вещественных числах.
div2 D. div1 B. Посчитаем префикс-функцию для всей строки. Префикс-функция p[i] --- это длина наибольшего префикса, который также является суффиксом подстроки [1... i]. Подробнее о префикс-функции можно нагуглить, например, в описании алгоритма Кнута-Морриса-Пратта (КМП).
Первый кандидат в ответы --- префикс длины p[n]. Если p[n] = 0, то решения нет. Иначе пройдемся по всему массиву p и, если встретим где либо еще одно значение, равное p[n] --- то мы нашли ответ. В случае неудачи, второй кандидат на ответ --- префикс длины p[p[n]]. Если p[p[n]] = 0, то решения нет. Иначе сразу можно сказать, что ответ найден. Этот подстрока является и префиксом, и суффиксом, а так же суффиксом префикса длины p[n], который находится где-то внутри строки. Это решение работает за O(n).
Эту задачу можно было так-же решить и с помощью хэшей. Проверим все суффиксы на соответствие префиксам --- получим некоторый массив длин префиксов, упорядоченный по возрастанию. Затем бинпоиском найдем наибольший по длине префикс, который находится где-то внутри (преверка осуществляется за O(n)). Итого сложность решения  .
.
На самом деле, если в предыдущем решении присмотреться к массиву длин префиксов, то получим ни что иное, как p[n], p[p[n]] и т.д. в обратном порядке. Из первого решения мы знаем, что либо p[n], либо p[p[n]] ответ. Поэтому заходили даже такие наивные решения, как второе без бинпоиска, то есть просто проверка всех префиксов в порядке уменьшения длины. Это решение работает за O(n).
Также возможны решения с использованием z-функции.
div2 E. div1 C. Во первых, понятно, что каждую из операций i, j имеет смысл делать не более одного раза, а порядок операций не важен. По сути, всю последовательность команд можно представить себе как булеву матрицу A размера n × n, где aij = 1 означает, что мы выполняем команду i, j, и aij = 0 означает, что мы ее не выполняем.
Опишем способ построения такой матрицы.
Пусть изначальная картинка --- это матрица G. Еще заведем матрицу B, в которой будем хранить все изменения, которые получились в результате выполнения операций.
Для верхней половины матрицы G без диагонали мы будем двигаться построчно сверху вниз. Каждую строчку будем просматривать справо налево. Заметим, что для каждой рассматриваемой позиции никакие команды, соответствующие еще не рассмотренным позициям, не влияют на текущую позицию. Поэтому, если мы обнаруживаем несоответствие в текущей позиции i, j в матрицах G и B, то мы обязаны выполнить команду i, j: ставим в A aij = 1, а в B меняем отрезки (i, i) - (i, j) и (j, j) - (i, j).
Для нижней половины матрицы G без диагонали делаем все абсолютно симметрично. В конце проходимся по самой диагонали --- с ней должно быть все понятно.
Итак, для каждой матрицы G мы всегда и однозначным способом можем получить матрицу A. Это означает, что именно здесь и достигается минимум требуемых операций. Таким образом, ответ можно построить так: из G строим A и выводим количество единиц в A (в первой версии задачи был еще и вывод сертификата --- самой последовательности команд. Но из-за большого вывода от этого пришлось отказаться).
Осталось решить небольшею проблемку. Описанный выше способ позволяет сделать из G A за O(n3), что несколько долго. Ускорим его до O(n2). Рассмотрим в матрице B верхнюю половину без диагонали. В процессе выполнения алгоритма все столбцы ниже уже рассмотренных позиций всегда принимают одно и то же значение, а все значения выше нам уже никогда не понадобятся. Поэтому Вместо матрицы B можно использовать лишь один массив, в котором хранятся цвета столбцов и выполнять перекраску за O(1) вместо O(n). Эта оптимизация и дает нам решение за O(n2).
div1 D. Представим число в фибоначчиевой системе счисления. В двух словах что это такое: i-му числу Фибоначчи соответствует i-ый бит. Например, число 16 запишется как 3+13 или 100100. Любое натуральное число можно представить в таком виде, при этом в записи никогда не встретятся две единицы подряд. Таким образом можно представить число только одним способом (будем называть такое разложение каноничным). Нам же нужно посчитать количество разложений, когда две единицы могут стоять подряд.
Канонично разложить можно просто сгенерировав достаточно много чисел Фибоначчи (около 90) и потом жадно отнимая он данного числа начиная с самых больших.
Запомним на каких местах стоят единицы в каноничном разложении и сохраним их в массив s в порядке возрастания. Каждую из единичек можно раскладывать в 2 единички. Это выглядит примерно так:
1000000001 // начально число;
0110000001 // раскладываем
0101100001 // первую единичку
0101011001 // всеми возможными
0101010111 // способами
При этом через некоторое количество операций упремся в впереди стоящую единичку (или в конец числа). Однако эта единичка тоже может быть разложена, но она может "сдвинуться" только на 1 бит.
Заведем dp1[i] --- количество способов разложить число, состоящее из i последних единичек нашего числа при условии, что самая первая единичка ни во что не раскладывается. также заведем dp2[i] --- количество способов разложить число, состоящее из i последних единичек нашего числа при условии, что самая первая единичка обязательно раскладывается.
Пересчитывается эта динамика очень просто
dp1[0] = 1, dp2[0] = 0
dp1[i] = dp1[i - 1] + dp2[i - 1]
dp2[i] = dp1[i - 1] * [(s[i] - s[i - 1] - 1) / 2] + dp2[i - 1] * [(s[i] - s[i - 1]) / 2]
где [x] --- округление вниз.
Ответом будет dp1[k] + dp2[k], где k --- общее число единичек. Итого решение за  для одного теста.
для одного теста.
div1 E. Рассмотрим все разбиения доски 7 × 8 на доминошки. Их немного --- всего 12988816 (это можно узнать, запустив несложный перебор)
Кроме того, рассмотрим всевозможные "покраски" поля 7 × 8 (то есть количества квадратиков каждого из цветов) и найдем количество разбиений этих покрасок на множество пилюль 10 типов. В худшем случае получим 43044 разбиений (это число можно получить другим перебором).
Первая половина решения состоит в том, чтобы перебрать все разбиения доски на доминошки и найти все множества пилюль, которые получаются в результате таких разбиений. Их будет не более 43044.
Во второй части решения для каждого из них надо попробовать наиболее оптимальным образом распределить имеющиеся пилюли так, чтобы как можно больше цветов совпало.
Построим граф из 4 долей - исток, 1я доля на 10 вершин, 2я доля на 10 вершин, сток. Между всеми парами вершин из соседних долей протянем ребра. Из истока в 1ю долю назначим пропускные способности равные количеству имеющихся пилюль каждого типа. Из 2й доли в исток назначим пропускные способности равные количеству пилюль каждого из типов в текущем разбиении. Из 1й доли во вторую назначим бесконечные пропускные способности и стоимости, равные количеству НЕсовпадающих цветов типов пилюль (это какие то числа от 0 до 2). Пустим по графу максимальный поток минимальной стоимости --- он и найдет оптимальный ответ. Из всех разбиений найдем самый оптимальный ответ и сохраним его.
Третья часть решения состоит из восстановления ответа по потоку в оптимальном разбиении.
Во второй части решения MCMF можно заменить на обычный максимальный поток. Нужно лишь понять, что сначала MCMF будет всегда идти по ребрам стоимости 0, пока полностью не насытит их. Поэтому можно сначала жадно вручную насытить такие ребра, после него оставить только ребра стоимости 1 и на полученном графе запустить просто MaxFlow.
Сложность решения оценить сложно, но сразу видно, что оно заходит. Самое первое решение жюри на C++, написанное как попало, работает 1 с. Несколько более вдумчивые варианты работают 0,4 с, но их, при желании, можно и еще ускорить.







div2 A. А разделить на 50? )
В B-1 немного точнее найти максимум p в диапазоне [1..n-1]. Хотя, конечно, это то же самое решение (в массиве p есть все числа, вплоть до этого максимума). Просто тогда доказательство решения очевидно (p[p[n]] <= p[n]-1 <= p[n-1] <= max).
Вопрос по задаче D div 2 / B div 1. Могут ли пересекаться строки?
То есть может ли префикс перекеться с строкой в середине(ведь она не является началом), или же строка с суффиксом( без последнего символа она не будет концом).
Using the prefix function it would take linear time, I'm not sure of another way, using hashes can speed up most cases but worst case can be indeed O(n2)
hashing , rabin karp + binary search works in O( n log(n) ) click it
89824218 Hashing with precalc to avoid TLE
Кажется в задаче D (div1) сложность на один тест не logn, а максимум 90, т.е., если так можно выразиться, фибоначчиевый logn, т.е. колчество чисел фибоначчи, меньших n. В принципе, конечно, разница не велика, но всё же это вроде не logn.
Fib[n] ~ phi^n / sqrt(5)
Числа фибоначчи растут экспоненциально, значит фибоначчиев логарифм асимптотически эквивалентен обычному.
> Иначе сразу можно сказать, что ответ найден. Этот подстрока является и префиксом, и суффиксом, а так же суффиксом префикса длины p[n], который находится где-то внутри строки. Это решение работает за O(n).
Да, красивое решение. Я зачем-то проверял все префикс-суффиксы (циклом с итерацией n=p[n]).
2-х часовой....
Проблема решена.
In div B in kmp type solution, if p[n] != 0 than we have to search in the p[1..n-1] for the p[n] value, suppose the example is aaaaa, its p will be p={0,1,2,3,4} clearly there do not exist a value in p[1..n-1] such that it is equal to p[n] ,but it has a solution. and also in the second part it is there, if p[p[n]]=0 there exits no solution, suppose the example is qweqwexqwe its p will be p={0,0,0,1,2,3,0,1,2,3} here p[p[n]]=0 but there exists a solution? can any one explain me in detail??
sorry got my mistake !! kmp is hard to understad
please can you please tell me what your understood I also have the same problem
In problem div1 B can somebody explain this "The second possible answer is prefix of length p[p[n]]." thanx in advance.
P[n] is LPS(longest proper prefix of string that is also a suffix ending at n) (refer kmp string matching algorithm if you don't know about it)
let the string be abcabcabc here P[n] = 6 ("abcabc" is suffix ending at 9 which also a prefix of original string) check if any other i has P[i]= 6, ie a prefix of length 6 ends at i(i!=n)
if you found such i , ans is P[n] else check P[P[n]] (here P[6]=3)
if P[P[n]]=0, no other suffix other than P[n] is a prefix of original string ie no solution (eg abcdabcabcd, P[n]= 4, P[P[n]]= 0, no solution )
else a string of length P[P[n]] occurs atleast 3 times in original, once in prefix, once in suffix and once in middle at position (n-P[n]+1= 4 in ("abcabcabc")) so the ans in P[P[n]]
Can you please also suggest what leads us to think only about the two mentioned solutions? why can't there be any more ?
1) Suppose P[n] = 0, we can't find any by definition.
2) Suppose P[n] = L. By iterating the P[i] and if we've found one that equals L, then these three triplets has to be the largest by definition.
3) Suppose P[n] = L, But we didn't find any P[i] = L. That can only mean one thing, the answer we are looking for has to be strictly smaller than L.
3a) Further assume P[P[n]] = 0, then we know that, in the prefix of substring (from 1 to P[n]), it doesn't match any suffix of the same substring. Which means it doesn't match any suffix of the entire string of length smaller than L(anything equal to L is dealt in 2). If the beginning prefixes and ending suffixes don't match, then we cannot have any answers.
3b) Assuming that P[P[n]] = K > 0. Then this number must be the maximum. Suppose we have something in the middle that is larger than K and satisfies the constraints. Then it must exist in the prefix and suffix of the entire string. However, notice that when we looked at the suffix of the substring ending at P[P[n]], we should be able to construct a string of the same length since the prefix of the entire string = suffix of entire string = suffix of the substring ending at P[P[n]]. Then we have the contradiction that P[P[n]] = K which is supposed to be the maximal.
Most amazing explanation thanks for explaining. This question is amazing as well.
I don't know what you found amazing about the explanation. It was rather obvious if you really know "WHY" PREFIX FUNCTION algorithm "WORKS". And for somebody who doesn't know, even after reading this explanation he still wouldn't know "WHY" prefix function works which is the most important part.
Thank you so much for that reply. It is so much better worded than the editorial. But it is my first time reading about KMP and I am having a hard time figuring out how we can say that the substring we get from P[P[n]] will also be a suffix of the original, complete string. I understand that it will be a prefix (by the property of array itself), but can't wrap my head around it being a suffix too. I have been stuck at this for some time now, but I don't know what possibly obvious thing I am missing, and I would appreciate any help I can get. Thanks!
p[n] gives the suffix which is also prefix. So there is a string of length p[n] starting from beginning(prefix)..Now by p[p[n]] we are basically checking if this prefix string has again any sub-suffix that is also sub-prefix if it is so then it guarantees that suffix (p[n]) also follows the same. ``
EG
qwertyqwertyqwerty
p: 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 10 11 12
here p[n] = 12 (suffix of length 12)
so it means there is a prefix of length 12
now in this prefix of length 12(qwertyqwerty) we search if there is a sub-suffix which is also sub-prefix which we can get by p[12] which is nothing but p[p[n]].
now this guarantees the original suffix of length 12 has also these same sub-prefix and sub-suffix.
Hope it clears your doubt.
i also got this very clearly the only think i dont like is that i am unable to solve it without reading tutorial and reading discussions..plzz can you help me with it
Hello everyone. This is my code for c and can only run for first two cases. Does anyone know why it is incorrect code? Thanks.
include
include
using namespace std;
const double eps=1e-8;
int t1,t2,x1,x2,t0; int y1,y2,minV,maxL; int le,ri,mid; long double tempT;
int b_s(int x,int i){ tempT = (i*t1+x*t2)/((double)(i+x)); return tempT >= t0; }
int main(){ cin>>t1>>t2>>x1>>x2>>t0;
}
Did you sell your brain for 50 penny 50Penny?
Can anyone tell why my code gives TLE. According to me its complexity should be nlogn which is within the time limits. I use suffix arrays to calculate all suffixes that are also prefixes and store them in array. this is nlogn+nlogn = O(nlogn) Then I use binary search on this array to get the string. For string comparison in binary search i use KMP. again this is O(nlogn) It gives TLE on TC 26. here's a link to my code link.
You should try z-function, it is very easy and effective. I understood KMP for the first time and now i think it takes me 15min to understand again. :v
Seems that people like me are coming back to Password for z-function after contest #726
Let me share my z-function solution for div2 D. div1 B. https://codeforces.com/contest/126/submission/120114668
problem e is trash.
Can somebody tell me why this is TLE : https://codeforces.com/contest/126/submission/252494278
I have the exact same solution in C++ and it passes : https://codeforces.com/contest/126/submission/252154602
Is python inherently slower for this or am I doing something wrong?