


If you notice typos or errors, please send a private message.
Author: cdkrot
Developer: ch_egor
You just needed to implement the actions described in statement.
If you solution failed, then you probably forgot to use 64-bit integers or made some small mistake.
Correct solution:
Div2B Little Robber Girl's Zoo
Author: ch_egor
Developer: ch_egor
We need to sort an array with strange operations — namely, to swap elements with even and odd indices in subarray of even length. Note that we can change the 2 neighboring elements, simply doing our exchange action for subarray of length 2 containing these elements. Also, note that n ≤ 100, and it is permission to do 20 000 actions, therefore, we can write any quadratic sort, which changes the neighboring elements in each iteration (bubble sort for example).
Complexity O(n2)
Bonus: Is anyone able to search the shortest solution of this problem? If yes, what complexity?
Div2C Robbers' watch/Div1A Robbers' watch
Author: cdkrot
Developer: themikemikovi4
In this problem we use the septimal number system. It is a very important limitation. Let's count how many digits are showed on the watch display and call it cnt. If cnt more than 7, the answer is clearly 0 (because of pigeonhole principle). If cnt is not greater than 7, then you can just bruteforces all cases.
Depending on the implementation it will be O(BASE BASEBASE), O(BASEBASE) or O(BASE BASE!), where BASE = 7. Actually the most simple implementation is just to cycle between all posible hour:minute combinations and check them.
In the worst case, it will work in O(BASE BASEBASE).
Bonus: Suppose the base is not fixed. Solve a problem with n ≤ 109, m ≤ 109, BASE ≤ 109. Can you do it in 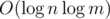 ?
?
Div2D Kay and Snowflake/Div1B Kay and Snowflake
Author: cdkrot
Developers: ch_egor, cdkrot
There are many possible approaches.
Solution by cdkrot:
Look at the all candidates for the centroid of the vertices v subtree. The size of centroid subtree must be at least  of the vertex v subtree size. (If it isn't, then after cutting the upper part will have too big size)
of the vertex v subtree size. (If it isn't, then after cutting the upper part will have too big size)
Choose the vertex with the smallest subtree size satisfying the constraint above. Let's prove, that this vertex is centroid indeed. If it isn't, then after cutting some part will have subtree size greater than of subtree size of query vertex. It isn't upper part (because of constraint above), it is one of our sons. Ouch, it's subtree less than of selected vertex, and it's still greater than of subtree size of query vertex. Contradiction.
So we find a centroid.
We write the euler tour of tree and we will use a 2D segment tree in order to search for a vertex quickly.
Complexity 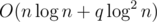
You can consider all answers by one in dfs using this idea. Use std::set for pair (subtree size, vertex number) and at each vertex merge sets obtained from children. (Also known as "merging sets" idea)
Thus we get the answers for all vertex and we need only output answers for queries.
Complexity 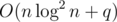
Solution by ch_egor:
Solve it for all subtrees. We can solve the problem for some subtree, after solving the problem for all of it's children. Let's choose the heaviest child. Note that the centroid of the child after a certain lifting goes into our centroid. Let's model the lifting.
Thus we get the answers for all vertex and we need only output answers for queries.
Complexity O(n + q)
Div2E Optimal Point/Div1C Optimal Point
Author: cdkrot
Developer: cdkrot
Let's say few words about ternary search. It works correctly, but too slow.
It's complexity is 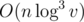 , where n = 105, and v = 1018.
, where n = 105, and v = 1018.
Don't use it.
Solution.
1) Let's make binary search on answer
2) Consider areas of "good" points (with dist ≤ mid) for each source point.
3) Intersect those areas and check for solution.
This area can be decsribed by following inequalities:
(You can achieve them if you expand modules in inequality "manhattan distance <= const")
.. denote some constants.
If you intersect set of such system, you will get system of the same form, so let's learn how to solve such system.
Let's replace some variables:
Then:
Now the system transforms into:
We need to check if the system has solution in integers, also the numbers a, b, c must be of the same parity (have equal remainder after division by 2). (This is required for x, y, z to be integers too)
Let's get rid of parity constraint. Bruteforce the parity of a, b, c (two cases)
Make following replacement: a = 2a' + r, b = 2b' + r, c = 2c' + r, where r = 0 or r = 1. Substitute in equations above, simplify, and gain the same system for a', b', c' without parity constraint.
And now the system can be solved greedy (At first set a, b, c with minimum, and then raise slowly if necessary).
Total complexity is 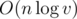 .
.
Bonus. This task can be solved in a lot of modifications, for example euclidian distance instead of manhattan, 2d instead of 3d, floats instead of integers. How to solve this varations?
Authors: platypus179, Endagorion
Developer: platypus179
Let's solve this problem with scanline. Go through all rows from left to right and maintain the array in which in j index we will store the number of points in a square with bottom left coordinate (i, j), where i is current row of scanline.
This takes O(MAXCORD2) time. Note that the set of squares that contain some of the shaded points is not very large, namely — if the point has coordinates (x, y), then the set of left bottom corners of square is defined as {(a, b)|x - k + 1 < = a < = x, y - k + 1 < = b < = y}. Let's consider each point (x, y) as the 2 events:
Add one to the all elements with indexes from y - k + 1 to y on the row x - k + 1 and take one at the same interval on the row x + 1. How to calculate answer? Suppose we update the value of a cell on the row a, and before it was updated the value x on the row b. Let add to the answer for the number of squares containing x points value a - b. We can implement the addition of the segment directly and have O(nk) for processing all the events that fit in time limit. To get rid of O(MAXCORD) memory, we need to write all interested in the coordinates before processing events (them no more than nk) and reduce the coordinates in the events. It takes 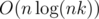 time and O(nk) memory. Now we can execute the previous point in O(nk) memory.
time and O(nk) memory. Now we can execute the previous point in O(nk) memory.
Complexity is 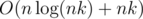 time and O(nk) memory.
time and O(nk) memory.
Bonus: 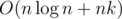 time and O(n) memory.
time and O(n) memory.
Div1E Travelling Through the Snow Queen's Kingdom
Authors: cdkrot, GlebsHP
Developers: ch_egor, cdkrot
Unfortunately, due to my, cdkrot, failure, it was possible to get Ac with O(nm) solution, I apologise for that.
We propose following solution:
Let's solve task with divide & conquer. At first let's lift l to the first index, where s was mentioned And lower the r to the last index, where t was mentioned. This will not affect answers, but will make implementation much more easy.
Let's look on all queries. For each query consider it's location relative to centre of edges array. If it's stricly on the left half or on the right half, then solve recursively (You need to implement function like solve(requests, l, r)).
How to answer on query, if it contains the centre? Let's precalculate two dp's:
dpr[i] = bitset of vertices you can from to the vi or ui with l = m and r = i.
dpl[i] = bitset of vertices you can go to starting from vi or ui with l = i and r = m - 1
vi and ui are vertices of i'th edge.
Using this dp the answer is yes if and ony if dpl[l][u] = true and dpr[r][u] = true for some u.
All above can be implemented using bitwise operations.
So the time is 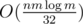






In 685D - Kay and Eternity we can achieve shorter implementation using
setfrom STL. My solution is similar to the one from editorial, but I havesetwith numbers +1 and -1, instead of a segment tree. I use the fact that iterating over set takes O(size), not O(size·log). Check details in my code. To store +1 and -1 sorted by y, I represented +1 by 2y and -1 by 2y + 1. This way, I don't need to store pairs, what would be slightly slower (and maybe it would give TLE).Oh, so O(nm) wasn't intended in 685D - Kay and Eternity. I'm surprised. Constraints and everything looked like it's what organizers wanted. Anyway, it didn't spoil a problem I think (though it made it easier). By the way, did you think that O(nm) won't pass or you didn't come up with this solution?
We want to cut off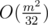 solution. On this limits difference in TL near 3. But we write very unoptimal O(nm) solution and didn't know that it can pass.
solution. On this limits difference in TL near 3. But we write very unoptimal O(nm) solution and didn't know that it can pass.
Just wondering what was the difference in time between main solution and nm solution. Was it really at least 4 times?
It was.
It seems, than nm solution runned too slowly because of cache: my code was iterating over first dim of matrix, and it is not good.
I was making scanline from left to right, and the right to left is better.
Just reversing everything makes it run over second dim of matrix, as in Ac-ed solutions.
I've written it, but it turned out, that implementation wasn't effecient enough.
Actually the most effort was made to cut O(M2 / 32) solution (however it has pretty simple and nice idea beneath it).
It was hard to cut it, and this way I accidently opened door to O(nm) solution.
Can u share idea behind O(M^2 / 32) solution too?
Solution in M2 / 32, for div1.E.
Let's create a matrix of N x M size and create a graph node from each cell.
{We will not use it in final code, but it is important for explanations}
Let's add some edges in this graph:
* (w, i) -> (w, i + 1) for all i, w
* (vi, i) -> (ui, i) for all i
* (ui, i) -> (vi, i) for all i
vi, ui — are endpoints of i-th edge.
How to answer on query L, R, S->T? We just need to check, that there is a path from (S, L) to (T, R)
However N x M table is too big for us, let's shrink it.
Take note, that it is enough to check reachability within (S, L') and (T, R'), where L' — smallest num, with L' ≥ L and (UL' = S or VL' = S) Аnd R' — been the biggest number, with R' ≤ R and (UR' = T or VR' = T)
This way almost all vertexes can be eliminated from graph, they simply will not be used. It is enough to create a new copy of vertex only when it was mentioned in new edge.
Also, we were adding this edges before: (ui, i) <-> (vi, i).
We will compress this two vertexes into one, since the relations of reachability are same for them
After following operation we have acyclic graph with M vertexes and O(M) edges.
We can calculate the following dp on it:
dp[v] — is bitset of reachable vertexes (vertexes of our supplementary graph).
And so complexity is M2 / 32 for both memory and time.
However memory complexity can be boosted (thanks to ch_egor):
You can go with scanline over edges, answering queries in certain places.
Quite often some state of dp will be not used till the end, so it can be destructed to rescue memory for next ones.
My code (but without memory optimization)
ch_egor's code (memory optimization + dirt optimizations like fast io).
Can you explain the O(nm) solution for Div-1 E.
Go with scanline from right to left, and maintain following dp:
dp[i][j] -- if L is current pos of scannline, the smallest R, which makes possible to go from i to j.
While you go with scanline add edges to this dynamics (requires recalculating O(N) values), and answer the queries, when current position of scannline coincides with querie's L.
Why is the complexity of Div1B's second approach O(N * log²(N) + Q)? I know one of the log factors is due to the set usage; but why does the merging step also have O(log(N)) complexity? Shouldn't it be more?
It is a common trick with merging sets.
Let's always merge smaller set into larger, this way when element is merged from one set to another the size of the set in which it lives doubles at least.
Hence each element will not be moved more, than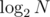 times.
times.
How come it doubles at least? and what do you mean by the set which it "lives" would you clarify more please?
The key idea is following: each elements starts in it's own std::set, and sometimes we ask sets to merge together.
How to merge them? Select smaller set and add all those elements to larger set.
Notice, that each time some element changes set, the set in which it lives grows at least two times (since large set ≥ smaller).
Hence, there can't be more than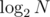 movements per element.
movements per element.
If you need more info, read 600E - Lomsat gelral and it's editorial.
Got it thank you <3
Lol, you considered O(nm) as bruteforce and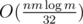 as a model solution :|? Do you know that dividing as 32 in the most typical model of computations is in fact dividing by log :)? And in reality, not in plain theory, isn't that still more or less the same? There is no reason to apologise that O(nm) passed, because I doubt it is possible to make a distinction between those 2 solutions.
as a model solution :|? Do you know that dividing as 32 in the most typical model of computations is in fact dividing by log :)? And in reality, not in plain theory, isn't that still more or less the same? There is no reason to apologise that O(nm) passed, because I doubt it is possible to make a distinction between those 2 solutions.
In Balkan OI 2014, there was a problem with N≤10000 and intended solution was N * log(N) + N2. Author of problem apologized after contest because of there are some AC with N2 + N2.
This is even funnier than it.
Well — even though this is a programming contest, I think that the solution should focus on pure big O complexity.
In this contest the model solution was O(nm log m) -> there is no O((nmlogm)/32) complexity.
In case of Balkan OI the model solution was O(N^2). I don't understand apologizing for letting the solutions with the same or better big O complexity get AC.
Furthermore I would be surprised if the O(nm) or O(N^2) solution didn't AC.
Dividing by 32 can be a nice trick if your big O complexity is worse than the model one and you used that trick to speed up things a bit. That trick should never be required by the model solution.
I hope you may change your mind if you read my comment below.
I find O(stuff / 32) problems pretty dissatisfying in general. I personally don't find it interesting at all that you can speed up a problem by a factor of 32 or 64, and that this often constitutes the "main difficulty" in a problem.
There was a time when I had a similar opinion as yours, but after I realized what this "/32" in fact really is, I think it is perfectly fine.
Do you agree that we should be able to handle "a+b" operation in constant time? If we won't, because a and b binary notations are of logarithmic length, hence this operation requires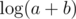 operations then in 99% of problems we should put additional
operations then in 99% of problems we should put additional 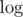 into complexity, because summed length of bits sequences we are dealing with is (previous complexity)
into complexity, because summed length of bits sequences we are dealing with is (previous complexity) 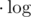 . It would be rather inconvenient to put additional
. It would be rather inconvenient to put additional 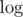 into complexities almost everywhere, because of arithmetic operations. Moreover that suits practical model, because as long as we are dealing with numbers from not very large range we perform arithmetic operations on bits sequences not longer than 64 as fast as we perform operations on shorter sequences and only reasonable way of extending that arrangement to arbitrarily large integers is to assume that we are able to perform operations on bits sequences of length
into complexities almost everywhere, because of arithmetic operations. Moreover that suits practical model, because as long as we are dealing with numbers from not very large range we perform arithmetic operations on bits sequences not longer than 64 as fast as we perform operations on shorter sequences and only reasonable way of extending that arrangement to arbitrarily large integers is to assume that we are able to perform operations on bits sequences of length 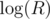 in constant time (where R is range of numbers on input). Either we accept it as a fact that we are able to do this or we demand adding two numbers to take logarithmic time. There is no way to "ban cheating with dividing by 32" and have constant time addition. Thus, consequence of having addition in constant time is being able to perform operations on bits sequence of logarithmic length in constant time, because constant time addition is same kind of cheat as ability to xor sequences of length k in k/log k time. That enables you to sometimes perform operations on data of O(n) size in
in constant time (where R is range of numbers on input). Either we accept it as a fact that we are able to do this or we demand adding two numbers to take logarithmic time. There is no way to "ban cheating with dividing by 32" and have constant time addition. Thus, consequence of having addition in constant time is being able to perform operations on bits sequence of logarithmic length in constant time, because constant time addition is same kind of cheat as ability to xor sequences of length k in k/log k time. That enables you to sometimes perform operations on data of O(n) size in 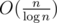 time which is for example a state of an art algorithm for transitive closure.
time which is for example a state of an art algorithm for transitive closure.
tl;dr dividing by 32 is not optimization by a constant factor, it is optimization by a logarithmic factor Because of that I definitely don't consider such solutions as dirty tricks.
ok ok I had something here but then I understood what you're saying. That's reasonable. Further question: what do you think about the following problem that I might use on a future contest. You have 105 integers, each of size ≤ 1010000. Find their sum and print it out.
(ok the future contest part is a joke)
Hm, yeah, I guess you didn't get my point :P. We are considering theoretical model. Do you want to multiply complexity of 99% of your solutions (those requiring any arithmetic operations) by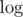 factor coming from arithmetic operations? I guess no. If we stick to computations performed on a modern computer, following your reasoning, why do you write that algorithm of adding n numbers not larger than R is O(n), but not
factor coming from arithmetic operations? I guess no. If we stick to computations performed on a modern computer, following your reasoning, why do you write that algorithm of adding n numbers not larger than R is O(n), but not 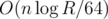 ? Bits notations of such numbers are of length
? Bits notations of such numbers are of length 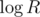 and you are not able to shave off log factor, just 64 one. You may didn't realize this, but model when we are able to perform whole
and you are not able to shave off log factor, just 64 one. You may didn't realize this, but model when we are able to perform whole 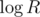 factor is exactly the model whole CF community communicates within. If you accept algorithm of adding n numbers from range R to be O(n) then you also accept
factor is exactly the model whole CF community communicates within. If you accept algorithm of adding n numbers from range R to be O(n) then you also accept 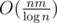 algorithm to transitive closure.
algorithm to transitive closure. 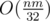 algorithm is in fact a better complexity, because it translates to
algorithm is in fact a better complexity, because it translates to 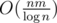 in a theoretical model and fact that we need replace that log with 32 is only a technical barrier. I have a feeling that I am saying the same statements over and over and can't explain it much better :).
in a theoretical model and fact that we need replace that log with 32 is only a technical barrier. I have a feeling that I am saying the same statements over and over and can't explain it much better :).
EDIT: Oh, I see you changed your comment while I was writing this :).
EDIT2: Regarding to your further question. I have to admit that I am not fully sure whether R I used so far should denote range of numbers we are dealing with. Maybe it should denote length of input or sth, but I am not sure right now.
Oh, for transitive closure, you can do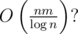 This is really surprising to me, as I thought the best savings you get in all cases is 64 or something (for all problems of this type).
This is really surprising to me, as I thought the best savings you get in all cases is 64 or something (for all problems of this type).
Same here. I was just scan-reading the tutorial for a hint and the first thing I see is to iterate all n and m. I got an AC for iterating through all value of n and m, and I didn't even store the representation of values <m. Pretty sure this is not a worthy solution.
*whoops, wrong topic.
can anyone plz explain the duv2D 3rd solution by ch_egor, what does big_subtree[] stand for and what is dfs_centroid calculating
The idea is that say the node u has more than one child and heaviest one is v, and say the centroid of v is vc, then the centroid of u will be on the way from vc towards the root. For leaf nodes, centroid are themselves, and for others, consider the lifting model, thus complexity being O(n) only.
Hi, Can u plz explain this->"heaviest one is v, and say the centroid of v is vc, then the centroid of u will be on the way from vc towards the root". Thanks.
Correct me if I'm wrong, but is the centroid of u either itself or vc? And is that why the complexity is O(n)? Thanks in advance.
You are wrong. The centroid is either u or some vertex beetween u and vc.
The amortized complexity is O(n). Think of it like, at every node, we do some lifting, lifting from centroid of big subtree (vc) to some nodes up (nvc : which will be the new centroid) . Now let's say you lift vc up to node nvc. Let's say the path is vc, parent[vc], parent[parent[vc]], ..... nvc.
You will notice that for all nodes, these paths are disjoint. So this extra loop inside every node for lifting will be O(n) for all nodes combined.
I used almost similar idea, but instead of lifting up, I was trying to lift down. I start from the top of the tree, and find centroid for each node. For a node u, if it's parent's centroid c is in u's subtree, I try to lift down from c until I find the centroid, if c is not in u's subtree, I start searching from u node itself. The logic behind this is if u is the heavy child of it's parent, it must have it's parent's centroid in it's subtree, thus avoiding some steps and jumping directly to the centroid node for search. If u is not the heavy node, it's subtree is being explored for the first time, so it's not repeating. I got tle in 14th test case, can someone kindly point out my mistake here?
http://codeforces.com/contest/685/submission/18730022
Your mistake here.
You check every vertex in O(deg(c)). 14th test looks like bamboo with tall and sunshine with size
and sunshine with size  . The main vertex of sunshine is centroid of
. The main vertex of sunshine is centroid of  subtrees, because this your code works in
subtrees, because this your code works in 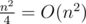 .
.
While I drew diagrams and wrote equations for subtree sizes for certain cases to prove ch_egor's solution in the middle of the contest (and it passed :D), could someone give me a general, more formal proof for it?
consider vertex u, let v be the maxSize Child of u, let w be centroid of v, go along path from w to u, there are 2 case 1. size(v)<=size(u)/2, u itself is centroid of u. 2. size(v)>size(u)/2, along the path from w to v, the first vertex x satisfying the condition (size(x)>=size(u)/2) is centroid of u, such x must exist as x=v satisfy the condition. let prove case 2, x must be a centroid of u. if x=w, obviously true; if x!=w, let y be the preceding vectex of x along the path(y is a child of x), there are 3 types of components, 1.subtree(u) — subtree(x), obviously ok as sizeof(x)>=size(u)/2. 2.subtree(y), ok because size(y)<size(u)/2, otherwise the first vertex satisfying the condition will be y or some preceding vertex instead of x. 3.subtree(z) (z != y && z is a child of x), size(z) < size(v) — size(w) <= size(v)/2 < size(u)/2, ok
hello friends i wrote a coded up the div2 c problem and it is giving wrong answer on only two test cases(and possibly more not included in the test case file) could someone plz check what is wrong with the code it's simple recursion, here is the link code: http://codeforces.com/contest/685/submission/18694520. As you could clearly see in the code i cheated(of course i couldn't get it to submit during contest)...so plz help!!! i would be really grateful if someone could tell me what is wrong with the solution.
It is curious because I compiled and ran your code locally removing the "cheating part" it works perfectly well in the two problematic test cases but if we check it on the server of codeforces it gives WA.
I see now, the problem is with the function pow. It is defined for doubles and you are using for ints. Small roundoff errors give you trouble. It is better to implement your own powq function as in
Then it works properly
can the centroid for a vertex lie above a vertex v if yes then how (are we then considering the whole tree or just the subtree of a vertex) and how can we prove this model.
The centroid of subtree at vertex v must be one of its children. Have a look at the problem statement ;)
Div1 C is a harder version of GCJ 2008 R2 Problem C — Star Wars: https://code.google.com/codejam/contest/32001/dashboard#s=a&a=2
An other solution for Div2 D/Div1 B: The algorithm for finding the centroid of a general tree is the following: If we are currently at node u and we are looking for the centroid, we find a child v of u with size[v] > N/2 and continue our search for the centroid from v. Now let us for every node u create a path containing all the nodes we have selected with this process. We have just done Heavy-Light decomposition to our tree, and every path we have created is a heavy path. So, when we want to find the centroid of the tree rooted at a node r, we can find it with a simple binary search in the heavy path which contains r. (Solving the problem with this method doesn't require knowledge of Heavy-Light Decomposition though) Code
Nice! Got accepted using your approach, thanks bro.
You are welcome :)
Can anyone please shed light on below line of code from Problem C editorial solution? How is this checking for unique combinations?
used[v] = how much times this digit occured.
If all digits occured no more than once, than this time all digits were distinct.
max_element(used.begin(),used.end()) returns the iterator to the maximum element . We are checking if the value of the maximum element <= 1 . If there are any repetition the value of the maximum element >=2 else there are no repetition .
How can Div2C be solved when Base( <= 10^9 ) is not fixed ?
Hint: solve in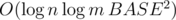 first.
first.
Hey, i could think of a dp solution. Not so sure about complexity. Please check it 18702275
Your complexity looks like O(BASE2 2BASE).
I am still confused about the complexity part ! But at least now, can you share how to solve it in O(logN * logM) ?
I can share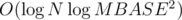 solution, I see ways to boost it (Drop base2 from complexity in trade of to more
solution, I see ways to boost it (Drop base2 from complexity in trade of to more  's), still i don't want to implement this.
's), still i don't want to implement this.
The basic idea is that you bruteforce the common prefix of max hour and target, and same for minutes.
When you fixed common prefix and first digit after it you just use combinatorics formula.
P.S. This code can be used with different bases, however some things might be needed to adjust, e.g to avoid overflows.
Tanks for answer, I'm so busy these days.
Thank you. Both ! Maintain this generosity even when you're red :) And i like coordination between you two !
thank you :)
In DIV2D, "We write the euler tour of tree and we will use a 2D segment tree in order to search for a vertex quickly. ". How to do a query? Also please tell the properties of euler tour too.
Write the euler tour of tree, subtree of vi now takes some contigious segment of the tour.
Select from this segment minimum number greater or equal to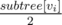 , why this works is explained in editorial.
, why this works is explained in editorial.
So you want to perform queries with three params: L, R, C — you can do this with 2d segment tree.
After we do the euler tour, each subtree becomes a subarray, right? Are they also ordered by some property like increasing subtree sizes? Or random?
If they are random, I don't understand how we could use a 2D segment tree to find a number greater than X/2 in some subarray. Please give more details :)
Each subtree becomes an subarray, yes. You should write to the array the subtree sizes of vertexes.
Yes, numbers are not sorted within given subarray, so 2d tree come to help.
You can create segment tree, where each node contains sorted array of values of all leaves it contains. It can be done in time. Note, than each element lives in
time. Note, than each element lives in  elements, so this is why it is
elements, so this is why it is  , not more.
, not more.
Using this segment tree is easy: you split your request to list of nodes as usual, and in each node you make a binary search.
Thanks, that clears it up. Will try to implement it!
I got AC using this idea, thanks! Can you explain the second approach in a little more detail? What is "merging sets" idea?
It is a common idea.
Checkout this problem 600E - Lomsat gelral and this editorial for it.
In each node of segment tree, are we storing a sorted array of that range and then using binary search to search for the value just greater than (subtree_size/2) ? If yes, then won't the cost of constructing such segment tree be O(n^{2}) ?
Do you know that merging two sorted arrays into one new can be done in O(len_of_first + len_of_second)? It is a key idea to know, may be you have encountered it before in mergesort algorithm. It is also implemented in c++ as std::merge.
How to construct such tree? Construct it recursively: at first construct child nodes with same constructing function, and then merge sorted arrays of left and right nodes into array of this node.
Why this is O(N log N)? Your recursion will have O(log) levels of recursion, and you will have O(N) work done on each level (it is same as in merge sort).
Thanks @cdkrot, I calculated the complexity in a wrong way and that's why was confused.
Can anyone tell me that how can I reduce complexity of my code for Div2D? I am not quite sure what's the complexity here :( Thnx in advance.
My code: http://pastebin.com/HJNpnwyq
If I am not mistaken, you firstly check a node's heaviest child whether it is the centroid. If not, then you go down on the tree until you find it. However, it is not what is told in the tutorial and has a complexity of O(N^2). To make it correct, initialize your par variable with the centroid of your heaviest child and climb the tree upward by going to one's dad in each step. Please let me know if you need any further explaination :)
Can anyone please explain the Div2 C. Robbers' watch problem. I am not able to understand the problem statement clearly and how is the pigeonhole principle appyling in the solution. Please help. Thanks in advance.
(Refer the problem statement for terminology) Suppose there are h places for display in hour section and m places for minute section. Now, problem says that all digits in hour and minute section taken together should be distinct. Since, its septimal number system, so possible digits are 0,1,2,3,4,5,6, i.e. 7 distinct digits. So, if sum of places in hour and minute section is greater than 7 then it is impossible that all the digits are distinct because we have 7 digits available and places are more than 7.So, the answer should be zero in that case. This logic is formally called pigeonhole principle.
For cases when total available places in hour and minute section are less than or equal to 7, we apply brute force approach. that is we take every possible value for hour(0 to n-1) and minute (0 to m-1), then convert them to base 7 and see if all digits are distinct are not. For this you can use an array for digits 0 to 6 and track the count of every digit while converting hour and minute to base 7. If any digit's count is greater than 1, then that combination of hour and minute is rejected.
Hi, thanks for the explanation, I have understood the problem and Pigeonhole principle and although one thing still confusing me is that->
why do we need to track the count of every digit while converting to base 7, I mean why combination is rejected if the digit count exceeds 1. I know maybe I am asking very basic question. Sorry for inconvenience :)
Because the problem asks to find all those possible combination of hour and minute such that no digit appears more than once in the whole clock display. For eg, 02:23 (hr:min format) is not allowed since 2 appears more than once.
Oh yes my bad, that was really easy :P
Anyways Thank you very much for your help :)
I'm wondering how to solve div2/B if we have to minimize the number of operations ?
In DIV-2 D/DIV-1 B , the last solution taking
O(n+q)time complexity to solve uses the line "Note that the centroid of the child after a certain lifting goes into our centroid. Let's model the lifting. ", for explanation which I am not able to understand, could someone please explain what is the lifting operation mentioned here and how is it helping ?I'll copy paste my explanation, ask more if you need anything: Of course, the centroid of the leaf is the leaf itself.
What about the node?
Let's find the size of every subtree.
If for every node's child it's (child) subtree size <= size(node) / 2 than the node is the centroid.
If not, then centroid of node is the children's centroid. It only fails one kind of test — where the path from the node to the centroid is longer than size(node)/2, then we have to find a node that is an ancestor(parent or parent's parent etc) of the centroid, that will be good for our node.
The node has to be on the path from the centroid to our node. Why? Let's try a node that's below the centroid — then the size of our component is even bigger.
So let's take another node that is above our centroid but not on the path between them. Then we have a component of size at least n/2, because if it wasn't, then we would've had another centroid computed for our son by that time. Try to draw a picture and it should be intuitive why it's that way.
Thanks for the reply, consider this example https://postimg.org/image/9v9wg9idt/ the centroid of the node (u) passes the test you mentioned bcoz it is at length 3 which is less than size(node)/2 but we will still need to find some ancestor as it is not the centroid of node (u) , but I think one way to quickly check if centroid of one of the child is centroid of the node as well is by checking the weight of centroid, it the weight of centroid is x then weight of the remaining part after removing it would be weight(node)-x-1, we can verify both the values and if they don't satisfy, we can look forward for ancestors. Also for the case in image the centroid of the node (u) would be v which is along the path from node to centroid, but still the centroid. Thanks again .
In our case v subtree is bigger than half of u subtree size, so v centroid is our candidate. We have to check if v is centroid of u, so check the length of the path between u and v, it is 1, which is less than size of u subtree, thus v is u centroid. If length of path from u to v was longer than u subtree size then you would have to iterate through v ancestors. Sorry for mistakes, writing on mobile
"So let's take another node that is above our centroid but not on the path between them. Then we have a component of size at least n/2, because if it wasn't, then we would've had another centroid computed for our son by that time. Try to draw a picture and it should be intuitive why it's that way." — This is the part that I cannot understand. Could you elaborate a little bit more? I'm sorry to pester you.
Sure, no problem! Imagine we're in vertex u, that has the child of size bigger than size(u)/2, let's name this child's as w and it's centroid as v. If v != w then we know, that v is in w subtree with size bigger than size(v)/2. Let's take vertex z that is not on the path between v and w and assume it's u centroid. Then there has to be a vertex c on that path that has both v and z as children in different subtrees (maybe not direct), but if v is w centroid, then it also has to be c centroid, so c subtree with v in it is bigger than size(c) > 2, so z cannot be a c centroid. Moreover, it cannot be u centroid. So we have a contradiction.
It isn't beautifully written, I can't really put it into words, if you have any more questions feel free to PM me
Perfect!! 4 years old comment still helps!!. Thanks Mucosolvan
My code18714720
Your code's complexity is O(NQ), since you run dfs for each query.
You should write something more effiecient, reread the editorial.
P.S. It is old century to store graph in hand written lists, most people now use
It's just more simple to write.
Can someone explain what std::move does in div 2 D solution with merging sets? How would this solution work without it?
In that particular code explicit std::move does nothing. I'd say it even makes things worse as it blocks potential Return Value Optimizations.
However, move semantics (which are triggered on return anyway without explicit std::move) allow not to copy the set on return, but move it cheaply — something like returning a pointer, but more convenient.
Can someone explain how the time-complexity is O(n+q) in Div2D Kay and Snowflake third approach. I am unable to understand O(n) part due to the below code. I think in worst case, it will take steps equivalent to its height thus making complexity > O(n).
while (!is_centroid_of_subtree(v, c)) { c = prev_of[c]; }
Consider each edge. It has upper and lower ends. Lifting can be done only from lower to upper, and due to the DFS nature of solution it happens no more than once per edge.
And num of edges is O(N) (N - 1 to be precise).
For Div1 D, can someone explain this in more detail from the editorial : "
Suppose we update the value of a cell on the row a, and before it was updated the value x on the row b. Let add to the answer for the number of squares containing x points value a - b."Hello, I have tried solving Div2 D/ Div1 B by selecting a child vertex which has subtree size > (1/2)*total_subtree_size of that node, but I am getting wrong answer on 3rd testcase. Can someone please point out what am I doing wrong ?
Submission
subtree size should be >= not > than half of total_subtree_size. btw floor division's also a problem. look out for that one.
can anyone explain what " lifting " means in div2D editorial?
In this approache we choose centroid of the heaviest child. Then we are lifting it while considered vertex is not a centroid of subtree. In this case it means that we look at vertex if it is centroid of subtree do nothing else we look at parent of vertex. If parent of vertex is centroid do nothing else look at parent of parent... Do this while considered vertex is not centroid of subtree.
What is "manhattan distance <= const" equation? Wouldn't that be |x2 - x1| + |y1 - y1| + |z2 - z1| ≤ const ?
Yes it is. One of (x_1, y_1, z_1), (x_2, y_2, z_2) is target point you are trying to find, and the other is source point given in test.
Const is equal to mid value from binary search.
What is
vin 686E - Optimal Point and what doesv = 10 * * 18mean? Thank you.v means bounds of coordinate. 10 * * 18 is mistake, it means 1018. I fixed it now.
Could anyone explain how do we do binary search in 686E - Optimal Point?
Consider boolean function f(L) -- is there a point, which makes answer not worse, than L?
We are searching for lowest x, such that f(x) = 1. Using binary search.
Why do you add +1 when calculation first of a',b',c' in "tr.c.first = DIV2(tr.c.first — r + 1);" ??
Also in get_solution can you explain the final calculation part using delta ?? Couldnt get the logic .. Seems mathematical
Because we need to round in different ways. In one case we want to round down ("floor"), and in other case up ("ceil")
Let me explain using example. Consider following inequality, solve in integers.
Since x is integer, we transform:
And ceil operation can be written as floor operation:
Also take note, that we don't divide using divide operator, it rounds toward zero, which is not good for us.
ok ! Also explain the final point calculation using delta
At first we make some comparisons, to make sure, that solution exists.
After that we generate one of solutions. At first we take a, b, c at their minimum. However their sum can be too small, in this case we want it to be raised to minimum S.
So we calculate delta -- how much we need to raise, and then we raise in such manner, that a, b, c will never be more, than maximum.
Thanks a lot mate ! Got it Accepted !
One last thing : That div2 function will make difference when dividing by 2 and taking floor of negative nos. right ?
As -3/2 = -1 but div2(-3) = -2
Yes, exactly. Div2 func always rounds down. Which matters for negative odds.
How do we count f(x)?
Mentioned function is simple boolean function -- have we such point or not?
I believe, that this function is explained in editorial thoroughly. Try reading it again.
If it will not help -- send me a PM.
In cdkrot code.... Is "std :: merge" working in the way smaller one attach to larger one? (O(logN))? I mean, std::merge(sm.begin(), sm.end(), big.begin(), big.end(), vec.begin(), vec.begin()) --> this will be sm---(attach)-->big and copied to vec?
And I think copying time is somewhat costly isn't it?
There are two solutions by me for centroids problem.
One uses 2d segment tree, and other uses merging sets.
std::merge is used in 2d segment tree solution, if you want merging sets solution, check the other code. (it contains the word "set" in the code).
Thanks for comment in person. After read all of solutions carefully for Div2-D, O(n+q) solution was what I really want. One of my goal was to solve like this kind of problem(which requires some sense and proof). But when solving problem D of any Div2, I failed 50% of them (like in this case...) The common point of failing (I think) is not how to prove but how to come up with "idea" (In this case, centroid of u must be on the line of centroid of v to u, v is child of u who makes sub[v]*2>=sub[u]). Could you give me any advice for accessing this kind of problems or training this kind?
Don't know, really.
May be you need to get more experience -- then write more contests. May be you need theory. May be something else...
If you have opportunity to ask coach for help, than you should do it.
In Div 2 E (Optimal Point), the editorial says:-
2) Consider areas of "good" points (with dist ≤ mid) for each source point.What is mid here?
If you know what binary search is, it should be obvious.
If you don't know what binary search is, then you should learn it.
So what are L and R here?
Do you know what the binary search is?
Yes.
I apologize for bothering you. I was a bit confused by the editorial. After reading this editorial for a similar problem, I now understand the solution.
Not a problem, feel free to ask.
Can someone explain how to solve div2/E (Optimal point) with ternary search?
Thanks.
Can someone explain how to solve Div 1 A in O(log n log m)