


Thanks to all the participants for successful submissions!
This set has been prepared by Romka, Chmel_Tolstiy and Ixanezis. Special thanks to Gassa for his help in the preparation of statements and analysis.
Problem А. Orthography
The task has rather small constraints, so that it can be solved easily in O(N2L) complexity, where N is the number of words in the set and L is the length of a word.
In order to achieve such complexity, it is enough to check what happens if we choose each word as ''correct'' (a word with no errors). So, for each word in the set, we iterate over the set of words again and calculate the number of positions in which our chosen word differs from each other word. If all the numbers do not exceed 1, the chosen word perfectly suits us as being ''correct''.
There also exists a better solution in O(NL) complexity, but it was not necessary to apply it here.
Problem B. Voice Alerts
For each recorded phrase, we can calculate the corresponding distance Di using the formula Di = Xi + V·(ti + Tphrase). Then we must find the minimal Di and its index (also minimal with such distance in case of multiple answers).
Problem C. Table Tennis Tournament
To solve this problem, the following observation is necessary. The problem statement implies that the participants scored 2·N - 2, 2·N - 3, ..., N - 1 points. And it follows that the winner won all matches, the runner-up won all matches except the match against the winner, and so on. The participant who took the last place lost all matches.
If we fix the order of participants in the tournament results, we can find the probability of such final outcome. For this, just multiply the necessary probabilities from the probability matrix pij. To generate all permutations, you can use the method std::next_permutation (C++) or, for example, implement a recursive search.
The original problem can be solved with the described algorithm in time O(n2·n!). Using the ideas of dynamic programming, this approach can be sped up, and one can obtain an algorithm running in O(n·2n).
Problem D. Numeric Compression
Let us solve the problem using dynamic programming. For this problem, there are several different approaches, we will describe only one of them.
Note that the number of bit sequences of length L with K alternating groups of bits starting with a group with a zero bit are exactly C(L - 1, K - 1). Indeed, each of the groups is not empty, and among L - 1 of the boundaries between adjacent elements of a bit sequence, we need to choose K - 1 (which will separate the adjacent groups with different bits).
Consider the function F(L, K): the sum of bit compression results of all numerical sequences of length L with K alternating groups of bits (as we already know, there are C(L - 1, K - 1) such sequences).
To compute the value F(L, K) one can use the following approach. Iterate the size of the right group t (the lowest binary digit of the compression result). It is easy to obtain the following relationship:
F(L, K) = sum(t = 1..L - 1) 2·F(L - t, K - 1) + is_even(K)·C(L - t - 1, K - 2) for L > 1; for the base case, F(1, K) = 0.
For the solution of the original problem, find the sum of the numerical compression results for all numbers X smaller than N + 1. All these numbers can be divided into several groups. Let the group Gi consist of all the numbers X such that the highest bit where it differs from N + 1 is at position i. Note that this automatically implies that i-th bit of X is equal to 0, and i-th bit of N + 1 is equal to 1. To calculate the result of summing the numbers from one group, we will use the results of numerical compression of the prefix of N + 1 up to position i and the function F(L, K).
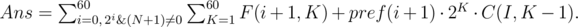
The function 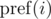 calculates the result of compression for the prefix of the number N + 1, but if the last group contains bit 0, it is excluded from the sum. We consciously included this group in F(L, K).
calculates the result of compression for the prefix of the number N + 1, but if the last group contains bit 0, it is excluded from the sum. We consciously included this group in F(L, K).
The solution described above has complexity 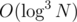 , but you can speed it up to
, but you can speed it up to 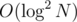 . Maybe even faster?
. Maybe even faster?
Problem E. Bicycle Construction
Let us notice that condition of 4-gears set satisfiability can be rewritten as follows: we can complete a bike using given 4 gears if and only if we can split them into pairs such that products of diameters in each pair are equal.
For each gear diameter D, we can calculate the number of gears with this diameter CD, and for each possible P, we can calculate number CntP of pairs of gears that give us product of diameters P. It can be done in O(N2) time using HashMap / unordered_map or similar container, or in 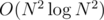 time with help of Quicksort or other sorting algorithm that is fast enough. Now let us consider all pairs of gears. For each pair with diameters D1 and D2 with product P = D1·D2, we can increase answer by CntP - 1, thinking of it as of ``the number of other pairs with such product of diameters''. Unfortunately, it is possible that we added some pairs which included one of the gears we are currently considering. In order to prevent this, we need to decrease the answer by CD1 + CD2 - 2 if current gears have different diameters, and by (CD1 - 2)·2 if they are equal.
time with help of Quicksort or other sorting algorithm that is fast enough. Now let us consider all pairs of gears. For each pair with diameters D1 and D2 with product P = D1·D2, we can increase answer by CntP - 1, thinking of it as of ``the number of other pairs with such product of diameters''. Unfortunately, it is possible that we added some pairs which included one of the gears we are currently considering. In order to prevent this, we need to decrease the answer by CD1 + CD2 - 2 if current gears have different diameters, and by (CD1 - 2)·2 if they are equal.
Now we had taken into account all needed 4-gears sets, but each of them was considered several times. It's easy to notice that every set of the form D D D D (4 gears with equal diameters) is considered 6 times, every set of form D E D E is considered 4 times and every set of form D E F G or D E E F is considered 2 times. Thus, to obtain the final answer, we need to decrease our answer by 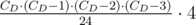 for each gear diameter D, then decrease it by CD·(CD - 1)·CE·(CE - 1)·2 for each pair of different diameters D E, and finally divide the answer by 2.
for each gear diameter D, then decrease it by CD·(CD - 1)·CE·(CE - 1)·2 for each pair of different diameters D E, and finally divide the answer by 2.
Problem F. Radars
First, let us consider the case when we have a single control point. This is trivial: the easiest way is to place the radar into the same point as the single control point. We get efficiency of exactly 1 in such case.
Now let us consider a case when we have two or more control points. Suppose we have found an answer: radar placement with maximum total efficiency. After that, we can move the radar around such point until at least two control points are at integer distances from the radar. Further movement in any direction, which leads some of these points to cross the integer border of that radius around the radar, does not increase the total efficiency (otherwise, our initial assumption about the initial optimal placement is incorrect).
So we will try to find precisely such radar placement that at least two control points lie at an integer distance from it. In order to achieve it, let us iterate over all pairs of control points and over distances r1 and r2, which are the distances from these points to the radar. Eventually, we will find points on the plane for the radar itself: these are the points of circle intersections with radii r1 and r2 and with centers in chosen control points.
We can have numerous such points:
- 0, if circles do not intersect at all,
- 1, if circles touch each other (including the inner touching case),
- 2, if circles intersect.
For each of the circles' intersection points, we calculate the total radar efficiency by definition, and choose the global maximum of all such placements.
The final algorithm complexity is O(N3·R2) where N is the number of control points and R is the maximum considered radius. Considering that points are located in a square with coordinates from 0 to 50, the highest total distance that makes sense to examine is 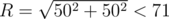 .
.
P.S. If you find a typo, let me know with a private message.







Can someone enlighten me why this code for E gets TLE? I have also tried with storing the diameter as a pair of integers but it didn't work, either.
Maybe it's because unordered_map is too slow. I was able to get AC (not TLE 26) only when I got rid of it.
Would you mind sharing your AC code? I did try to use map but it doesn't help.
I used approach, that differs from yours.
Here is my AC code. It uses sorting, but doesn't use maps at all
Try this test: http://codeforces.com/contest/673/submission/18055039 On Yandex system it is working 6.26s
Try reserving some space in the map upfront. If it grows up to O(n2), where n ≤ 4000, it's a lot of rehashing.
Thanks a lot! After reserving n2 buckets for the unordered_map, it takes 3.6s for the maximum test case.
Hi! Can you explain what "reserving some space in the map upfront" mean? How do I do that?
Use methods reserve or rehash
O(NL) solution for A anyone ?
To solve this in O(NL), you maintain a freq[L][26], Here freq[i][j] stores the frequency of the ('A'+j)th character at the i-th position in the string. This frequency can be computed in O(NL). after that iterate the freq[][] array, and for each i, pick the maximum j, and use ('A'+j) as the i-th character.
I hope this solves it.
Let's find for each position the letter which appears on it in more than half of words, if none — every letter is ok. It is standart problem which can be solved in O(n) time for each position. Now I state that our word can differ from the right one no more than in one position. We can check the word in O(nL) time. If it is OK — great, problem solved. If it isn't then there is a word which differs from our in more than one position. We can change no more than one letter in our word, so that word differs in exactly two positions. Let's change letters in both positions and check these variants. Overall complexity is O(nL).
Code
Hey, I missed the contest, is there any link where I can see the problem set for this round ?
You can register here : https://contest.yandex.com/algorithm2016/contest/2498/enter/ And then start a virtual contest on the yandex site.
Can someone help me out with the O(n * 2^n) solution for Table Tennis Match, i.e. Problem C.